Существует две методики прогнозирования цен акций:
- Фундаментальный анализ — в этом случае аналитики оценивают информацию, которая больше относится к компании, чьи акции торгуются на бирже, нежели к самим акциям. Решения о тех или иных действиях на рынке принимаются на основе анализа предыдущей деятельности компании, прогнозах выручки и прибыли и так далее.
- Технический анализ — в данном случае рассматривается поведение цены акций и выявляются его разнообразные паттерны (используется анализ временных рядов).
В случае применения методов машинного обучения для обработки торговых данных, чаще используют именно метод технического анализа — цель заключается в том, чтобы понять, может ли алгоритм точно определять паттерны поведения акции во времени. Тем не менее, машинное обучение может использоваться также для оценки и прогнозирования результатов деятельности компании для дальнейшего использования при фундаментальном анализе. В конечном итоге, наиболее эффективным методом автоматизированного предсказания цены акций и генерирования инвестиционных рекомендаций является гибридный подход, сочетающий в себе подходы фундаментального и технического анализа.
Гипотеза эффективного рынка
Гипотеза эффективного рынка (Efficient Market Hypothesis, EMH) предполагает, что вся существенная информация немедленно и в полной мере отражается на рыночной курсовой стоимости ценных бумаг. Существует три формы рыночной эффективности: слабая, средняя и сильная. Слабая форма подразумевает, что стоимость рыночного актива полностью отражает прошлую информацию, а сильная — что стоимость отражает всю информацию, как прошлую, так и публичную или внутреннюю.
Гипотеза случайного блуждания
Математическая модель случайного блуждания (Random Walk Hypothesis) предполагает, что изменения цены акций на каждом шаге не зависит от предыдущих и от времени. Таким образом невозможно выявить никакие паттерны поведения цены и использовать их.
Функции индикаторов
Для технического анализа рыночных цен используются различные атрибуты и индикаторы. К последним относятся, к примеру,:
- Скользящие средние (Moving Average, MA) — отображают средние n прошлых значений до текущего момента;
- Экспоненциальная скользящая средняя (Exponential Moving Average, EMA) — придает больше веса наиболее недавным значениям, но не отбрасывает старые значения полностью;
- Моментум или скорость изменения (Rate of Change, RoC) — один из самых простых технических индикаторов, рассчитываемый как отношение или разница между текущей ценой и ценой n периодов назад.
- Индекс относительной силы (Relative Strength Index, RSI) — определяет силу тренда и вероятность его смены в течение определенного времени (обычно, 9-14 дней).
Для описываемого проекта в качестве главного индикатора был выбран EMA — он позволяет обрабатывать практически неограниченный объём исторических данных, что очень важно для анализа с помощью временных рядов. Однако стоит заметить, что использование других индикаторов может приносить и большую точность прогнозов анализируемых акций.
EMA (t) = EMA (t-1) + alpha * (Price (t) - EMA (t-1))
где, alpha = 2/ (N+1), таким образом, for N=9, alpha = 0.20
В теории, проблема предсказания цены акции может быть рассмотрена, как оценка функции F во времени T на основе предыдущих значений F во время t-1,t-2 … t-n, присваивая соответствующую весовую фукнцию w на в каждый момент F:
F (t) = w1*F (t-1) + w2*F (t-2) + … + w*F (t-n)
График ниже показывает, как EMA моделирует текущую цену акций:
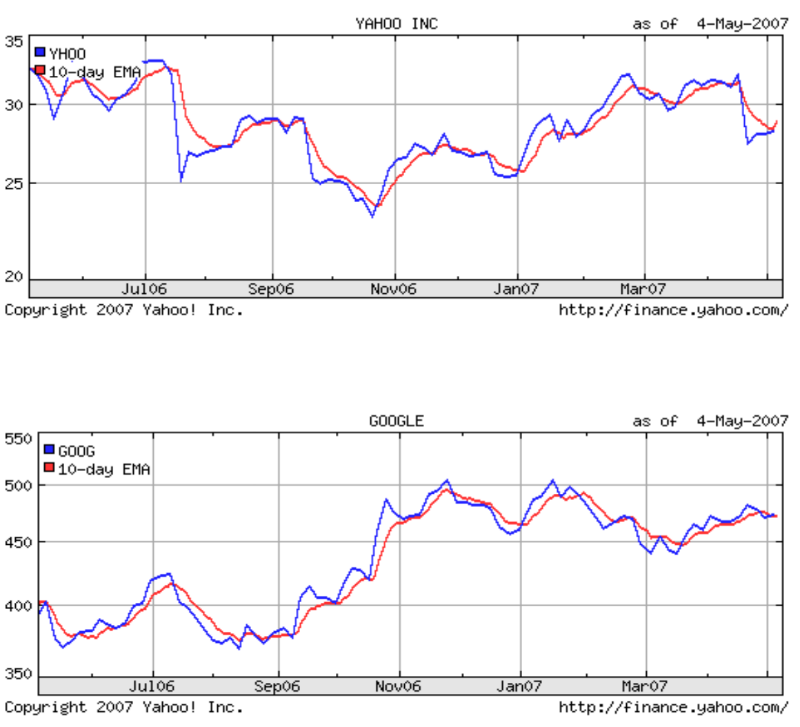
Среда обучения
В ходе проекта были использованы среды для дата-майнинга Weka и YALE. Конфигурация выглядела таким образом:

Шаг выбора атрибутов для некоторых методов машинного обучения был пропущен, поскольку общее их количество составляло меньше 10.
Предобработка исторических данных
Для эксперимента с сайта Yahoo Finance были загружены исторические данные по ценам акций компаний Google Inc. (тикер GOOG) и Yahoo Inc. (YHOO). Набор данных имел следующие атрибуты: Date Open High Low Close Volume Adj. Close.
Индикатор EMA предполагает, что цена акции в предыдущий день торгов будет оказывать на текущую цену наибольшее значение. Таким образом, чем ближе временная точка находится к текущему моменту, тем большее значение она оказывает на цену текущего дня. В ходе временного анализа исследователь брал Дату в качестве оси X — каждая дата представляла собой целое значение. К имеющимся атрибутам был добвлен еще один — Indicator, в данном конкретном случае EMA.
Техники машинного обучения
В данной секции исследования представлены результаты применения различных алгоритмов машинного обучения.
Алгоритм Decision Stump
Применения простого алгоритма для предсказания EMA позволило добиться следующих результатов:
- Коэффициент корреляции 0.8597
- Средняя абсолютная ошибка 46.665
- Корень среднеквадратичной ошибки 57.8192
- Относительная абсолютная ошибка 46.8704 %
- Корень среднеквадратичной относительной ошибки 50.9763 %
- Общее число периодов 681
Линейная регрессия
Применение простой линейной регрессии (используются только численные атрибуты) для предсказания EMA дали следующие результаты:
- Коэффициент корреляции 0.9591
- Средняя абсолютная ошибка 12.9115
- Корень среднеквадратичной ошибки 32.0499
- Относительная абсолютная ошибка 12.9684 %
- Корень среднеквадратичной относительной ошибки 28.2568 %
- Общее число периодов 681
Метод опорных векторов
Использование метода опорных векторов (C-Class) с прмиенение радиальной базисной функции ядра с параметром настройки C в диапазоне от 512 до 65536, позволило получить следующую точность прогнозирования движения цены:
Корень среднеквадратичной ошибки: 0.486 ± 0.012
Точность: 60.20 ± 0.49%
Бустинг
После использования алгоритма C-SVC к набору данных был применен алгоритм бустинга AdaBoostM1 — это позволило добиться серьезного улучшения точности.
Корень среднеквадратичной ошибки: 0.467 ± 0.008
Точность: 64.32% ± 3.99%
Из выходных данных YALE была извлечена следующая матрица неточностей:

Предсказание цен акций на основе текстового анализа финансовых новостей
В настоящее время большой объём ценных данных, которые могут повлиять на ситуацию на рынке, доступен в сети (о подобном влиянии мы писали в своей статье). Большая часть такой информации содержится в финансовых новостях, отчетах компаний и рекомендациях экспертов (источником таких рекомендаций, к примеру, могут служить блог инсайдеров и аналитиков). Большая часть этих данных представлена в текстовом формате, что затрудняет их использование. Таким образом, новая проблема заключается в необходимости анализа текстовых документов одновременно с выполнением анализа временных рядов.
Исследователь использовал метод, который подразумевает определение степени влияния новостей на конкретную акцию: оно может быть позитивным (Positive), негативным (Negative) или нейтральным (Neutral).
Считается, что новость имеет положительное влияние (или негативное), если цена акции серьезно растет (или падает) в период сразу после ее публикации. Если цена акции серьезным образом не изменяется после публикации новости, то ее влияние считается нейтральным.
Другой использованный метод подразумевает определение паттернов в новостных статьях, которые напрямую соовтетствуют росту или снижению цены акций. Он работает следующим образом:
Специальный поисковый робот проходит по новостным статьям и индексирует их для конкретного портфолио акций. Среда обучения запрашивает новости за период T минут с момента индексации. Эта среда состоит из несколько модулей обучения, которые ищут нужную информацию в тексте новостной заметки или материалах из блогов экспертов (например, «цена нефти будет снижаться»). В словарь для анализа входят слова и фразы, влияющие на условия положительного (Positive Prediction Terms) или негативного движения (Negative Prediction). Каждый раз, когда фраза из набора Positive Prediction Terms появляется в тексте статьи, ей присваивается положительная оценка (Positive Vote).
На диаграмме ниже представлена архитектура такой системы:

Как нетрудно заметить, данный метод позволяет делать лишь довольно грубые предположения. Чтобы повысить их точность необходимо добавить статьям больше весов — например, на основе ранжирования источников информации для публикации. Кроме того, следует учитывать форматы заголовков текстов, содержащие фразы из наборов Positive или Negative Prediction Terms.
Использование в качестве веса новости авторитетности экспертов
Исследователь также описывает использование для дополнительного взвешивания текстовых материалов оценку авторитетности экспертов, высказывающих ту или иную точку зрения. К примеру, для акций Google он подобрал список аналитиков, которые долгое время пишут об этой компании, и звездочками отметил степень качества их прогнозов:

На вход системы подаются мнения экспертов рынка акций (просто их мнение, которое необязательно оказывается верным), а затем на основе их прогнозов раз за разом делаются предсказания возможного движения цены. На каждой итерации вес эксперта, чье предсказание оказалось верно, повышается, а у тех, кто ошибся — наоборот снижается. Еще одна разновидность метода предполагает полное удаление из списка тех экспертов, которые ошиблись, однако он является не самым эффективным — все-таки ошибаются даже самые лучшие и уважаемые финансовые аналитики.
Алгоритм взвешивания экспертов может быть описан следующим образом:
Дано: вектор E = { e1, e2,….eN} финансовых экспертов и их прогнозов.
Присвоить вес W(e(i)) = 1 для каждого эксперта e(i).
Для раунда t in 1…T
Сделать предсказание на основе алгоритма взвешенного большинства.Для экспертов, которые сделали верный прогноз W(e(i))(t) = 2*W(e(i))(t-1)
Для экспертов, которые сделали неверный прогноз W(e(i))(t) = ½ * W(e(i))(t-1)
Сохранить рейтинг эксперта (Expert Rating) для последующего взвешивания.
Такую технику взвешивания на основе экспертных мнений можно рассматривать в качестве гибридного подхода, комбинирующего в себе фундаментальный и технический анализ — эксперты делают прогнозы на основе фундаментального анализа, а алгоритм впоследствии использует их для генерирования собственных прогнозов с помощью методов технического анализа.
Заключение
Из всех использованных алгоритмов только комбинация метода опорных вектора и алгоритма бустинга позволили добиться сколько-нибудь удовлетворительных результатов точности прогноза.
Другим перспективным методом анализа является взвешивание экспертов. Однако в настоящий момент эффективность методов лингвистического анализа для генерирования прогнозов движения цен акций является предметом дальнейшего изучения и каких-то определенных выводов о его применимости на практике сделать нельзя.