Redis очень неплох. Всё больше разработчиков и компаний выбирают его не только в качестве кэширующего in-memory сервиса или системы очередей, но в и в качестве основного хранилища данных, взамен MySQL или Postgres. Да, именно так. Благодаря поддержке разнообразных структур данных, таких как: строки, списки, множества, упорядоченные множества и хэш-таблицы, на Redis отлично перекладывается большинство типичных данных, которые исторически было принято хранить в реляционных СУБД.
Но и это ещё не всё. Редис умеет и некоторые специфические вещи, например, HyperLogLog. (Здесь нужно дописать о всех современных фичах Редиса). Так стоит ли использовать редис в качестве основного хранилища данных? Так же эту заметку можно рассматривать в контектсте любой другой key-value базы данных с похожим внутренним устройством, например, любимая многими MongoDB.
Для начала давайте рассмотрим варианты как Redis может потерять все данных хранящиеся в нём. Во-первых, это in-memory, но персистентное хранилище. Это значит, что максимальный размер данных которые могут поместиться в Redis не могут превышать размер оперативной памяти сервера за вычетом объёма служебных данных пожираемых Редисом. Данные из оперативной памяти периодически записываются на диск и в случае остановки и повторного запуска считываются с диска. (Здесь нужно написать как этим можно управлять через конфигурацию).
Что произойдёт если данные перестанут помещаться в память? Тут 2 варианта, либо Redis как и любая другая современная NoSQL поделка перестанет отвечать на запросы, либо начнёт удалять старые данные с минимальным TTL, фактически навсегда и без уведомления удаляя данные из «постоянного» хранилища! (Здесь нужно посмотреть документацию современных версий, т.к. поведение могло измениться).
Как Redis защищён от потери данных?
Что если во время записи данных на диск совершить хард-резет сервера? Вообще в Redis предусмотрено два режима для persistence: RDB и AOF и в обоих заявляется весьма надёжный способ записи на диск, который практически исключает ситуации потери данных при аппаратном сбое. Собственно, какая часть данных будет потеряна и определяется выбранным режимом.
С помощью RDB в среднем может быть потеряно около часа данных. Redis сначала пишет полный снапшот базы во временный файл и только после окончания записи на диск переименовывает его в рабочий. Это исключает потерю данных благодаря атомарности системного вызова rename().
В режиме AOF (Append Only File) ведётся лог операций в файл, по-умолчанию каждую секунду. Redis не изменяет уже записанные данные, а лишь добавляет новые в конец. Максимум, что вы теряете в случае сбоя при использовании этого режима — это 1 секунда, либо значение которые вы указали в конфиге. Этот режим медленнее RDB, лог-файл существенно больше, + производительность зависит от параметров fsync. По данным из интернета, скорость записи может снизиться в 2 раза.
Включить этот режим достаточно просто, достаточно во время запуска сервера указать дополнительный параметр: redis-server —appendonly yes
Однако, если Redis используется как основное хранилище данных, то режим AOF persistence — однозначный must have. Если же Redis используется как кэш, то режим персистентности вообще можно отключить и получить космические скоростя.
По-умолчанию включен именно RDB, а файл с дампом называется dump.rdb. Проверить это можно либо в конфигурационном файле redis.conf, либо посмотрев вывод команды:
redis-cli -p 6379 info
Тестирование режимов персистентности в Redis
Кстати, для проверки быстродействия можно воспользоваться инструментом входящим в стандартный комплект редиса:
redis-benchmark -q -n 100000 -c 50 -P 12
Например, на моей железке результаты для RDB:
root@e250389f9128:/data# redis-benchmark -q -n 100000 -c 50 -P 12 PING_INLINE: 606060.56 requests per second PING_BULK: 649350.62 requests per second SET: 781249.94 requests per second GET: 892857.12 requests per second INCR: 934579.44 requests per second LPUSH: 934579.44 requests per second RPUSH: 934579.44 requests per second LPOP: 917431.19 requests per second RPOP: 892857.12 requests per second SADD: 943396.25 requests per second HSET: 909090.94 requests per second SPOP: 934579.44 requests per second LPUSH (needed to benchmark LRANGE): 943396.25 requests per second LRANGE_100 (first 100 elements): 122850.12 requests per second LRANGE_300 (first 300 elements): 31565.66 requests per second LRANGE_500 (first 450 elements): 19731.65 requests per second LRANGE_600 (first 600 elements): 13351.14 requests per second MSET (10 keys): 321543.41 requests per second
Результаты для AOF:
root@923c8a488e9a:/data# redis-benchmark -q -n 100000 -c 50 -P 12 PING_INLINE: 588235.31 requests per second PING_BULK: 729927.06 requests per second SET: 529100.56 requests per second GET: 900900.88 requests per second INCR: 641025.62 requests per second LPUSH: 606060.56 requests per second RPUSH: 555555.56 requests per second LPOP: 617283.94 requests per second RPOP: 621118.00 requests per second SADD: 934579.44 requests per second HSET: 625000.00 requests per second SPOP: 934579.44 requests per second LPUSH (needed to benchmark LRANGE): 546448.06 requests per second LRANGE_100 (first 100 elements): 120918.98 requests per second LRANGE_300 (first 300 elements): 33636.06 requests per second LRANGE_500 (first 450 elements): 19164.43 requests per second LRANGE_600 (first 600 elements): 13664.94 requests per second MSET (10 keys): 213219.61 requests per second
Выключить персистентность можно с помощью опций:
—save «» —appendonly no
root@481069a193b9:/data# redis-benchmark -q -n 100000 -c 50 -P 12 PING_INLINE: 529100.56 requests per second PING_BULK: 877193.00 requests per second SET: 917431.19 requests per second GET: 909090.94 requests per second INCR: 943396.25 requests per second LPUSH: 900900.88 requests per second RPUSH: 934579.44 requests per second LPOP: 917431.19 requests per second RPOP: 793650.75 requests per second SADD: 769230.81 requests per second HSET: 781249.94 requests per second SPOP: 925925.88 requests per second LPUSH (needed to benchmark LRANGE): 934579.44 requests per second LRANGE_100 (first 100 elements): 118483.41 requests per second LRANGE_300 (first 300 elements): 29239.77 requests per second LRANGE_500 (first 450 elements): 19766.75 requests per second LRANGE_600 (first 600 elements): 13636.98 requests per second MSET (10 keys): 296735.91 requests per second
Redis внутри Docker-контейнера
Однако, не всё так просто если вы используете Redis в Docker. Естественно, при работе с Redis в Docker нужно использовать примонтированную папку в качестве volume для постоянного хранения данных, чтобы не потерять всю БД при пересоздании контейнера, это было бы совсем глупой ошибкой =) И тут стоит понимать специфику работы докера с волюмами.
Фактически Docker предлагает 3 режима согласованости данных между хостом и контейнером:
- consistent: perfect consistency (host and container have an identical view of the mount at all times)
- cached: the host’s view is authoritative (permit delays before updates on the host appear in the container)
- delegated: the container’s view is authoritative (permit delays before updates on the container appear in the host)
И ко всему этому заявляется, что текущие реализации mounts на Linux обеспечивают согласованное представление дерева каталогов хоста внутри контейнера: чтение и запись, выполненные либо на хосте, либо в контейнере, немедленно отражаются в другой среде, а события файловой системы (inotify, FSEvents) — это последовательно размножается в обоих направлениях.
The current implementations of mounts on Linux provide a consistent view of a host directory tree inside a container: reads and writes performed either on the host or in the container are immediately reflected in the other environment, and file system events (inotify,FSEvents) are consistently propagated in both directions.
Как потерять все данные в Redis
И Redis и Docker каждый на своей стороне реализуют механизмы для согласованности и защиты данных от аппаратных сбоев. Однако, на практике может возникнуть ситуация, при которой Redis не сможет прочитать данные из файла dump.rdb и данные будут утеряны.
Воспроизвести подобную ситуацию крайне сложно и специально у меня не получилось, вариаций как это может произойти — масса, но усреднённый рецепт для потери все данных в Redis скорее всего связан с несколькими факторами одновременно:
- выполнение редисом операций по записи на диск
- большая нагрузка на файловую подсистему
- отсутствие свободного места на диске
- исчерпание свободного ОЗУ
- лаг в какой либо из подсистем docker-контейнера
- HARD RESET!
Если же у вас получится повредить файл, то redis-server не сможет стартовать из-за повреждённого файла. К сожалению, ошибку полученную в результате я не сохранил, однако воспроизвёл её с помощью ручного повреждения файла с дампом. Выглядит она примерно так:
redis_1 | 1:M 26 Mar 23:33:25.645 # WARNING: The TCP backlog setting of 511 cannot be enforced because /proc/sys/net/core/somaxconn is set to the lower value of 128. redis_1 | 1:M 26 Mar 23:33:25.645 # Server initialized redis_1 | 1:M 26 Mar 23:33:25.645 # WARNING overcommit_memory is set to 0! Background save may fail under low memory condition. To fix this issue add 'vm.overcommit_memory = 1' to /etc/sysctl.conf and then reboot or run the command 'sysctl vm.overcommit_memory=1' for this to take effect. redis_1 | 1:M 26 Mar 23:33:25.645 # WARNING you have Transparent Huge Pages (THP) support enabled in your kernel. This will create latency and memory usage issues with Redis. To fix this issue run the command 'echo never > /sys/kernel/mm/transparent_hugepage/enabled' as root, and add it to your /etc/rc.local in order to retain the setting after a reboot. Redis must be restarted after THP is disabled. redis_1 | 1:M 26 Mar 23:33:25.729 # Internal error in RDB reading function at rdb.c:183 -> Unknown length encoding 2 in rdbLoadLen() redis_1 | [offset 0] Checking RDB file dump.rdb redis_1 | [offset 26] AUX FIELD redis-ver = '4.0.5' redis_1 | [offset 40] AUX FIELD redis-bits = '64' redis_1 | [offset 52] AUX FIELD ctime = '1522107075' redis_1 | [offset 67] AUX FIELD used-mem = '69327376' redis_1 | [offset 83] AUX FIELD aof-preamble = '0' redis_1 | [offset 85] Selecting DB ID 0 redis_1 | --- RDB ERROR DETECTED --- redis_1 | [offset 1871065] Internal error in RDB reading function at rdb.c:183 -> Unknown length encoding 2 in rdbLoadLen() redis_1 | [additional info] While doing: read-object-value redis_1 | [additional info] Reading key 'demo:396' redis_1 | [additional info] Reading type 5 (zset-v2) redis_1 | [info] 201 keys read redis_1 | [info] 0 expires redis_1 | [info] 0 already expired redis_1 exited with code 1
Создание Redis кластера с репликацией
Ещё один способ защитить данные от факапа, который используется на более крупных проектах — репликация. Да не простая репликация, а кольцевая, вот картинка:
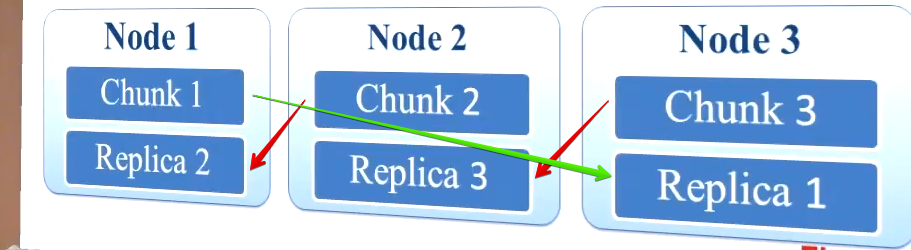
Т.е. берётся 3 сервера, половина ОЗУ каждого сервера выделяется под данные, а вторая половина — под реплику с соседнего сервера, получается некое кольцо. При вылете одной из нод теряется только 1 мастер и 1 реплика. Однако, целостность данных в кластере сохраняется и сервис может продолжать работу без даунтайма. У админов же есть время чтобы поднять новый сервер и перенести на него данные.
Что же произойдёт, если в датацентре с Redis-кластером наступит blackout? Ответа основанного на личном опыте у меня нет, но есть вероятность, что на всех нодах файл с данными окажется битым и данные будут утеряны. Однако, вероятность такой ситуации крайне мала, но по законам Мэрфи с кем-нибудь и когда-нибудь такое произойдёт в самый неподходящий момент.
А как же бэкапы и восстановление Redis?
Бекапы это конечно хорошо, однако, они не решают проблему полностью. Да, бэкап сохранит часть данных, однако какая-то часть будет потеряна и для бизнеса это может быть фатально. В качестве реалтайм бекапа вполне можно использовать репликацию.
Выводы
И что делать? Поднимать ещё один кластер с Редисами в другом дата-центре? Вариант, конечно, хороший, однако, весьма дорогой и сложный в настройке и эксплуатации. В целом, использовать Redis в качестве основного хранилища данных вполне оправдано, однако нужно учитывать все риски и если потеря данных не так страшна, как потеря производительности, то Redis станет хорошей альтернативой традиционным реляционным СУБД.
Вероятность получить RDB ERROR DETECTED крайне мала, но если это случилось — то, скорее всего, единственный вариант это удалить dump.rdb и начать всё с чистого листа / бэкапа / реплики.
С AOF персистеностью проблем должно быть ещё меньше, однако, это всё-равно требует тщательного тестирования в экстремальных условиях, а так же мониторинга.
Запуск Redis через docker-compose
Пример настройки Redis через docker-compose. Здесь для простоты используется «оригинальный» образ с редисом, однако, для пущей секъюрности образ лучше собрать самостоятельно.
redis: image: redis restart: always volumes: - ./storage/redis/data:/data ports: - 6379:6379 logging: driver: none