Программисты автоматизируют мир. Начав с автоматизации подсчета денег, где табличные записи естественны, программисты стали заталкивать в таблички всё, до чего их допустили. И это работало. В прошлом веке. И это хорошо т.к. из глубин вековой давности мы получили SQL – языка запросов к табличке. SQL хватает почти всегда – он простой, логичный и все его знают. А когда не хватает, его расширяют. И дальше мы будем работать с расширениями и диалектами SQL.
В реальном мире всё несколько сложнее. В табличках представлять большие и сложные зависимости сложно и не эффективно по ресурсам (дисковое пространство,процессор, и главный ресурс – время). А какие данные не идеальны для табличек? Может, это лишние данные?
Важный граф
В математике есть понятие граф – набор вершин (узлы) и связей этих вершин (ребро).
Минимальный граф – это две вершины и одно ребро между ними. Например этим минимальным графом мы можем нарисовать семейную пару: М —- Ж. То есть граф – это естественные связи вещей и цепочки этих связей.
Например, записать структуру папок на компьютере в табличку. Для рубистов штук 5 гемов есть и только одно правильное решение – ltree + индексы. Кроме правильного есть идеальное решение: LDAP. А структуру организации в табличку? Тоже можно, но дурная затея, LDAP и тут выручает. И то и то деревья – есть корень и ветки, самая толстая ветка – ствол ?
Не видел в жизни ни одного графа
Да даже мой любимый git это граф. Выполните в любом своём репозитории:
git log --graph --abbrev-commit --decorate --date=relative --all
И вы увидите дерево изменений.
Еще один граф – это родственные связи в Звездных Войнах (как вы помните, там только Император был сиротой).
А еще на графах интернет держится. Например, алгоритм Дейкстры как раз решает задачу как бы быстрейший/кратчайший путь найти.
Когда у нас простой граф мы можем его нарисовать в табличках.
Графы кстати бывают разные. Граф, в котором связи направленные и не создают петель называется … направленный ацикличный граф https://en.wikipedia.org/wiki/Directed_acyclic_graph. Этот тип графа важен для понимания логики работы Spark-приложений, так же он помогает формализировать бизнес процессы и ускорять их.
Если б на почте РФ знали о таких графах, то почтой бы чаще пользовались и не надо было в отделениях торговать сигаретами и водкой. И раз уж мы вспомнили Apache Spark, то RDD представляет из себя дерево разных версий RDD (если вы не поняли о чем речь, то читаем публикации создателя Spark ).
Зависимости в приложении тоже граф, например ruby-erd может для руби приложения нарисовать.
Neo4j и простые запросы
А если у нас тысячи узлов? То тоже можем использовать таблички, только устанем. Вот тут на помощь приходит специализированный инструмент – графовые базы данных. Их много, но мы выберем Neo4j – она сама простая для начала и имеет прекрасный веб-интерфейс с визуализацией, а красивая картинка иногда информативнее тысячи слов.
Есть графовые «базы», использующие табличное хранение данных, но использующие графовую абстракцию – эта порнография работает только в специфичных условиях (в этих же условиях платят хорошо, потому запоминаем cassandra + titan или Spark).
Потихоньку начнем изучать Neo4j с данными, доступными каждому.
Сначала запустим Neo4j, что очень легко, как и всё в Java мире:
- Качаете архив neo4j-community-3.0.3 с официального сайта http://neo4j.com/
- Распаковываете
tar -xzvf ./neo4j-community-3.0.3-unix.tar.gz - Запускаете
./bin/neo4j start
А вообще, не надо. Останавливайте: ./bin/neo4j stop. Сделаем современно и молодежно.
docker run --publish=7474:7474 \
--publish=7687:7687 \
--volume=$HOME/neo4j/data:/data:rw,z \
--env=NEO4J_AUTH=none neo4j:3.0
А дальше самое интересное, причина почему стоит начинать с Neo4j: откройте в браузере http://localhost:7474/. Всё, вы – властелин графовой базы данных.
Интерактивная консоль и визуализация упростит старт. А еще мы отключили аутентификацию --env=NEO4J_AUTH=none. Для наших экспериментов она не нужна, а для боевых систем надо всё параноидально закрывать. Хотя это и смешно – закрывать и Docker ?
Так же там есть документация по возможностям системы и статистика по используемым ресурсам.
Создадим минимальный граф.
В данной статье главный диалект языка SQL зовётся “Кефир”: https://neo4j.com/developer/cypher-query-language/ ?
CREATE (c:M {id: 'Male’'})-[:rel {weight:500} ]->(b:F {id: 'Female'});
И посмотрим на результат:
MATCH (n) RETURN n LIMIT 1000;
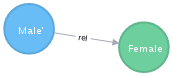
Граф у нас направленный, даже в наш безумный век мужчина направлен к женщине. Любопытно, что направлением при поиске можно пренебречь:
MATCH p=(n)-->(b) return p
A можно не пренебрегать:
MATCH (n)-[p]->(b) WHERE startNode(p).id='Male' return b, n; // вернется наш граф
MATCH (n)-[p]->(b) WHERE startNode(p).id='Female' return b, n; // а тут уже пустой
Еще мы можем выбрать самые сильные отношения, чего размениваться на короткие интрижки:
MATCH (n)-[p]->(b) WHERE p.weight > 1000 return b, n /// таких нет, но вы можете снизить порог фильтра
Заметки по Кефировским запросам для игр на досуге.
Создаем ноды, если нет:
MERGE (c:M {id:'Male1'});
Создаем отношения, если их нет, и ноды если их нет:
MERGE (p:twivi13 {id: 'twivi13'})
MERGE (n:Real {id:'Real'})
CREATE UNIQUE (p)-[r:rel {weidth: 0}]-(n) return r
Обновляем вес отношений, если они есть:
MATCH (n)-[p]->(b) WHERE b.id='Male' AND n.id='Female'
SET p.weight = p.weight + 7
RETURN p
Смотрим в Neo4j только сотню самых сильных отношений:
MATCH (n)-[p]-(b)
RETURN p Order by p.weight DESC limit 100
Ищем вершины с более чем 2 связями:
MATCH (n) WHERE size((n)--())>2 RETURN n
Ну и если захотим удалить:
MATCH (n) DETACH DELETE n
Все классно, всё работает, всё просто. Но пользы ни какой.
Пишем приложения с Neo4j, Spark и данными Твиттера
Надо залить другие данные. И всплывает вопрос о том, как приложение вообще может общаться с Neo4j?
Есть поддержка формата для хипстеров HTTP API с JSON, в нём есть даже загрузка данных пачками. Так что с этой стороны все правильно, но зря.
Следующий вариант: протокол Bolt. Bolt бинарный, шифруемый и изобретен специально для Neo4j.
Каждое приложение должно придумать свой протокол, а то протоколов не хватает.
Есть уже драйвер для java и коннектор для Spark.
И раз уж есть такая возможность, то впихиваем все модные инструменты без разбору, особенно если в них нет нужды. И в модных инструментах выберем еще и модные названия: напишем приложение для Spark Streaming, которое будет читать твиттер, строить граф и обновлять связи в графе.
Есть прогноз что Spark Streaming через 5 лет будет не актуален, но сейчас за него платят. И он еще и не стриминг ни разу ?
Твиттер – доступный источник большого количества лишней информации. Можно даже считать его графом человеческой глупости. А вот задался бы кто целью проследить развитие идей – был бы наглядный аргумент за классическое образование (у меня его нет, о чем данная статья аж кричит).
Делаем модно:
Первым делом скачиваем исходники Spark на свою локальную машинку.
git clone https://github.com/apache/spark
git checkout branch-1.6
И в одном из примеров узнаем как подключиться к твиттеру и как его читать. И других примеров там много – полезно просмотреть, пролистать, чтобы знать, что Spark уже умеет.
Если это первое ваше знакомство с твиттером с этой стороны, то ключики и токены брать тут https://apps.twitter.com. После модификации примера получиться может так:
package org.apache.spark.examples.streaming
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.StreamingContext._
import org.apache.spark.SparkContext._
import org.apache.spark.streaming.twitter._
// да да - тут эклипс бы отрефакторил всё, но я на виме
import org.apache.spark.streaming.twitter.TwitterUtils
import org.apache.spark.storage.StorageLevel
import org.apache.spark.SparkConf
import org.neo4j.driver.v1._
object Twittoneo {
def main(args: Array[String]) {
StreamingExamples.setStreamingLogLevels()
// а сюда я сначала настоящие ключи записал :)
System.setProperty("twitter4j.oauth.consumerKey", "tFwPvX5s")
System.setProperty("twitter4j.oauth.consumerSecret", "KQvGuGColS12k6Mer45jnsxI")
System.setProperty("twitter4j.oauth.accessToken", "113404896-O323jjsnI6mi2o6radP")
System.setProperty("twitter4j.oauth.accessTokenSecret", "pkyl20ZjhtbtMnX")
val sparkConf = new SparkConf().setAppName("Twitter2Neo4j")
val ssc = new StreamingContext(sparkConf, Seconds(5))
val stream = TwitterUtils.createStream(ssc, None)
val actData = stream.map(status => {
// extract from twitter json only interesting fields
val author:String = status.getUser.getScreenName.replaceAll("_", "UNDERSCORE")
val ments:Array[String] = status.getUserMentionEntities.map(x => {
x.getScreenName.replaceAll("_", "UNDERSCORE")
})
(author, ments)
})
actData.foreachRDD(rdd => {
if(!rdd.isEmpty()) {
println("Open connection to Neo4jdb")
val driver = GraphDatabase.driver( "bolt://localhost",
AuthTokens.basic( "neo4j", "neo4j" ))
try{
// collect called for execute all logic on driver
// http://spark.apache.org/docs/latest/cluster-overview.html
rdd.collect().foreach(x =>{
x._2.foreach( target =>{
val session = driver.session()
// create relation if not exist
// merge (p:twivi13 {id: 'twivi13'})
// merge (n:Real {id:'Real'})
// create unique (p)-[r:rel {weidth: 0}]-(n) return r
//
// pregix 'twi' and replacement _ to UNDESCORE require because Neo4j has many restrictions for label
val relation = "MERGE (p:twi"+ x._1+" {id:'twi"+x._1+"'}) MERGE (d:twi"+ target+" {id: 'twi" + target + "'}) CREATE UNIQUE (p)-[r:rel {weight: 0}]-(d) RETURN 1"
println(relation)
val result1 = session.run(relation)
result1.consume().counters().nodesCreated();
session.close()
})
})
} finally {
driver.close()
println("Close Neo4j connection")
}
driver.close()
}
})
ssc.start()
ssc.awaitTermination()
}
}
Обратите внимание – neo4j-spark-connector нам сейчас не нужен, вместо него мы возьмем neo4j-java-driver, который отвечает только за связь java-приложения и Neo4j , без выгрузок и загрузок в естественные форматы RDD или GraphFrame. Но в след. статье они нам понадобятся для настоящей работы носящей гордое имя Big Data инженер.
Компилируем и ставим в локальный Maven репозиторий библиотеку neo4j-java-driver:
git clone [email protected]:neo4j/neo4j-java-driver.git
cd neo4j-java-driver
mvn clean package install
Кладём наш код в src/main/scala/org/apache/spark/examples/streaming/Twitter2neo4j.scala. Находясь в папке examples добавляем в ./pom.xml:
<dependency>
<groupId>org.neo4j.driver</groupId>
<artifactId>neo4j-java-driver</artifactId>
<version>1.1-SNAPSHOT</version>
</dependency>
Дальше компилируем примеры вместе с нашим: вызывайте mvn -Phadoop-2.6 -Dhadoop.version=2.6.0 -DskipTests clean package.
Кстати, на моём курсе первым делом учимся maven, gradle и sbt. Это основа основ. Важнее только bash.
У нас получается jar файлик с которым дальше будем работать. Вместо компиляции Spark опять же будем использовать модный Docker.
Обратите внимание на версию Spark – 1.6.1. Важно что б ваш пакет и Spark были одной версией, а то Spark так быстро развивается , что иногда даже слишком быстро.
Помним о безопасности. И еще один интересный момент за Docker – образ для нас собрал непонятно кто, а докер работает от рута (хипстеры писали , что с них взять).Теоретически, это огромная дыра в безопасности. Я-то смело выполняю данные действия — в наипоследнейшей Fedora с включенным selinux, ограждающим дырявый докер. А пользователей убунты не жалко. Кстати, супер крутая и модная версия докера называется chroot.
Запустим контейнер (коробочку, ведерко), экспортируя текущую папку в /shared c правом на только чтение(ro) и перемаркируя selinux контекст в svirt_sandbox_file_t.
Контекст SELinux для песочницы останется и после остановки контейнера. Так же экспортируем нами скомпилированную библиотеку для neo4j-java-driver.
А вот был бы у нас свой центральный репозиторий, например Nexus – было бы проще.
Или как вариант можно поправить pom.xml и собирать со всеми необходимыми зависимостями. У нас получится два контейнера которые должны общаться, поэтому пойдём по пути наименьшего сопротивления – Spark-контейнер будет использовать сетевой стек Neo4j контейнера, разделяя с ним ip адрес.
Для этого вызываем docker ps | grep -i neo4j | awk '{print $1}' и смотрим id контейнера.
docker run -it -v `pwd`:/shared:ro,z \
-v /path/to/neo4j-java-driver/driver/target:/neo4jadapter:ro,z \
--net=container:ca294ee9e614 \
sequenceiq/spark:1.6.0 bash
Вот мы оказались в контейнере. У нас есть хадуп и спарк. Но хадуп мы трогать не будем – он нам не мешает, а Spark запустим так, что б он выполнялся локально(—master local[4]):
spark-submit --jars /neo4jadapter/neo4j-java-driver-1.1-SNAPSHOT.jar \
--packages "org.apache.spark:spark-streaming-twitter_2.10:1.6.1" \
--class org.apache.spark.examples.streaming.Twittoneo \
--master local[4] \
--driver-memory 1g \
--executor-memory 1g \
--executor-cores 1 \
--verbous \
/shared/target/spark-examples_2.10-1.6.1.jar
Ждем минут хотя бы 10 и смотрим результат. Но чем больше данных соберем, тем интереснее.
Красота!!!
Если хотите краше, динамичнее и может даже в реальном времени, то есть курс Екатерины Шпак. Там учат d3.js и прочим хитростям красивого фронтенда. Вообще в Big Data половина дела – это презентовать ваши достижения среднестатистическому менеджеру, у которого хоть и классическое образование, но без картинки не поймёт.
В данном примере есть один важный момент – не используется суперсила Spark. Ведь в Spark мы можем построить сразу готовый граф, аггрегировать все сообщения и только потом заливать в Neo4j. Этим можно значительно повысить количество информации перерабатываемое системой. Но кого это волнует в обучающем примере. Да даже в реальности это мало кого волнует ?
Выводы и прогнозы на следующую часть
Полученная база и та выборка, что мы делаем, не практична. Следующий шаг это найти например самых влиятельных пользователей (найти, дать им деньги и пусть рекламируют наш товар). Или отслеживать упоминание вашего бренда и в зависимости от ситуации (ругают, хвалят, кто отзывается) пытаться увеличить прибыль. Это очевидные примеры использования, но в славной стране Германия есть закон запрещающий хранить данные пользователей позволяющие явно идентифицировать оных.
Так вот, используя большой массив данных из разных источников можно пользователя узнавать и по косвенным уликам. Так что тот факт что у меня параноя совсем не отменяет слежки за каждым из нас. И приятнее быть еще и тем, кто следит, чем только тем, за кем следят. И графы тут очень помогают, о чем поговорим в следующей части. Кстати — заодно посмотрим решения, когда Neo4j не хватает, ведь при всех своих достоинствах Neo4j не масштабируется. Авторы Neo4j с этим не согласны, но кто им верит.
Кстати особенность всех nosql решений – база строится исходя из того что и как вы будете запрашивать. Когда кричат, что что-то schemaless – значит либо врут, либо невозможно работать ?