Регулярные выражения — это собственный язык. Когда вы изучаете новый язык программирования, они — маленький субъязык, на первый взгляд, не имеющий смысла. Вам нужно прочитать не один учебник, статью или книгу, чтобы понять описание «простого» шаблона. Сегодня мы рассмотрим восемь регулярных выражений, которые вы должны знать для своего следующего проекта кодирования.
Прежде чем начать, вы можете проверить некоторые из regex apps на Envato Market, таких как:
RegEx Extractor
Вы можете извлекать электронные письма, прокси, IP-адреса, номера телефонов, адреса, теги HTML, URL-адреса, ссылки, даты и т. д. Просто вставьте одно или несколько регулярных выражений и источников URL-адресов и запустите процесс.
Извлечение, очистка, анализ, сбор.
Примеры использования
- Извлечение писем из старой адресной книги CSV.
- Извлечение источников изображения из файлов HTML.
- Извлечь прокси из интернет-сайтов.
- Извлечение URL из результатов поиска Google.
PHP Regular Expression Tester
- Быстрый тестер регулярных выражений
- Основанный на AJAX
- JQuery и прочее не требуются.
- База данных не требуется
- Готово к рекламе
MyRegExp
Это PHP RegEx builder, который помогает вам создавать регулярные выражения в расширенном синтаксисе PHP. Вы можете:
- Строить Regular Expressions с помощью простого синтаксиса PHP
- Проверять строки с помощью RegEx
- Создавать RegEx и получать их
- Применить preg_match к RegEx
- Заменять строку с RegEx
Все это в синтаксисе PHP. Нет больше голов, сломанных при попытке сделать базовый или сложный RegEx!
Справочная информация о Regular Expressions
Вот что Википедия говорит:
В программировании регулярные выражения предоставляют сжатое и гибкое средство для идентификации строк текста, таких как конкретные символы, слова или шаблоны символов. Регулярные выражения (сокращенно regex или regexp с множественными формами regexps или regexen) записываются на официальном языке, который может быть интерпретирован процессором регулярных выражений, программой, которая либо служит генератором parser, либо анализирует текст и идентифицирует части, которые соответствуют предоставленной спецификации.
Это ничего не говорит мне о фактических образцах. Регулярные выражения, которые я буду обсуждать сегодня, содержат такие символы, как \w, \s, \1 и многие другие, которые ни на что другое не похожи.
Если вы хотите немного узнать о регулярных выражениях, прежде чем продолжать читать эту статью, я предложил бы посмотреть серию Regular Expressions for Dummies.
Восемь регулярных выражений, которые мы будем обсуждать сегодня, позволят вам сопоставить a(n): username, password, email, hex value (#fff или #000), slug, URL, IP address и HTML tag. Ближе к концу списка регулярные выражения становятся все более запутанными. Изображения для regex в начале понятны, но последние четыре легче понять, прочитав объяснение.
Главное, что нужно помнить о регулярных выражениях, — это то, что они почти одинаково читаются вперёд и назад. В этом предложении больше смысла, когда мы говорим о совпадении тегов HTML.
Примечание: Ограничителями, используемыми в регулярных выражениях, являются косые черты, «/». Каждый шаблон начинается и заканчивается разделителем. Если прямая косая черта появляется в regex, мы должны убрать её обратной косой: «\ /».
1. Соответствие имени пользователя

Шаблон:
|
1
|
/^[a-z0-9_-]{3,16}$/ |
Описание:
Сначала мы просим parser найти начало строки (^), за которой следуют любая буква в нижнем регистре (a-z), номер (0-9), символ подчёркивания или дефис. Далее {3,16} удостоверяется, что по крайней мере 3 из этих символов, но не более 16. Наконец, нам нужен конец строки ($).
Строка, которая соответствует:
my-us3r_n4m3
Строка, которая не соответствует:
th1s1s-wayt00_l0ngt0beausername (слишком длинная)
2. Проверка пароля

Шаблон:
|
1
|
/^[a-z0-9_-]{6,18}$/ |
Описание:
Проверка пароля очень похожа на проверку имени пользователя. Единственное отличие состоит в том, что вместо 3-16 букв, цифр, подчеркиваний или дефисов нам нужно от 6 до 18 ({6,18}).
Строка, которая соответствует:
myp4ssw0rd
Строка, которая не соответствует:
mypa$$w0rd (знак доллара лишний)
3. Согласование Hex Value

Шаблон:
|
1
|
/^#?([a-f0-9]{6}|[a-f0-9]{3})$/ |
Описание:
Начнём с указания parser найти начало строки (^). Затем знак числа является необязательным, поскольку за ним следует вопросительный знак. Вопросительный знак говорит parser, что предыдущий символ — в данном случае знак числа — является необязательным, но чтобы был «жадным» и отметил его, если он есть. Далее, внутри первой группы (первая группа круглых скобок) мы можем иметь две разные ситуации. Первая — любая буква в нижнем регистре между a и f или число шесть раз. Вертикальная полоса говорит нам, что мы можем также иметь три строчные буквы между a и f или номерами. Наконец, нам нужен конец строки ($).
Причина, по которой я ставил шесть символов перед этим, заключается в том, что parser запишет значение hex value типа #ffffff. Если бы я перевернул его так, чтобы три символа стали первыми, parser мог бы получить только #fff, а не другие три f.
Строка, которая соответствует:
#a3c113
Строка, которая не соответствует:
#4d82h4 (содержит букву h)
4. Проверка Slug

Шаблон:
|
1
|
/^[a-z0-9-]+$/ |
Описание:
Вы будете использовать это регулярное выражение, если вам когда-либо придется работать с mod_rewrite и красивыми URL. Сначала мы попросим parser найти начало строки (^), за ней следуют одна или несколько (плюс знак) букв, цифры или дефисы. Наконец, нам нужно окончание строки ($).
Строка, которая соответствует:
my-title-here
Строка, которая не соответствует:
my_title_here (содержит нижний дефис)
5. Проверка Email
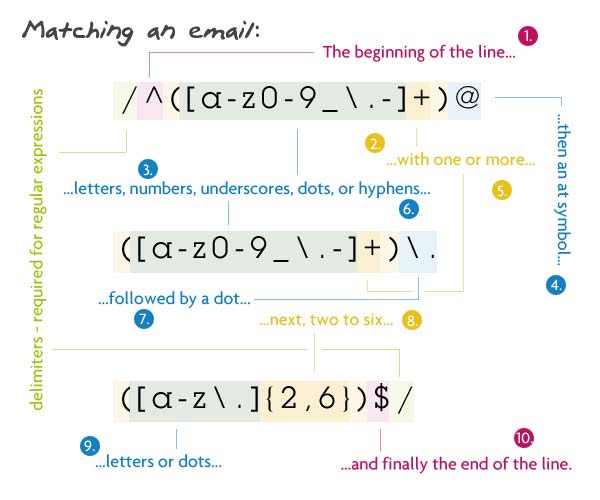
Шаблон:
|
1
|
/^([a-z0-9_\.-]+)@([\da-z\.-]+)\.([a-z\.]{2,6})$/ |
Описание:
Начнем с указания parser найти начало строки (^). Внутри первой группы мы сопоставляем одну или несколько строчных букв, цифр, символов подчёркивания, точек или дефисов. Я убрал точки, потому что открытая точка означает любой символ. Сразу после этого должен быть знак «at». Далее следует имя домена, которое должно быть: одна или несколько строчных букв, цифр, символов подчёркивания, точек или дефисов. Затем (экранированная) точка, с расширением от двух до шести букв или точек. У меня от 2 до 6 из-за специфических для страны TLD (.ny.us или .co.uk). В финале нам нужен конец строки ($).
Строка, которая соответствует:
Строка, которая не соответствует:
[email protected] (TLD длинный)
6. Проверка URL

Шаблон:
|
1
|
/^(https?:\/\/)?([\da-z\.-]+)\.([a-z\.]{2,6})([\/\w \.-]*)*\/?$/ |
Описание:
Это regex почти походит к заключительной части вышеупомянутого регулярного выражения, собрав его между «http: //» и некоторой структурой файла в конце. Это звучит намного проще, чем есть на самом деле. Для начала мы ищем начало строки с помощью каретки.
Первая группа охвата — это все опции. Он позволяет URL-адресу начинаться с «http: //», «https: //» или без них. У меня вопросительный знак после s, чтобы разрешить URL-адреса с http или https. Чтобы сделать всю эту группу необязательной, я просто добавил вопросительный знак к её концу.
Далее идет доменное имя: одно или несколько чисел, букв, точек или дефисов, за которыми следует другая точка, затем от двух до шести букв или точек. Следующий раздел — это необязательные файлы и каталоги. Внутри группы мы хотим сопоставить любое количество косой черты, буквы, цифры, символы подчёркивания, пробелы, точки или дефисы. Затем мы говорим, что эту группу можно сопоставлять столько раз, сколько мы хотим. В значительной степени это позволяет совместить несколько каталогов вместе с файлом в конце. Я использовал звезду вместо вопросительного знака, потому что звезда говорит ноль или больше, а не ноль или один. Если бы в нём использовался вопросительный знак, мог быть сопоставлен только один файл/каталог.
Затем завершающая косая черта сопоставляется, но она может быть необязательной. Наконец, мы заканчиваем с концом строки.
Строка, которая соответствует:
http://net.tutsplus.com/about
Строка, которая не соответствует:
http://google.com/some/file!.html (содержит восклицательный знак)
7. Проверка IP Address

Шаблон:
|
1
|
/^(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)$/ |
Описание:
Не буду врать, я не писал это регулярное выражение; я получил это here. Это не значит, что я не могу разобрать его на части.
Первая группа захвата действительно не является захваченной группой, потому что
|
1
|
|
была помещена внутрь, что говорит parser не захватывать эту группу (подробнее об этом в последнем regex). Мы также хотим, чтобы эту незахваченную группу повторяли три раза — {3} в конце группы. Эта группа содержит другую группу, подгруппу и точку. Парсер ищет совпадение в подгруппе, затем точку, чтобы двигаться дальше.
Подгруппа является другой не захваченной группой. Это всего лишь набор символов (нечто внутри скобок): строка «25», за которой следует число от 0 до 5; или строка «2» и число от 0 до 4 и любое число; или нуль или один, сопровождаемый двумя числами, при этом второе является необязательным.
После того, как мы сопоставим три из них, мы переходим к следующей не захваченной группе. Этой нужно: строка «25», за которой следует число от 0 до 5; или строка «2» с числом от 0 до 4 и другим номером в конце; или нуль или один, сопровождаемый двумя числами, при этом второе является необязательным.
Мы заканчиваем это запутанное регулярное выражение с концом строки.
Строка, которая соответствует:
73.60.124.136 (это не мой IP address :P)
Строка, которая не соответствует:
256.60.124.136 (первая группа должна быть «25», а числа от нуля до пяти)

Шаблон:
|
1
|
/^<([a-z]+)([^<]+)*(?:>(.*)<\/\1>|\s+\/>)$/ |
Описание:
Одно из наиболее полезных regexes в списке. Он соответствует любому тегу HTML с содержимым внутри. Как обычно, берём начало строки.
Сначала появляется имя тега. Это должна быть одна или несколько букв. Это первая группа захвата, она очень полезна, когда нам нужно взять закрывающий тег. Следующее — атрибуты тега. Это символ больше (>). Поскольку это необязательно, но я хочу, чтобы они совпадали с более чем одним символом, используется звезда. Знак плюс составляет атрибут и значение, а звезда говорит столько атрибутов, сколько вы хотите.
Затем идет третья группа без захвата. Внутри он будет содержать либо знак больше, некоторый контент и закрывающий тег; или пробелы, прямая косая черта и знак больше. Первая опция ищет знак больше, чем любое количество символов, и закрывающий тег. \1 который представляет содержимое, которое было захвачено в первой группе. В данном случае это имя тега. Теперь, если это невозможно сопоставить, мы хотим найти самозакрывающийся тег (например, тег img, br или hr). Это должно иметь один или несколько пробелов, за которыми следует «/>».
Регулярное выражение заканчивается концом строки.
Строка, которая соответствует:
Nettuts»>http://net.tutsplus.com/»>Nettuts+
Строка, которая не соответствует:
<img src=»img.jpg» alt=»My image>» /> (атрибут не должен содержать знака больше)
Заключение
Надеюсь, вы немного лучше поняли идею регулярных выражений. Надеемся, что вы будете использовать эти regexes в будущих проектах! Вам не нужно постоянно расшифровывать regex символ за символом, но иногда это помогает научиться. Не бойтесь регулярных выражений, они могут оказаться не такими, но сделают вашу жизнь намного легче. Просто попробуйте вытащить имя тега из строки без регулярных выражений!