Это первая статья из серии, посвященной внутренним механизмам Kubernetes. Пользователю или оператору эти детали понимать не обязательно. Но если вы хотите разобраться с тем, как устроен Kubernetes, эта статья для вас.
Поскольку я не планирую заниматься разъяснением основных концепций (таких как Pod, Node, Kubelet), для усвоения материала необходим опыт работы с Kubernetes.
В этой статье мы поговорим о базовых узлах механизма и способах их взаимодействия. Kubernetes обычно относят к классу систем оркестровки контейнеров (container orchestration). Однако оркестровка предполагает некий центральный управляющий элемент и заранее подготовленный план, а Kubernetes работает иначе. Если продолжать использование музыкальной аналогии, то это скорее джазовая импровизация, где группа субъектов исполняет свои роли, взаимодействуя друг с другом и подстраиваясь под поведение других участников.
Начнем с представления базовых компонентов и выполняемых ими задач. После взглянем на типовой процесс планировки и запуска подов (Pod).
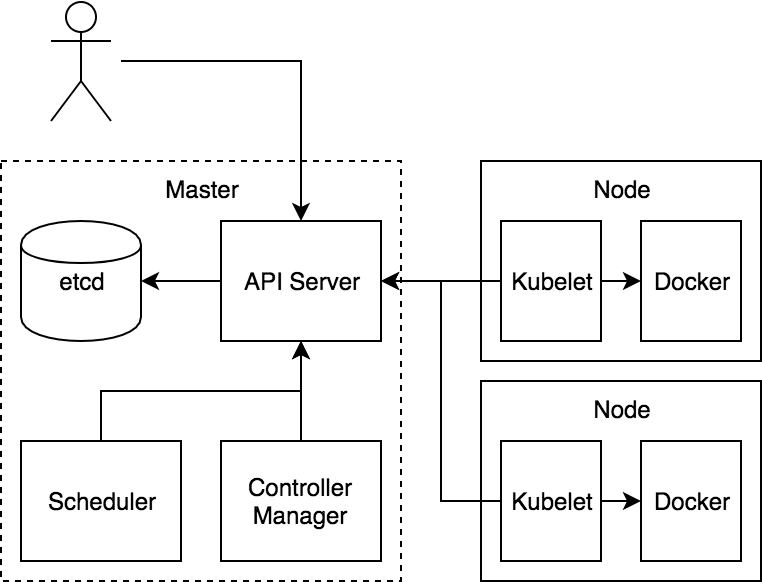
Хранилище: etcd
etcd является в Kubernetes главным хранилищем состояний. Несмотря на то что в разных частях системы есть использующие память механизмы кэширования, именно etcd отвечает за хранение записей.
Краткая сводка по etcd: etcd — это кластерная база данных, в которой согласованность (consistency) считается важнее устойчивости к разделению (partition tolerance). Продукты этого класса (ZooKeeper, части Consul) созданы по образцу разработанной в Google системы под названием chubby. Они часто называются «серверами блокировок» (lock servers), поскольку могут использоваться для координирования процесса блокирования в распределенной системе, хотя я лично считаю, что это название немного сбивает с толку. Модель данных etcd (и chubby) — это иерархия ключей, в которой хранятся простые неструктурированные значения. Это похоже на файловую систему. Что интересно, в Google доступ к chubby осуществляется с помощью абстрактного интерфейса File, который может работать с файлами, хранилищами объектов и т. д. Поскольку во главе угла здесь стоит согласованность, операции записи происходят в строгом порядке, что позволяет клиентам делать атомарные модификации (atomic updates) наборов значений.
Надежное управление состоянием — это весьма непростая задача для любой системы. А в распределенной системе ситуация дополнительно усугубляется использованием таких сложных алгоритмов, как raft или paxos. Полагаясь в этом вопросе на etcd, разработчики Kubernetes могут сконцентрировать внимание на других частях системы.
Идея наблюдения (watch) в etcd (и аналогичных продуктах) очень важна для Kubernetes, где клиенты могут подписываться на изменения частей пространства имен. Как только объект наблюдения изменяется, клиент получает соответствующее уведомление. Эта функциональность может использоваться в качестве механизма координации между компонентами распределенной системы. Например, один компонент что-то записывает в etcd, а другие могут мгновенно на это изменение отреагировать.
Это похоже на pubsub-механизм наоборот. Во многих реализующих очереди системах темы не содержат пользовательские данные, а сообщения, публикуемые в этих темах, содержат большое количество данных. В системах типа etcd ключи (аналог тем) содержат данные, а сообщения (уведомления об изменениях) не содержат большого количества уникальной информации. Другими словами, в очередях темы просты, а сообщения наполнены содержанием, а в системах типа etcd все наоборот.
Обычно клиенты держат в памяти копию части базы данных, реагируя на происходящие в ней изменения. Механизм наблюдения (watch) эффективно поддерживает этот кэш в актуальном состоянии. Если watch по каким-либо причинам не работает, клиент возвращается к механизму опроса сервера (polling), правда, ценой увеличения нагрузки, сетевого трафика и сетевой задержки.
Уровень политик: API Server
В сердце Kubernetes находится механизм с креативным названием API Server. Это единственная часть системы, которая напрямую общается с etcd. Фактически etcd — лишь деталь реализации API Server, поэтому теоретически он может быть заменен на что-то другое.
API Server — это компонент, который отвечает за политики, предоставляя ограниченный доступ к etcd. Его обязанности в определенной степени являются обобщенными и в настоящий момент находятся в процессе расщепления. Это делается для того, чтобы приспособить API Server для управления другими системами.
Основная валюта API Server — это ресурс. Доступ к ресурсам можно получить с помощью простого REST API. Большинство ресурсов имеют стандартную структуру, что позволяет получить дополнительную функциональность. Сама структура API будет описана в одной из следующих статей. Независимо от структуры API Server позволяет различным компонентам создавать, читать, записывать, обновлять ресурсы, а также наблюдать за их изменениями.
Давайте подробнее остановимся на функциях API Server:
- Проверка подлинности и авторизация. Система авторизации Kubernetes имеет модульную структуру. В ней есть встроенные механизмы по проверке подлинности пользователей и авторизации этих пользователей для использования ресурсов. В этой системе также предусмотрены методы для обращения к внешним сервисам (потенциально развернутым в рамках Kubernetes). Такая расширяемость характерна для Kubernetes в целом.
- На API Server выполняются контроллеры приема (admission controllers), которые могут отклонять и модифицировать запросы. Они позволяют применять политики и устанавливать значения по умолчанию. Именно здесь, пока клиент API Server ждет подтверждения запроса, происходит процесс валидации идущих в систему данных. Сейчас контроллеры приема являются неотъемлемой частью API Server, однако уже идет работа по их превращению в еще один механизм расширений.
- API Server также помогает при версионировании API, где очень важно дать представлению ресурса возможность эволюционировать. Поля будут добавляться, объявляться устаревшими, подвергаться реорганизации и трансформироваться иными способами. API Server хранит «правильное» представление ресурса в etcd и трансформирует/воспроизводит этот ресурс в зависимости от версии API. Планирование версионирования и эволюции API было основной задачей Kubernetes с самого начала проекта. Именно этот механизм позволил Kubernetes предложить неплохую политику устаревания (deprecation policy) на довольно раннем этапе своего жизненного цикла.
Важной частью API Server также является идея поддержки концепции наблюдений (watch). Это значит, что клиенты API Server могут использовать такие же способы взаимодействия, как и с etcd. Координация в Kubernetes в основном заключается в том, что один компонент пишет в API Server ресурс, за которым другой компонент ведет наблюдение. Второй компонент имеет возможность отреагировать на изменение практически мгновенно.
Бизнес-логика: Controller Manager и Scheduler
Последняя часть пазла — это код, благодаря которому все и работает. Он реализован в виде компонентов, которые взаимодействуют через API Server и сгруппированы в виде двух серверов: Controller Manager и Scheduler. Их решили разделить, чтобы они не «жульничали». Это позволяет с самого начали обеспечивать расширяемость системы, поскольку базовые ее компоненты должны так же, как и все остальные, общаться через API Server. То, что компонентов всего два, — историческая случайность. Их вполне можно было бы объединить в один большой бинарник или разбить на десяток отдельных серверов.
Эти компоненты выполняют различные функции, необходимые для работы системы. Планировщик (scheduler), например:
- отыскивает поды, не привязанные к нодам (unbound Pods),
- проверяет состояние кластера (кэшированного в памяти),
- подбирает ноду, на которой есть свободное место и которая удовлетворяет другим требованиям,
- привязывает Pod к ноде.
В Controller Manager есть код, реализующий поведение ReplicaSet. (Напомню, что ReplicaSet поддерживает заданное количество одновременно выполняющихся реплик Pod Template.) Этот контроллер мониторит ресурс ReplicaSet и набор подов, основанных на селекторе в этом ресурсе. Он создает/удаляет поды, поддерживая таким образом стабильный набор подов согласно описанию в ReplicaSet. Большинство контроллеров действуют по такому же принципу.
Node Agent: Kubelet
Наконец, есть еще и агент, который устанавливается на ноду. Он, как и любой другой компонент, аутентифицируется на API Server. Агент осуществляет наблюдение за набором подов, привязанных к его ноде, и обеспечивает выполнение этих подов. Если в отношении подов что-то меняется, агент сообщает об этом.
Типовой процесс
Для лучшего понимания работы Kubernetes давайте рассмотрим пример.
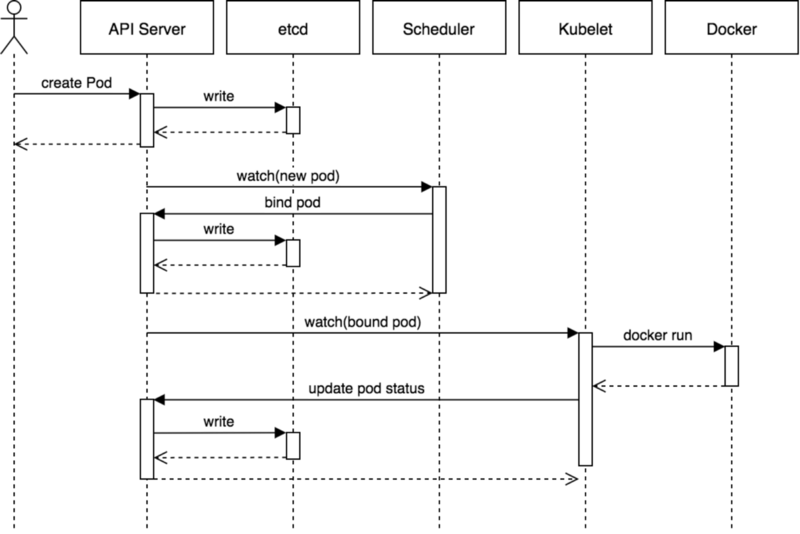
На этой диаграмме показан типичный процесс планирования пода. Здесь, правда, приведено достаточно редкое событие создания пода напрямую пользователем. Обычно же пользователь создает что-то типа ReplicaSet, и уже ReplicaSet создает поды.
Основной процесс:
- Пользователь с помощью API Server создает под, и API Server записывает изменения в etcd.
- Планировщик замечает непривязанный (unbound) под и определяет, на какой ноде его запустить. Эта связь записывается в API Server.
- Kubelet замечает произошедшее в наборе привязанных к его ноде подов изменение и запускает контейнер с помощью соответствующей среды выполнения (например, Docker).
- Kubelet отслеживает статус пода с помощью среды выполнения. Если что-то меняется, он уведомляет об этом API Server.
Итого
Используя API Server в качестве координационного центра, Kubernetes может обеспечивать взаимодействие различных не привязанных друг к другу компонентов. Надеюсь, приведенная информация помогла вам лучше прочувствовать музыкальную аналогию, по которой работа Kubernetes больше похожа на джазовую импровизацию, нежели на выступление оркестра.