Представляете ли вы, сколько нормативных документов в час приходится просматривать корпоративному юристу и к каким последствиям может привести его невнимательность? Бедолага юрист должен вчитываться в каждый договор, тем более, если для него нет типового шаблона, что случается часто.
Глядя в уставшие глаза нашего корпоративного юриста, мы решили создать сервис, который будет находить проблемы в документах и сигнализировать о них задремавшему юристу. В результате мы создали решение с агрегацией знаний по некоторой базе договоров и подсказками юристам, на что следует обратить особое внимание. Конечно, не обошлось без магии. Математической магии под названием Anomaly Detection.
В основном, подходы Anomaly Detection применяются для анализа поведения разнообразного оборудования для выявления отказов, или в банковском секторе для определения фрода. А мы попробовали применить эти алгоритмы для анализа юридических документов. Следуйте под кат, чтобы узнать, как мы это делали.

1. Имеем дело со структурированной информацией
Нам везет, т.к. тексты в договорах достаточно структурированы, сухие и составляются по определенным шаблонам. Для работы над проектом была предложена идея реализовать прототип на базе договоров и контрактов с сайта zakupki.gov.ru (мы добыли 200 000 документов). Для 170 000 договоров нам удалось выделить структуру: преамбулу, главы, пункты и приложения к договору, учитывая ключевые слова, положение в тексте и нумерацию.
2. Разнообразие видов договоров
Необходимо учесть тот факт, что договоры могут быть разных видов. Все они сильно отличаются по содержанию, предмету договора, основным главам и др. Для оптимизации анализа каждого типа договора, необходимо провести работу по их классификации или кластеризации.
Возможно, вы уже знаете, какие виды договоров присутствуют в вашей базе, и знаете признаки, по которым их можно определить. В нашем же случае мы имеем сырой корпус договоров без какой-либо дополнительной информации о каждом договоре и без каких-либо предположений о классификации договоров о закупках. Поэтому мы были вынуждены прибегнуть к кластеризации нашей базы договоров.
Можно реализовать кластеризацию стандартно, используя tf-idf вектор представления документа, но мы решили попробовать алгоритм Doc2Vec, просто ради интереса. При помощи алгоритма Doc2Vec договоры переводились в вектора, а полученные вектора договоров отправлялись на вход алгоритму кластеризации. Мы использовали алгоритм K-means для кластеризации векторов. Поскольку сходство обычно измеряется с использованием косинусного расстояния, мы использовали его вместо евклидова расстояния.
После получения 20 кластеров документов, необходимо было проверить качество кластеризации. Так как какой-либо классификации договоров у нас нет, мы не можем сопоставить полученные кластеры с существующим разбиением. Тогда мы решили посмотреть на слова, которые описывают кластер. Для этого взяли пункты «Предмет договора” для каждого кластера, удалили стоп-слова, числа и слова, встречающиеся в большинстве кластеров. Затем мы выбрали 5 наиболее встречающихся слов для каждого кластера в качестве ключевых слов. Таким незамысловатым способом можно субъективно оценить качество кластеризации.
Примеры слов, которые описывали кластеры:
- арендатор, арендодатель, квартира, арендная, застройщик
- компетентность, преподавательский, образовательный, академический, очная
- генподрядчик, субподрядчик, общестроительный, проектировщик, градостроительный
- аптечный, карантинный, израсходовать, фитосанитарный, герметичный
- детективный, охранник, пресечение, тревога, правонарушение
- лицензиат, сублицензиат, фильм, лицензиар, ретрансляция
- заемщик, депозитный, кредитор, кредит, залогодатель
- централизованный, энергоснабжающий, внутризоновый, водопроводный, канализационный
3. С какими аномалиями мы можем столкнуться в договорах
Давайте определим, какие случаи мы будем считать аномальными и что мы с ними можем сделать. Мы выделили следующие сценарии:
- В договор добавлен лишний пункт, который ранее нигде не встречался в данном контексте. Надо обратить на него внимание юриста.
- В договоре отсутствует пункт, который ранее встречался в подобных договорах. Надо посоветовать юристу его добавить.
- Пункт похож на какой-то пункт из истории, но как-то перефразирован, добавлены или удалены некоторые слова. Можно сообщить юристу и посоветовать правку.
4. В каком виде представить договоры
Как уже упоминалось, договор состоит из глав, главы делятся на пункты, каждый пункт может содержать подпункты и т.д. Для разбиения договора на главы и пункты мы учитывали нумерацию, переносы, ключевые слова: „Глава“, „Статья“ и т.п. Каждый пункт состоит из одного или нескольких предложений. Для разбиения пункта на предложения использовался sent_tokenize из модуля nltk.tokenize.
Сам договор содержит несколько глобальных глав, суть и содержание которых можно узнать по заголовкам: предмет договора, права и обязанности сторон, цена и порядок расчетов… Мы постарались объединить главы с одинаковыми заголовками и работать с различными главами независимо. Названия глав часто перефразированы, имеют опечатки или лишние знаки препинания. Чтобы группы глав получались достаточно большими, мы объединили в одну группу те заголовки, которые были близки по расстоянию Левенштейна.
Одна из проблем, с которой мы обязательно можем столкнуться, это огромный объем именованных сущностей в договорах, которые часто уникальны и могут быть приняты за аномалию. В договорах много таких сущностей, как имена, названия компаний, даты, адреса и т.п., которые меняются от договора к договору. Необходимо такие сущности находить и устранять из договора, т.е. приводить договор к некоторому шаблонному виду. Нам повезло с датасетом, т.к. в выгрузке договоров была большая доля шаблонных договоров, именованные сущности в которых заменены подчеркиваниями. Мы выявили, между какими фразами обычно встречаются подчеркивания, чтобы найти эти фразы в заполненных документах и удалить из них именованные сущности. Понятно, что таким образом мы удалили не все именованные сущности. Поэтому мы еще раз прошлись по корпусу библиотекой Natasha и удалили сущности, которые она нашла.
5. Определение аномальных пунктов в договоре
Мы уже смогли разделить договора по видам при помощи кластеризации и смогли выделить группы похожих глав. Теперь, используя накопленные знания об определенном пункте определенного вида договора, можем понять, что надо исправить в текущем. Давайте для каждого предложения главы посчитаем вероятность его аномальности.
Для каждой группы глав мы храним все предложения, которые мы встретили в нашем тренировочном множестве документов с Госзакупок. Т.к. их довольно большое количество, для каждой группы глав была обучена модель Word2Vec, и каждому предложению сопоставлен вектор взвешенной (по tf-idf) суммы векторов входящих в него слов. Далее вектора предложений были разбиты на кластеры аналогично разбиению векторов для документов.
Теперь, когда к нам приходит предложение, мы определяем, из какого он кластера договоров, из какой группы глав, к какому кластеру предложений он ближе всего и в данном кластере находим ближайшее. Расстояние до ближайшего предложения можно расценить как меру того, насколько данное предложение аномально. Если расстояние до ближайшего предложения нулевое, то наше предложение не аномально. При увеличении данного расстояния мы все больше сомневаемся в том, что предложение аномалий не содержит. Скорее всего с ним что-то не так.
6. Что делать с пунктами, которые отсутствуют
Мы придумали, как находить аномальные пункты в договоре, но не научились находить аномалии в виде недостающих предложений или пунктов. Такую аномалию можно легко найти, если у нас на руках есть шаблон данного типа договора, но, например, бывают случаи, когда другая компания нам прислала договор, составленный по собственному шаблону.
Для обнаружения таких аномалий нам необходимо сформировать шаблон для договора с набором обязательных предложений/пунктов, опять же основываясь только на имеющейся у нас базе договоров.
Мы придумали и протестировали алгоритм построения шаблона. Данный алгоритм предполагает, что в нашей базе договоров имеется похожая глава с правильным набором пунктов, которую мы хотим выявить и указать в качестве шаблонной.
Алгоритм:

- На каждой группе глав заранее обучить модель на основе алгоритма MinHashLSH, которая позволяет быстро находить близкие тексты.
- Для каждой главы загруженного договора найти список близких к нему параграфов из базы.
- На основе полученных близких параграфов построить языковую модель и выбрать в качестве шаблонного параграф с наибольшей вероятностью, предсказанной языковой моделью.
Получив шаблон для каждой главы, можем выявить недостающие пункты, которые присутствуют в шаблоне, но отсутствуют в текущем договоре, и посоветовать юристу добавить их.
7. Полный пайплайн
Подведем итоги и соберем все шаги вместе:
8. Оценка качества
Для оценки качества решений задачи был сформирован тестовый набор договоров. В договоры были искусственно добавлены аномалии в виде удаления части слов, вставки слов/словосочетаний в предложения, вставки предложений из других глав, удаления предложений. Мы оценили качество для каждого типа аномалий и получили следующие распределения ошибки определения:
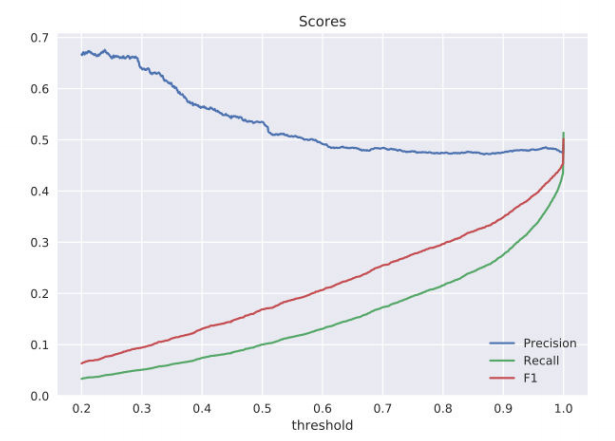
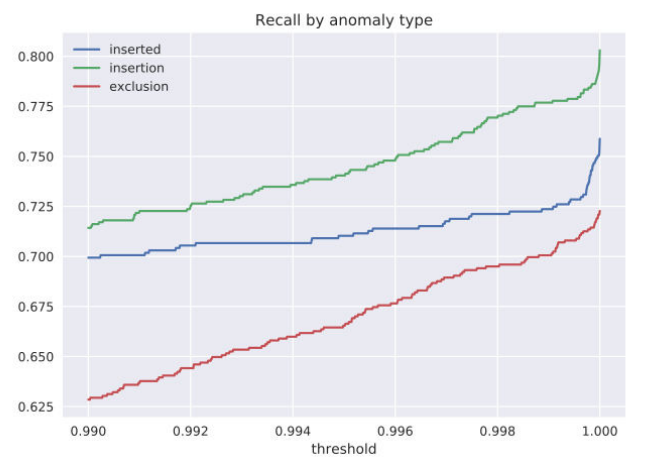
То есть предложенный алгоритм позволяет определить некорректные включения в 4 из 5 случаев. Следует отметить, что с увеличением объема обучающей выборки и кластеризации договоров по разным типам, мы можем получить улучшение этой оценки.
9. Визуализация
Для визуализации такого решения задачи был реализован веб-интерфейс, в который можно загрузить новый договор, текст которого отобразится на странице и аномальные предложения будут выделены цветом. Чем темнее цвет предложения, тем сильнее мы уверены, что оно аномальное. Т.к. мы нашли ближайшее предложение, мы советуем правку для пользователя в виде этого ближайшего предложения, или же советуем изменить конкретную часть предложения, если ближайшее имеет небольшую разницу с исходным.

10. Где применимо?
Практическое применение получившегося сервиса наиболее целесообразно в тех случаях, когда требуется «потоковая» экспертиза юридической чистоты большого количества однотипных документов: например, при выдаче залоговых кредитов населению (ипотека, автокредитование и страхование). Например, в случае ипотеки – это договоры купли-продажи недвижимого имущества, договоры страхования недвижимости и заемщика, договоры оценки объекта и т.п. – сотни страниц текста в досье каждого клиента, которые могут быть практически мгновенно проанализированы, и аномальные места будут «подсвечены» юристу для анализа на предмет рисков или фрода.
Так что, совсем без юристов из плоти и крови пока не обойтись, но облегчить им жизнь современные технологии позволяют.