Гризли казино — официальный сайт, вход и зеркало
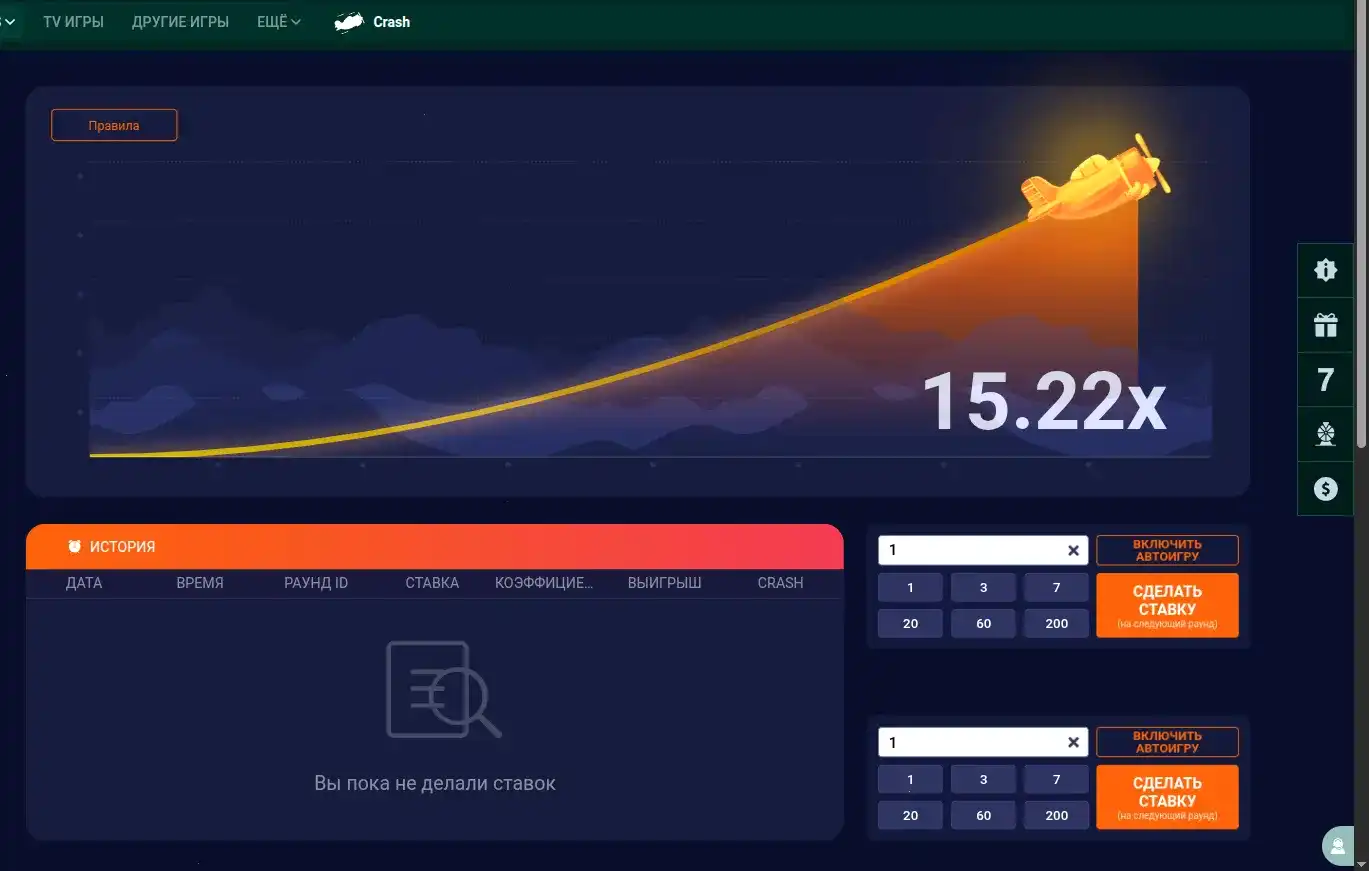
Казино Гризли (Grizzly casino) — это свежий взгляд на слоты и live-игры. Более 1200 автоматов от топ-провайдеров, молниеносные выплаты и щедрые бонусы. Хочешь крутить? Мы уже загрузили зеркало для входа без блокировок. Играть можно с телефона или ПК — адаптация огонь.
🔥 Топовые автоматы: крути и выигрывай










🎁 Приветственные подарки и еженедельный кэшбэк
За регистрацию на Гризли казино официальный сайт дают 100% на первый депозит + 50 фриспинов на Book of Oil. А если вносишь от 50$ — ещё и 250 фриспинов на Power of Merlin Megaways. Акции обновляют каждую неделю, по пятницам — кэшбэк 15% без отыгрыша. Да, ты не ослышался. Вывести можно сразу, если прошел верификацию.
По опыту игроков, лучше всего активировать бонус в середине недели — меньше загруженность саппорта. Кстати, для хайроллеров есть индивидуальные условия: кешбэк до 25% и персональный менеджер. Всё по-взрослому.
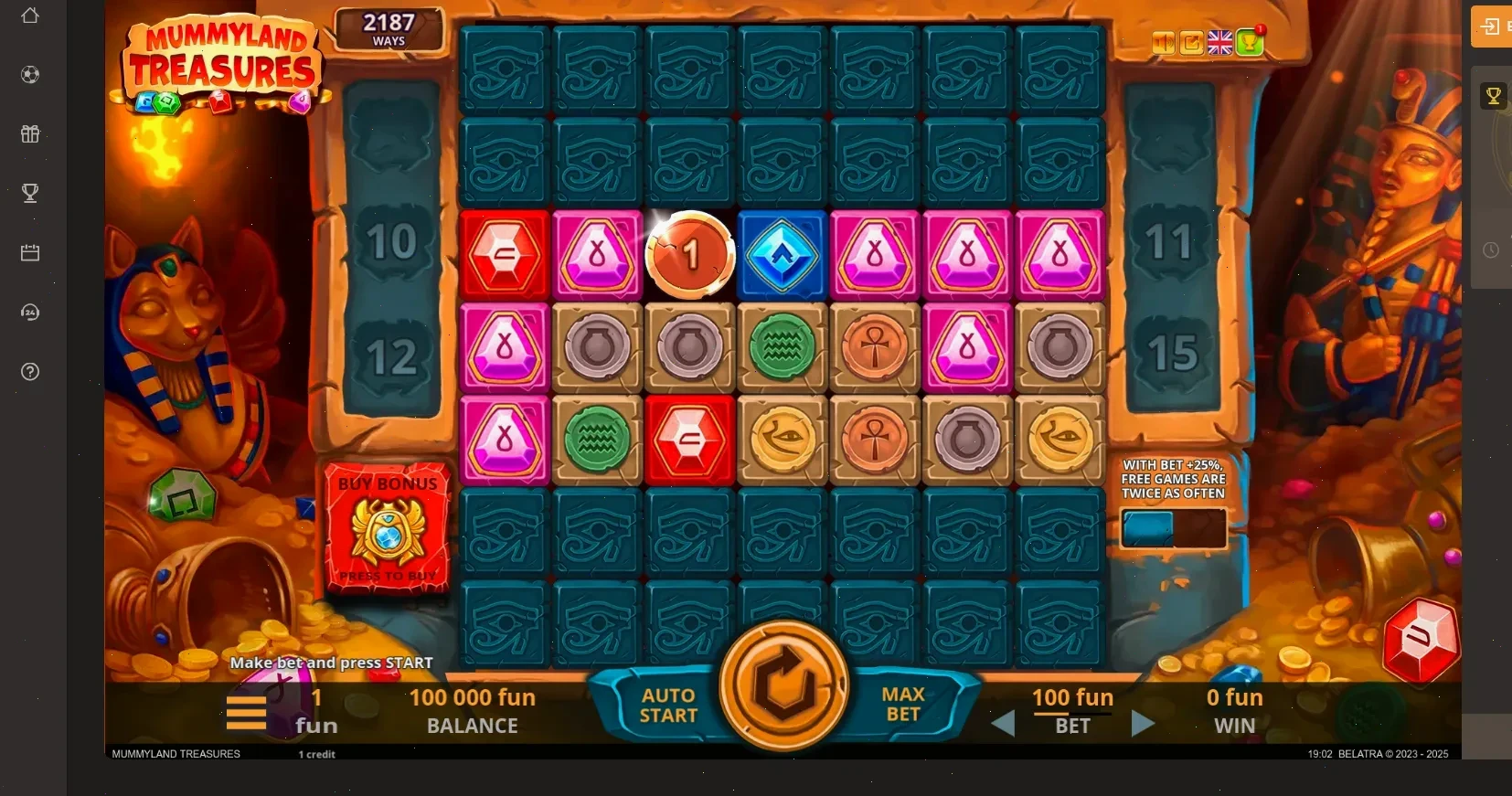
🔐 Как зарегистрироваться и войти на Grizzly casino
Вход в Гризли казино — дело двух минут. Жмёшь «Регистрация», вводишь почту или номер телефона, придумываешь пароль. Верификация понадобится только при первом выводе. Зеркало для входа нужно, если провайдер блокирует сайт — но мы уже добавили актуальный адрес в разделе «Зеркало» (внизу страницы).
Многие игроки отмечали, что удобнее заходить через Telegram-бота — он присылает свежую ссылку автоматически. Гризли казино регистрация занимает меньше минуты, а после неё сразу можно крутить слоты. Без лишних писем и подтверждений.
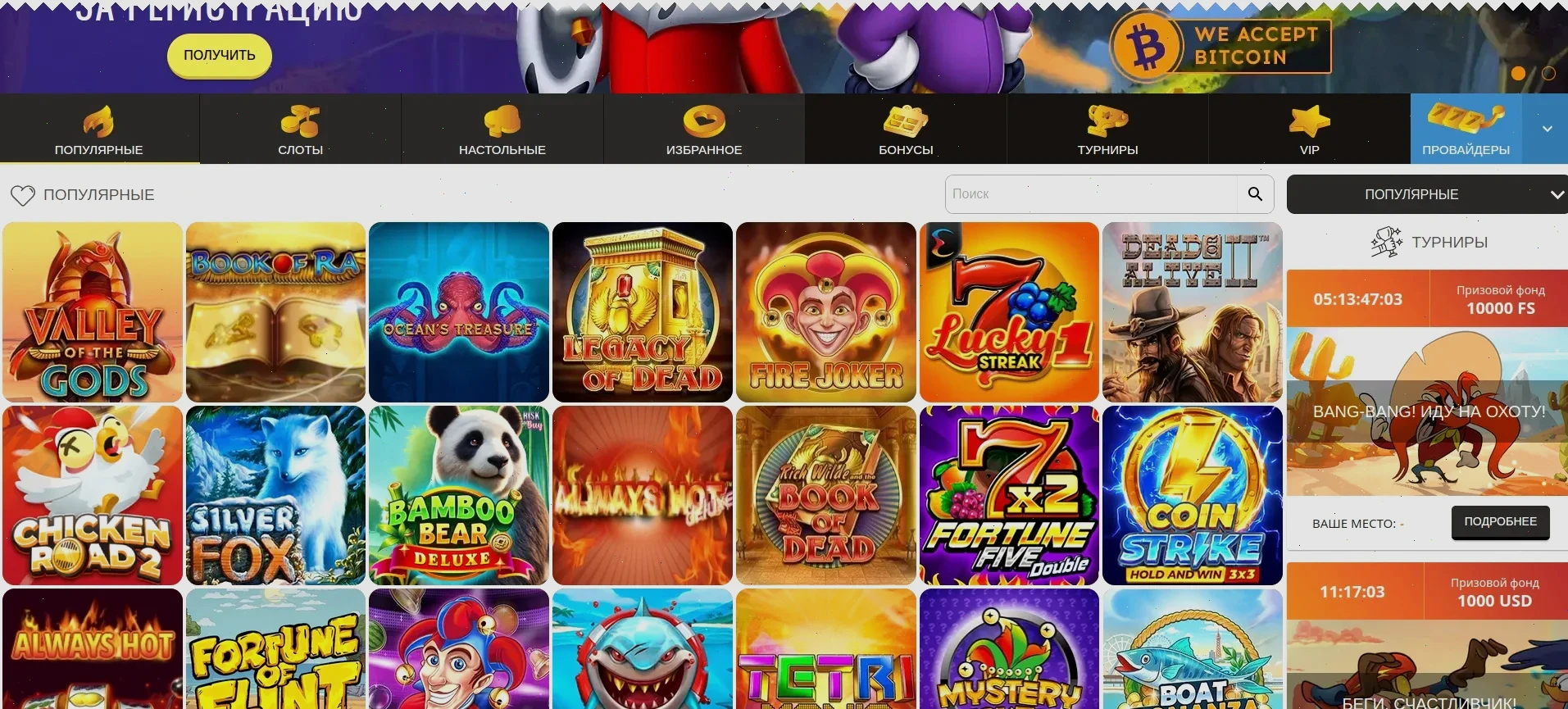
🏆 Grizzly club: турниры и ежемесячный лидерборд
Мы придумали Гризли-клуб — это закрытое комьюнити активных игроков. Участвуешь в турнирах каждую неделю, зарабатываешь очки опыта. Топ-10 получают денежные призы и фриспины без вейджера. В марте 2026 призовой фонд — $20 000. Заходи в раздел «Турниры» после входа на сайт. Лидерборд обновляется в реальном времени.
Ещё одна фишка — бонус за уровень. Достиг 5-го уровня — получил 100 фриспинов на любой слот. Без депозита. Просто за активность.
💬 Живые отзывы игроков
❓ Часто задают: ответы на злободневное