Добрый день, %username%. Меня зовут Антон Резников, я работаю над проектом Облако Mail.Ru Сегодня я хочу рассказать о технологиях балансировки трафика, проиллюстрировав историей о развитии социальной сети. Все персонажи выдуманы, а совпадения почти случайны. Статья обзорная, составлена по следам доклада на Highload Junior 2017. Некоторые вещи могут показаться элементарными, но опыт проведения собеседований показывает, что это не совсем так. Кое-что будет спорным, не без этого.
Что нужно для балансировки трафика? Как ни странно, это не серверы и не сетевое оборудование, а, в первую очередь, источник трафика, эффективный, легальный. И без возрастных ограничений. Нам идеально подойдут котики, их одобряет даже РКН.
Команда
Далее нам нужна команда профессионалов.
Познакомьтесь. Слева менеджер Майк. Амбиции — его второе имя. Справа программист Павел, он немного перфекционист и очень любит писать красивый код, а ещё больше его переписывать. В центре администратор Тони, он в меру ленив, но ответственен и профессионален.

План
И последнее, нам нужен план! Мы будем говорить о запуске социальной сети для любителей постить и смотреть фотографии котиков net.cat. План амбициозен и достаточно прост.

Мы начнём с запуска бета-версии по инвайтам. Далее захватим Москву, через нее пойдем на Россию, а там и до мирового господства рукой подать.
Beta
В качестве платформы был выбран LAMP (Linux, Apache, MySQL и что-нибудь на букву P). В данном случае нас более всего интересует Apache, потому что он использует модель prefork.

Почему pre и почему fork? Каждый процесс обрабатывает единовременно только одно пользовательское соединение. Но нам невыгодно запускать процесс во время установки соединения, поэтому процесс запускается заранее и обрабатывает несколько соединений.
Многие из вас скажут: «Да, но Apache — это же не модно и не эффективно». Но под Django или PHP FPM лежит та же самая модель.
Как много воркеров (worker) мы можем запустить? Получить оценку сверху достаточно просто, нужно взять размер свободной оперативной памяти, поделить его на максимальный размер воркера, и мы получим некое N, повышать которое крайне нежелательно.
Как много RPS мы можем получить с одного сервера? Мы берем количество воркеров и делим на среднее время обработки запроса. Нетрудно заметить, что при увеличении времени обработки запроса, например, если ваш MySQL немного притормаживает, RPS падает.

Первый вызов
Итак, Павел запустил прототип сети на своем компьютере.

Страница получилась достаточно легкой, но содержащей большое количество мелких файлов. Павел любил раскладывать всё по полочкам. Затем сайт был выгружен на тестовый сервер, чтобы показать его менеджеру, отдыхающему в Таиланде. К сожалению, сайт работал на тестовом сервере сильно медленнее, чем на локальном компьютере. Давайте разберемся, почему.

Каждый браузер имеет лимит на количество соединений к одному HTTP-хосту. Этот лимит сильно разнится, так как до недавнего времени RFC имел явное ограничение (RFC 2616 8.1.4), и с недавнего времени формулировка заменена на очень обтекаемую — «разумное количество соединений». Этим, например, воспользовались разработчики Internet Explorer. Но подождите, у нас всё ещё есть канал 100 Мбит, который стоит не очень дешево. Неужели провайдер нас обманывает?
Нет, не в этот раз.
Давайте рассмотрим процесс передачи файла на примере файла lapka.png.

Чтобы передать данные по сети, файл нужно разбить его на пакеты. В реальности это происходит прямо при записи HTTP сервером данных в сокет, но ради красивой картинки мы разбили его заранее. Первое, что должен сделать клиент — установить соединение. Это происходит в виде так называемого трехступенчатого TCP-рукопожатия, и тратится на это около одного round-trip, или пинга (ping). Также на этой стадии передаётся сам запрос (в нашем примере запрос достаточно мал).
Далее сервер должен отправить данные. Но сколько пакетов отправить? Насколько широкий канал у клиента? Мы пока этого не знаем, поэтому сервер начинает с небольшого количества пакетов, так называемого TCP-окна, и отправляет их клиенту.
В данном случае — два пакета. В реальности их побольше. Если не ошибаюсь, в современных Linux стоит значение 10. Получив подтверждение от клиента, сервер понимает, что канал не перегружен, и отправляет больше данных, расширяя тем самым окно. На последнем этапе он отправляет последний пакет. После этого соединение нужно ещё закрыть.

Примерно так выглядит изменение ширины TCP-окна с течением времени в рамках одного соединения. В этом примере мы предполагаем, что потери обусловлены только перегрузкой канала. Поэтому со временем размер TCP-окна достигает максимума и колеблется около этого значения. Форма колебания зависит от алгоритма выбора окна. Это идеальный случай. В реальности очень часто размер окна будет просаживаться из-за того, что где-то на магистральных каналах происходят пиковые нагрузки и пакеты теряются.
Из всего этого вытекает простое соотношение: вы не можете передать через одно соединение данных больше, чем длина TCP-окна, делённая на пинг.
Именно поэтому с локальной машины сайт работал быстро, а из Таиланда — очень медленно. Именно поэтому популярны разного рода менеджеры скачивания, которые скачивают большие файлы в несколько потоков.
Тони быстро нашел решение — был включён Keepalive. Но что поменялось? Для первого запроса всё осталось на прежнему. Мы так же устанавливаем соединение, так же передаем данные, так же расширяем TCP-окно, но не закрываем соединение.
А через некоторое время, если не истек таймаут на Keepalive, браузер может снова воспользоваться этим соединением, уже установленным, уже разогретым, с более высокой скоростью передачи данных.
Внимательный читатель может заметить, что Keepalive в Apache включен по умолчанию в 99.9% случаев. Всё так. Но всё не так однозначно, когда тебя зовут Тони и у тебя лапки.

Keepalive не панацея
Итак, Майк был очень доволен результатом и решил приступить к бета-тестированию.

Зря. Что-то пошло не так, и очень скоро пользователи, получившие инвайты, начали жаловаться на проблемы с доступом к сайту.
Мы всё ещё используем Apache и prefork-модель. При включённом Keepalive пользователи не разрывали соединение, в результате даже небольшое количество клиентов полностью исчерпывали количество воркеров, и новые клиенты не могли установить соединение.

Тони был очень недоволен тем, что Майк не предупредил его о запуске, но он быстро нашел решение. На самом деле, он давно хотел установить Nginx, но проклятая прокрастинация не давала это сделать.

Что же изменилось? Nginx использует другую модель обработки запросов. Один его воркер может вытянуть тысячи, и даже десятки тысяч соединений, и воркеров можно запустить много. И даже медленные клиенты, которые раньше нагружали наш сервер, не будут создавать нам проблемы, так как ответ от Apache будет считан в буфер Nginx и отдан с требуемой скоростью. В результате Nginx превратил множество соединений от пользователей в минимально необходимое количество запросов к Apache.

Москва
Окей, пора идти на Москву. Для начала нужно увеличить количество серверов. Тони выбрал схему балансировки через DNS.
Как это происходит? К нашему DNS-серверу обращается пользователь и спрашивает: «А что за адрес у этой замечательней социальной сети net.cat?». Сервер ему отдает два IP-адреса, после чего клиент случайным образом выбирает себе сервер и отправляет запросы. За счет того, что клиентов много и особой закономерности в выборе сервера нет, мы получаем равномерно размазанную нагрузку.

Как много серверов можно балансировать при такой схеме?
Согласно действующему ныне RFC 1123, DNS-сервер должен поддерживать UDP и передавать через него данные размером не более 512 байтов. TCP желательно поддерживать, но необязательно, чем пользуются многие системные администраторы. На самом деле, обязательно с 2016 года, но вспомните про IPv6, и попробуйте спрогнозировать, когда это требование стандарта воплотится в жизнь.

Согласно тому же стандарту, мы должны потратить 16 байтов на одну А-запись, и около 100 байтов на заголовок. Итогом получаем максимум 25 серверов при использовании UDP.
Но есть нюанс.
Клиенты почти никогда не обращаются к нашему серверу напрямую. Обычно между нашим сервером и клиентом есть DNS-сервер провайдера, роутер клиента (router в оригинали произносится как [ˈruːtər]), возможно, ещё локальный кеширующий DNS у него на машине. Поэтому крайне редко кто-либо масштабирует таким образом более четырех-шести адресов.

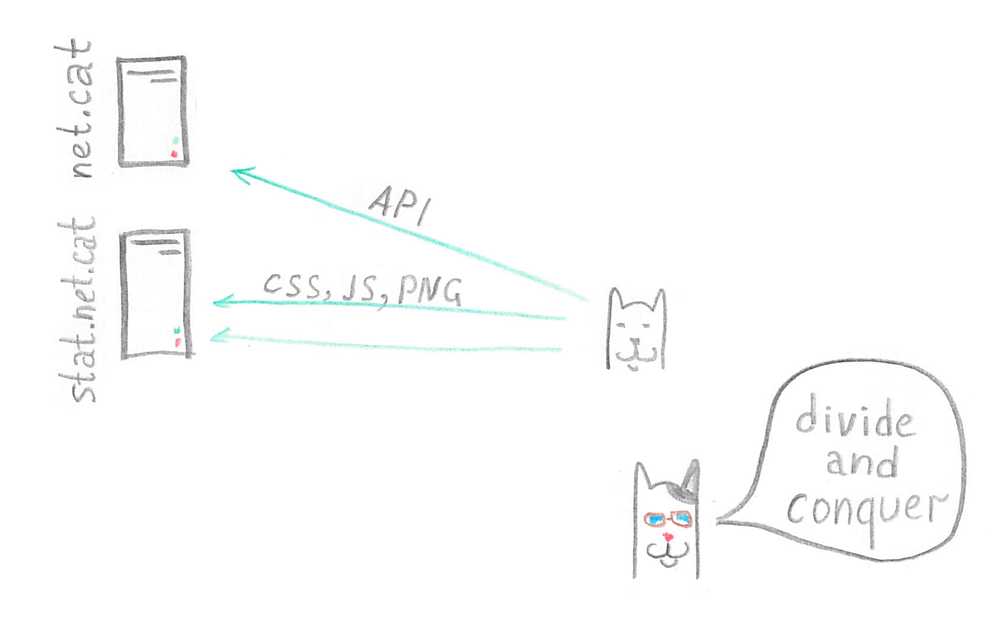
Кроме того, при балансировке серверов таким образом встал вопрос: что делать с картинками?

Во-первых, не хотелось бы хранить их в четырёх копиях, а именно четыре сервера планировал поставить Тони. К тому же при передаче картинок соединения с сервером «забивались», и маленькие запросы к API вынуждены были ждать своей очереди достаточно долго — сайт становился менее отзывчивым. Поэтому статика и клиентский контент были вынесены на отдельный сервер. Это не только позволило сэкономить на дисках, но и увеличило скорость работы сайта.

Загадочный сбой
Итак, сервис работал на четырёх серверах, поддерживающих API, но однажды ранним утром понедельника сервер «дельта» ушёл и не вернулся.
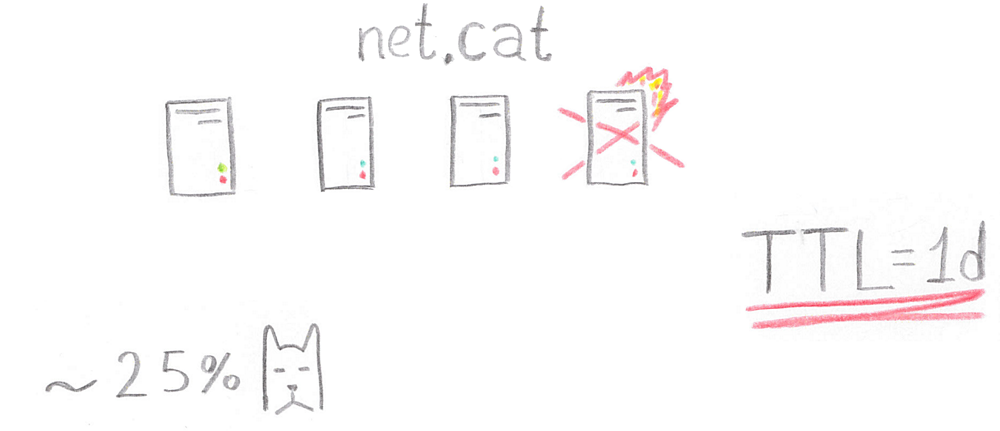
Хуже того, TTL (а это время, в течение которого клиенты могут не перезапрашивать информацию об IP-адресах сайта) имел продолжительность в один день. 25% пользователей начали испытывать проблемы с доступом к сайту.
Тони вызвонил дежурного специалиста из дата-центра и попросил поднять любой сервер с этим IP-адресом, чтобы проксировать запросы с поднятого сервера на рабочие серверы с Apache. Но как только сервер был поднят, проблема тут же исчезла сама собой.
Что же произошло?
Любой современный клиент способен перебрать все адреса из ответа от DNS-сервера. Если ваш сервер лежит и не отвечает, в течение таймаута на соединение клиент будет ждать: а вдруг сервер ему ответит. Если, как в нашем случае, сервер поднят, но на нём не запущен никакой веб-сервис, и никто не принимает соединение на 80-м порту, клиент получает отказ практически за время, равное одному пингу. После чего клиент прозрачно для пользователя идет на другой сервис.

Котики v.s. Собаки
Собаководы очень не любили эту социальную сеть. Как это: котики, котики, котики, и ни одной собаки? И однажды они обнаружили, что поисковые запросы работают очень медленно. Они подумали: «А что, если мы натравим Apache Benchmark (это утилита для тестирования производительности вашего сервиса) на эту социальную сеть?». Ведь утилита не спрашивает, ваш вы сайт тестируете или нет. Так они и сделали. Сгенерировали большое количество запросов к методу API Search, и серверам стало плохо. MySQL замедлялся, и всё шло к тому, что сайт в скором времени должен был полностью «лечь». Хуже того, так как на тех же серверах хранилась куча статики — JS, CSS-файлы, — нельзя было использовать лимиты на коннекты. Клиенты не смогли бы быстро загрузить статику.

На самом деле с netfilter можно было решить проблему, но какой администратор ранним утром в понедельник сможет его настроить? Nginx также не умеет работать с лимитами на путь. А реализовывать софтверные лимиты, когда ваш сервер пытаются положить, уже поздно.

Поэтому Тони принял волевое решение: лучше потерять одну функцию, чем все, и поиск был отключён. А по результатам инцидента Тони и Павел решили перевести всю статистику на отдельный сервер. Это не только упростило жизнь Тони, так как теперь он мог легко лимитировать количество запросов, но и увеличило скорость доступа к сайту.
Покоряем Россию
Начнем с переезда в новый дата-центр с хорошим SLA. Тони предусмотрительно выставил TTL на зоне в пять минут, и рассчитывал, что в течение 10, максимум 30 минут все пользователи перейдут с IP-адресов старого дата-центра на IP-адреса из нового дата-центра.

Как бы не так.
Значительная часть пользователей так и продолжала пользоваться старыми DNS-серверами, что, между прочим, влетело в копеечку. Менеджер Майк вынужден был заплатить за две дополнительных недели аренды. И он требовал объяснений.

История оказалась проста и занятна. В городе было три популярных провайдера.

Один из них, Cat Telecom, не вносил никаких изменений в трафик, и с ним было всё хорошо. Evil Telecom экономил на трафике, поэтому все запросы к DNS были принудительно закэшированы на один день. School Telecom экономил на системных администраторах, поэтому бо́льшая часть их конфигурационных файлов представляла собой компиляцию со Stack Overflow, и кэширование загадочным образом было настроено в одну неделю.

Раздача контента
Также встал вопрос с серверами контента пользователей. Фотографий было много, и их нельзя было хранить на одном сервере, поэтому было решено купить ещё два.
Как же балансировать нагрузку между ними? Тони и Павел долго спорили. Тони предлагал распределять запросы редиректами, ведь стороне сервера известно, где лежит файл, мы можем направить клиента на нужное хранилище.

Павел не хотел создавать новый сервис, так же он резонно заметил, что такой способ не подходит для аплоада. Он предложил отдавать клиенту полный адрес картинки, а алгоритм выбора хранилища на клиенте. Задача алгоритма забрать список доступных для загрузки серверов и выбрать один для загрузки картинки, случайным образом, либо хешируя ID клиента.
Тони вежливо напомнил про 307 редирект, но согласился что с POST-запросами он работает на всех клиентах. Тем не мене, он был категорически против решения на JS. Тони нужна была возможность перемещать данные, выводить сервера из нагрузки и добавлять новые. Не смотря на то, что Павел обещал всё это предусмотреть, Тони на отрез отказался принимать в эксплуатацию код, работающий «где-то там». Мы можем управлять только тем, до чего дотягивается лапка — сказал Тони.

Не мало времени было потрачено, но друзья пришли к компромиссу. Сервера с контентом скрыли за слоем прокси, которые «знали» куда идти за определённой картинкой и какой сервер лучше выбрать для сохранения новой. На JS оставили выбор прокси-сервера, их список периодически запрашивался с сервера, что позволяло достаточно быстро убрать новые соединения с прокси-сервера и вскоре вывести его из нагрузки незаметно для пользователей. Схема позволяла, при необходимости настроить кэш для особо горячего контента, а так же перейти к хранению нескольких копий файлов. Тони был доволен до кончика хвоста.
Балансировка API
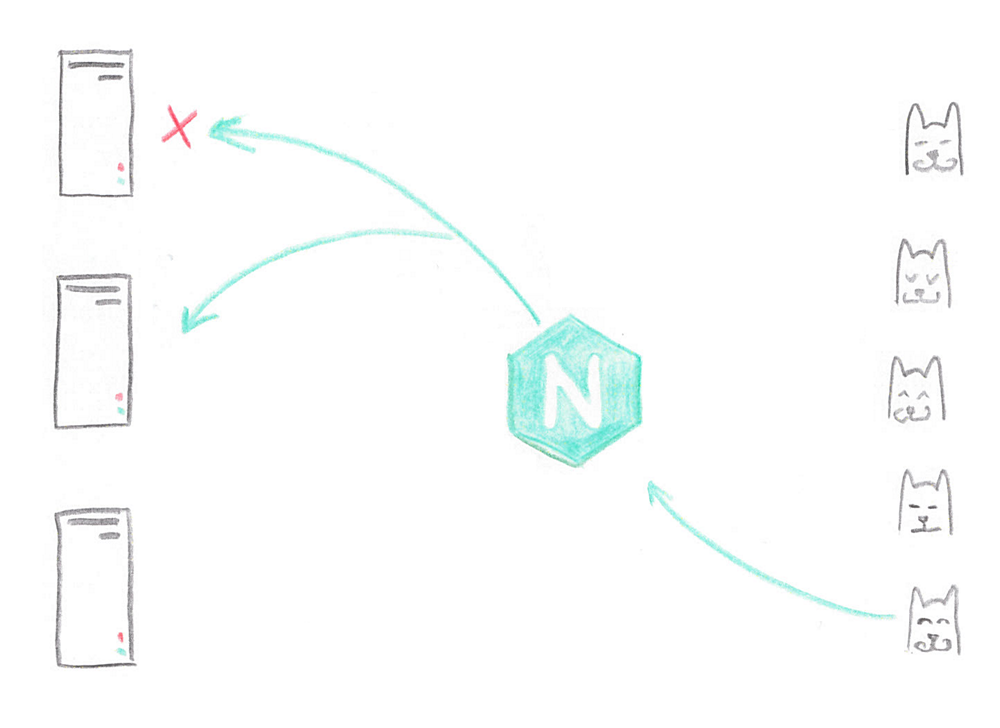
Также встал вопрос о масштабировании серверов под API. Никто не хотел 20 серверов забивать DNS, поэтому Тони выделил отдельные серверы, назвав их балансерами, и поставил там Nginx.

Nginx равномерно распределял запросы между серверами с Apache, всё шло замечательно. Более того, если по каким-то причинам один из серверов ломался, Nginx прозрачно для пользователя перенаправлял запрос на другой работающий сервер. Тони нравилось.
Query of DEATH
Часто в высоконагруженных проектах тяжелая логика реализуется на языках более низкого уровня. Так было и в нашем случае. Специальный код для добавления стикеров на фотографиях был написан на C++. К сожалению, одно из исключений не было обработано, и, получив «битый» jpeg, такой код падал вместе с воркером.

Что же делал Nginx? Решив, что сервер сбойный, Nginx помечал его на 10 секунд как недоступный, и переходил к новому серверу. Баг замечательно воспроизводился на всех серверах кластера, пока хоть что-то работало. После чего сайт становился недоступен на 10 секунд.

Тони кусал себе локти. Он был очень недоволен, но понимал, что дело не в Nginx, а в том, что он не достаточно внимательно прочитал документацию. Нужно было всего лишь ограничить количество попыток обращения к другим серверам. Достаточно было двух, максимум трёх. Зачем обходить весь кластер? Так Тони и сделал. А также решил, что после одной ошибки сервер ещё рано помечать как сбойный.
Резервируем nginx
У нас осталась ещё одна точка отказа — это сам сервер с Nginx.
Если что-то идет не так — уборщица в дата-центре запинается о кабель, или перегорает блок питания, — сайт становится недоступен примерно для половины пользователей. Тони решил, что VRRP спасёт ситуацию.

Это решение, в котором есть так называемый VIP (Virtual IP), который обслуживает два сервера: master и backup. Master обслуживает запросы всегда, backup — если что-то пошло не так.

К сожалению, эта схема требовала наличия L2-сети между серверами, да и Тони недавно купил новое оборудование фирмы «Киса». Поэтому он решил переделать схему для работы с IBGP. На самом деле он мог использовать и другой протокол, например, OSPF. В этой схеме уже не требовалось наличие L2-сети между серверами, но так же был Virtual IP, который анонсировался двумя серверами с разной метрикой. Если master работал, то трафик шел на него, так как он анонсировал IP с меньшей метрикой. Если что-то шло не так, то backup принимал на себя нагрузку.

А вы бывали в Рио?
Майк грезил Рио-де-Жанейро. Полтора миллиона человек, и все поголовно в белых штанах! Поэтому экспансию решили начать с Бразилии. Для увеличения отзывчивости сайта были подняты серверы в Рио-де-Жанейро, а трафик от пользователей распределялся с помощью geoDNS. Всё шло хорошо, но некоторые пользователи из России попадали в Бразилию. Точнее, попадали не пользователи, они не возражали бы против такого расклада. Попадали их запросы. И сайт у них работал сильно медленнее, чем у тех, чьи запросы попадали в Россию. В основном это было вызвано использованием клиентами публичных DNS серверов, но иногда случалось из-за недостаточно быстрого обновления базы geoDNS.

Схема, в принципе, рабочая, но требует активной поддержки. Поэтому Тони, в силу своей лености, решил применить менее хлопотное решение.
Была куплена автономная система. Это набор IP-адресов, которые управляются одним администратором. Под администратором подразумевается не сисадмин, а некая организацию, которая покупает данный набор адресов.
Автономная система поднимается в нескольких местах и анонсируется соседям, с которыми мы должны договориться о покупке каналов. В данном случае это три точки. После чего клиент может обратиться к любой из точек, где поднят нужный IP-адрес. Но маршрут от клиента выбирает не он, маршрут выбирает в первую очередь провайдер. Провайдер пользуется всё тем же BGP (теперь без I), и его оборудование выстраивает маршруты для всех адресов в интернете. Если адрес доступен из нескольких мест, то выбирается маршрут с наименьшей метрикой.

Как правило, это количество пройденных автономных систем между источником и получателем. Если не сильно вмешивается политическая конъюнктура, то трафик пройдет кратчайшим маршрутом. Если клиент находится где-нибудь в Подмосковье, то у него практически нет шансов попасть на другие серверы вне Москвы.
Если договориться с соседями (соседними автономными системами), то трафик через них может пойти со всего мира. Так и было сделано. Автономная система была поднята в трёх точках. С VIP достаточно было отдать клиенту одну HTML страницу, в которой были прописаны сервера с API, статикой и контентом в Рио, в Москве или Нью-Йорке.
Пользователи из Москвы начали попадать на серверы в Москве, а пользователи из Бразилии — на серверы в Рио-де-Жанейро. А если упадет дата-центр в Москве, то BGP-сессии с соседями будут разорваны, и более они не будут видеть маршрута к нужным IP в этом месте. Пожалуй, Нью-Йорк в данном случае намного ближе, чем Бразилия, и трафик пойдет туда. Естественно, всё будет работать медленнее.
Эпилог
Майкл привел свою команду к намеченной цели. А к чему пришли мы? Позволю себе озвучить несколько простых истин, немного нудно, но максимально коротко.
Не ищите универсального решения, лучшее враг хорошего.
Имейте план B, а лучше B, C и т.д. Ломается всё, если не сломается у вас, то сломается у соседей, но узнают они об этом от вас…
И не пренебрегайте документацией, как бы банально это не звучало.
