Вот уже около трех лет я использую в работе принципы Spec By Example, Domain Driven Design и CQRS. За это время накопился опыт практического применения этих практик на платформе .NET. В статье я хочу поделиться нашим опытом и выводами, которые могут быть полезными командам, желающим использовать эти подходы в разработке.
DDD. Выводы
- ОЧЕНЬ дорого
- Работает хорошо в устоявшихся бизнес-процессах
- Иногда – это единственный способ сделать то, что нужно
- Плохо масштабируется
- Сложно реализовать в высоконагруженных приложениях
- Плохо работает в стартапах
- Не подходит для построения отчетов
- Требует особого внимания с ORM
- Слова Entity лучше избегать, потому что его все понимают по-своему
- С LINQ стандартная реализация Specification «не работает»
Очень дорого
Все руководители разработки, применяющие DDD, с которыми я обсуждал тему, отметили «дороговизну» этой методологии, в первую очередь из-за отсутствия в книге Эванса ответов на практические вопросы «как мне сделать FooBar, не нарушая принципов DDD?».
Самый распространенный в гугл-группе CQRS, вопрос по словам Грега Янга: «Босс просит меня построить годовой отчет. Когда я поднимаю в оперативную память все корни агрегации у меня начинает все тормозить. Что мне делать?». На этот вопрос есть очевидный ответ: «нужно написать SQL-запрос». Однако, написание ручного SQL-запроса – это однозначно против правил DDD.
Сам Эванс согласился с Янгом в том, что книгу следовало бы написать в другом порядке. Ключевыми являются концепции Bounded Context и Ubiquitous Language, а не Entity и ValueObject.
Отчеты не нуждаются доменной модели. Отчет – это просто таблица с данными. Data Driven – гораздо лучше подходит для отчетов, чем Domain Driven. На первый взгляд в этот момент нужно сказать DDD sucks. Однако, это не так. Просто применение DDD для построения отчетов – не верный Bounded Context.
Bounded Context
Самый важный тезис DDD – не следует пытаться разрабатывать одну большую доменную модель для всего приложения. Это слишком сложно и никому не нужно. Создать одну доменную модель для всего приложения возможно, только если на уровне управления компанией принято решение о том, что все отделы используют единую терминологию и понимают все бизнес-процессы одинаково.
Entity все понимают по-своему
Мы убедились в том, что очень сложно договориться со всеми членами команды о терминологии. Камнем преткновения стал термин Entity: мы пытались использовать интерфейс IEntity<TKey>, однако быстро поняли, что Id могут использовать и ValueObject’ы для передачи команд. Использование IEntity<TKey> для таких объектов путало людей, и мы отказались от IEntity в пользу IHasId.
DDD требует особого внимания с ORM
На Stack Overflow довольно много обсуждений NHibernate vs Entity Framework for DDD. NHibernate, в целом, справляется лучше, но проблем остается много. Стандартный подход при использовании ORM – использование беспараметрических конструкторов и установка значений через сеттеры свойств. Это разлом инкапсуляции. Есть определенные проблемы с коллекциями и Lazy Load. Кроме этого, команда должна принять решение о том, где заканчивается «домен» и начинается «инфраструктура» и как обеспечить Persistence Ignorance.
С LINQ стандартная реализация Specification «не работает»
Эванс – человек из мира Java. Кроме этого книга была написана достаточно давно.
public abstract class Specification<T>
{
public abstract bool IsSatisfiedBy(T entity)
};
Этот интерфейс позволяет работать с коллекциями в памяти, но никак не подходит для построения SQL-запросов. В современном C# больше подходит такой вариант:
public abstract class Specification<T>
{
public bool IsSatisfiedBy(T item)
{
return SatisfyingElementsFrom(new[] { item }.AsQueryable()).Any();
}
public abstract IQueryable<T> SatisfyingElementsFrom(IQueryable<T> candidates);
}
Область применения
Моделирование предметной области – не простая задача. DDD предполагает делегирование части задач по аналитике разработчикам. Это оправдано в случаях, когда стоимость ошибки велика. Не важно, как быстро вы написали код и как быстро работает ваша система, если она работает не верно, и вы теряете деньги. На самом деле, верно обратное – если вы разрабатывает ПО для HFT и до конца не понимаете, как оно должно работать, лучше, чтобы ваше ПО тормозило или вообще не работало. Так вы по крайней мере не будете терять деньги на супер-быстром, но не верном трейдинге ?
В неустоявшихся бизнесах (особенно стартапах) часто нет никакого понимания предметной модели. Все может меняться ежедневно. В этих условиях бесполезно требовать от участников бизнес-процесса использовать единую терминологию.
CQRS
Вывод очевиден: DDD – не «серебряная пуля», а жаль:) Однако, можно получить значительный выигрыш за счет «точечного применения» DDD в определенных Bounded Context.
В 1980 Бертран Мейер сформулировал очень простой термин CQS. В начале двухтысячных Грег Янг расширил и популяризовал эту концепцию. Так появился CQRS… и CQRS во многом повторил судьбу DDD, в том, смысле, что был неоднократно не верно истолкован.
Несмотря на то, что материалов по CQRS в интернете предостаточно, все «готовят» его по-разному. Многие команды используют принципы CQRS, хотя не называют это так. В системе может не быть абстракций Command и Query. Их Может заменить IOperation или даже Func<T1, T2> и Action<T>.
Этому есть простое объяснение. Первые результаты по запросу CQRS выдают нечто вроде изображения ниже:
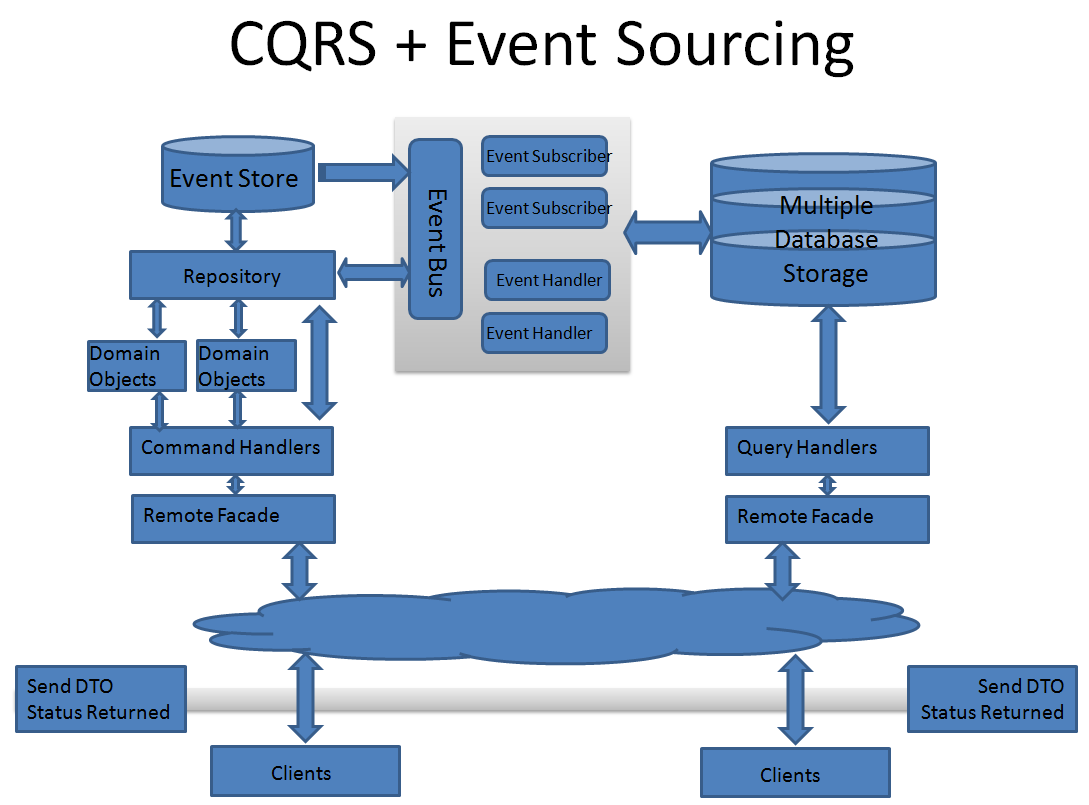
Эту реализацию Дино Эспозито называет DELUXE. Дело здесь в том, что CQRS интересует Грега Янга в основном в контексте Event Sourcing. На самом деле для Event Sourcing необходимо использовать CQRS, но не наоборот.
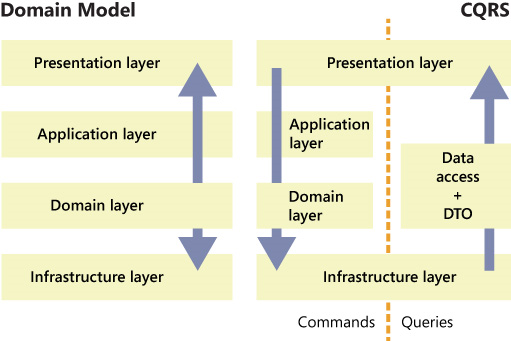
Таким образом, используя CQRS мы можем решить проблему тормозных отчетов, разделив стеки приложения на Read и Write и не используя Domain Model в Read-стеке. Read-стек может использовать другую БД и/или другое более оптимальное API доступа к данным.
Разделение приложения на команды, обработчики и запросы имеет еще одно преимущество: лучшая прогнозируемость. В случае DDD, чтобы знать где искать ту или иную бизнес-логику необходимо понимать предметную область. В случае CQRS программист всегда знает, что запись происходит в обработчиках команд, а для доступа к данным используются Query. Кроме этого есть еще несколько не очевидных, на первый взгляд, плюсов. Их мы рассмотрим ниже.
CQRS основные выводы
- Event Sourcing требует CQRS, но не наоборот
- Дешево
- Подходит везде
- Масштабируется
- Не требует 2 хранилища данных. Эта одна из возможных реализаций, а не обязаловка
- Обработчик команды может возвращать значение. Если не согласны спорьте с Грегом Янгом и Дино Эспозито, а не со мной
- Если обработчик возвращает значение он хуже масштабируется, однако есть async/await, но надо понимать как они работают
Основные интерфейсы в CQRS могут выглядеть так:
[PublicAPI]
public interface IQuery<out TOutput>
{
TOutput Ask();
}
[PublicAPI]
public interface IQuery<in TSpecification, out TOutput>
{
TOutput Ask([NotNull] TSpecification spec);
}
[PublicAPI]
public interface IAsyncQuery<TOutput>
: IQuery<Task<TOutput>>
{
}
[PublicAPI]
public interface IAsyncQuery<in TSpecification, TOutput>
: IQuery<TSpecification, Task<TOutput>>
{
}
[PublicAPI]
public interface ICommandHandler<in TInput>
{
void Handle(TInput input);
}
[PublicAPI]
public interface ICommandHandler<in TInput, out TOutput>
{
TOutput Handle(TInput input);
}
[PublicAPI]
public interface IAsyncCommandHandler<in TInput>
: ICommandHandler<TInput, Task>
{
}
[PublicAPI]
public interface IAsyncCommandHandler<in TInput, TOutput>
: ICommandHandler<TInput, Task<TOutput>>
{
}
Мы договорились о том, что:
- Query всегда только получает данные, но не изменяет состояние системы. Для изменения системы используются команды
- Query могут возвращать необходимые проекции на прямую, в обход доменной модели
В этом случае в отсутствии команд все Query всегда возвращают одинаковые результаты на одинаковых входных данных. Такая организация сильно упрощает отладку, потому что в Query нет состояния, которое могло бы изменить возвращаемый результат.
При необходимости Audit Log или полноценный Event Sourcing можно подключить ко всем обработчикам команд, через базовый класс.
Не трудно заметить, что основные интерфейсы CQRS можно привести к Func<T1, T2> и Action<T>. Добавьте stateless и immutable, и вы получите чистые функции (привет функциональное программирование;) Строго говоря, это конечно не так, потому что большинство Query будут работать с файловой системой, БД или сетью. Вы также наверняка захотите закешировать результаты выполнения Query, однако пользу от линеаризации data-flow и компонуемости получить можно.
CQRS over HTTP
Принципы CQRS очень хорошо подходят для реализации по протоколу HTTP. Спецификация HTTP четко говорит GET-запросы должны возвращать данные с сервера. POST, PUT, PATCH – изменять состояние. Хорошим тоном в web-программировании считается редирект на GET после выполнения POST-операции, например, сабмита формы.
Итак
- GET– это Query
- POST/PUT/PATCH/DELETE – это Command
Базовые классы для часто используемых операций
Отчеты – не единственная частая задача чтения данных. Более общее определение типовых операций чтения это:
- Фильтрация
- Пагинация (постраничный вывод)
- Создание проекций (представление агрегатов в необходимом на клиентской стороне виде)
Мы активно используем AutoMapper для построения проекций. Одной из отличительных особенностей этого маппера являются Queryable-Extensions: возможность построить Expression для преобразования в SQL, вместо маппинга в оперативной памяти. Не всегда эти проекции точны и производительны, но для быстрого прототипирования подходят идеально.
Для постраничного вывода из любой таблицы в БД и поддержкой фильтрации можно использовать всего одну реализацию IQuery.
public class ProjectionQuery<TSpecification, TSource, TDest>
: IQuery<TSpecification, IEnumerable<TDest>>
, IQuery<TSpecification, int>
where TSource : class, IHasId
where TDest : class
{
protected readonly ILinqProvider LinqProvider;
protected readonly IProjector Projector;
public ProjectionQuery([NotNull] ILinqProvider linqProvier, [NotNull] IProjector projector)
{
if (linqProvier == null) throw new ArgumentNullException(nameof(linqProvier));
if (projector == null) throw new ArgumentNullException(nameof(projector));
LinqProvider = linqProvier;
Projector = projector;
}
protected virtual IQueryable<TDest> GetQueryable(TSpecification spec)
=> LinqProvider
.GetQueryable<TSource>()
.ApplyIfPossible(spec)
.Project<TSource, TDest>(Projector)
.ApplyIfPossible(spec);
public virtual IEnumerable<TDest> Ask(TSpecification specification)
=> GetQueryable(specification).ToArray();
int IQuery<TSpecification, int>.Ask(TSpecification specification)
=> GetQueryable(specification).Count();
}
public class PagedQuery<TSortKey, TSpec, TEntity, TDto> : ProjectionQuery<TSpec, TEntity, TDto>,
IQuery<TSpec, IPagedEnumerable<TDto>>
where TEntity : class, IHasId
where TDto : class, IHasId
where TSpec : IPaging<TDto, TSortKey>
{
public PagedQuery(ILinqProvider linqProvier, IProjector projector)
: base(linqProvier, projector)
{
}
public override IEnumerable<TDto> Ask(TSpec spec)
=> GetQueryable(spec).Paginate(spec).ToArray();
IPagedEnumerable<TDto> IQuery<TSpec, IPagedEnumerable<TDto>>.Ask(TSpec spec)
=> GetQueryable(spec).ToPagedEnumerable(spec);
public IQuery<TSpec, IPagedEnumerable<TDto>> AsPaged()
=> this as IQuery<TSpec, IPagedEnumerable<TDto>>;
}
Метод ApplyIfPossible проверит осуществляется фильтрация на уровне агрегата или проекции (бывает нужно и так и так). Метод Project создаст проекцию с помощью AutoMapper.
AutoFilter и Dynamic Linq могут помочь, если вы работает с большим количеством однотипных форм.
public static class AutoFilterExtensions
{
public static IQueryable<T> ApplyDictionary<T>(this IQueryable<T> query
, IDictionary<string, object> filters)
{
foreach (var kv in filters)
{
query = query.Where(kv.Value is string
? $"{kv.Key}.StartsWith(@0)"
: $"{kv.Key}=@0", kv.Value);
}
return query;
}
public static IDictionary<string, object> GetFilters(this object o) => o.GetType()
.GetTypeInfo()
.GetProperties(BindingFlags.Public)
.Where(x => x.CanRead)
.ToDictionary(k => k.Name, v => v.GetValue(o));
}
public class AutoFilter<T> : ILinqSpecification<T>
where T: class
{
public IDictionary<string, object> Filter { get; }
public AutoFilter()
{
Filter = new Dictionary<string, object>();
}
public AutoFilter([NotNull] IDictionary<string, object> filter)
{
if (filter == null) throw new ArgumentNullException(nameof(filter));
Filter = filter;
}
public IQueryable<T> Apply(IQueryable<T> query)
=> query.ApplyDictionary(Filter);
}
Для построения агрегатов из команд на создание/редактирование можно использовать обобщенный TypeConverter.
Для того, чтобы упросить регистрацию в контейнере можно использовать соглашения.
Заключение
Мы активно используем CQRS без Event Sourcing в работе и пока впечатления очень хорошие.
- Проще тестировать код, потому что классы маленькие и гарантированно отвечают только за одну вещь
- По этой-же причине упрощается внесение изменений в систему
- Упростилась коммуникация, исчезли споры о том где тот или иной код должен находиться. Код разных участников команды стал единообразным
- DDD используется для первоначального моделирования системы и создания агрегатов. Агрегаты могут вообще не инстанцироваться, в случае, если все методы над соответствующей таблице жестко оптимизированы (реализованы в обход ORM)
- Event Sourcing в full banana – реализации ни разу не потребовался, Audit Log реализуется довольно часто.