Микросервисная архитектура становится всё более популярной. Это модульный подход, при котором приложение функционально разделяется на отдельные сервисы. В результате разработчики больших и сложных приложений могут быстрее выпускать качественный софт. При таком подходе им проще осваивать новые технологии, так как появляется возможность реализовывать каждый отдельный сервис с помощью наиболее подходящего и современного стека технологий. Микросервисная архитектура также улучшает масштабируемость приложений за счет возможности развёртывать каждый отдельный сервис на оптимальном для него оборудовании.
Однако микросервисы являются не таким уж простым и универсальным решением. В частности, модели предметной области, транзакции и запросы удивительно устойчивы к разделению по функциональному признаку. В результате разработка транзакционных бизнес-приложений с использованием микросервисной архитектуры является довольно сложной задачей. В этой статье мы рассмотрим способ разработки микросервисов, при котором эти проблемы решаются с помощью паттерна проектирования на основе предметной области (Domain Driven Design), Event Sourcing и CQRS.
Основные тезисы:
- Микросервисная архитектура функционально разделяет приложение на отдельные сервисы, каждый из которых соответствует определенному бизнес-объекту или бизнес-процессу.
- Одной из ключевых проблем при разработке микросервис-ориентированных приложений является то, что транзакции, модели предметной области (Domain models) и запросы «сопротивляются» разделению на отдельные сервисы.
- Модель предметной области (Domain model) может быть разложена на агрегаты (Aggregates) в рамках паттерна проектирования на основе предметной области (Domain Driven Design).
- Каждый сервис представляет собой модель предметной области, состоящую из одного или нескольких агрегатов DDD.
- В рамках сервиса каждая транзакция создает или обновляет один-единственный агрегат.
- События (Events) используются для поддержания согласованности между агрегатами (и сервисами).
Давайте сначала посмотрим на проблемы, с которыми сталкиваются разработчики при создании микросервисов.
Проблемы разработки микросервисов
Модульность имеет важное значение при разработке больших и сложных приложений.
Большинство современных приложений слишком велики, чтобы их мог создать один разработчик. Кроме того, они слишком сложны, чтобы быть полностью понятыми одним человеком. Приложение должно быть разделено на модули, которые разрабатываются целой командой разработчиков. В монолитном приложении модульность определяется конструкциями используемого языка программирования, например, Java-пакетами. Такой подход, как правило, не очень хорошо работает на практике. Долгоживущие монолитные приложения обычно вырождаются в то, что известно как антипаттерн Big balls of mud.
Микросервисная архитектура использует сервис в качестве единицы модульности. Каждый сервис — это отдельный бизнес-процесс или бизнес-объект, который что-то делает для получения конкретного результата. Например, интернет-магазин, используя эту архитектуру, мог бы состоять из таких микросервисов, как Сервис Заказов (Order Service), Сервис Клиентов (Customer Service), Каталог товаров (Catalog Service) и т.д.

Каждый сервис имеет четкие границы, благодаря которым гораздо легче сохранять модульность приложения в течение долгого времени. Микросервисная архитектура имеет и другие преимущества, включая возможность развертывания и масштабирования сервисов независимо друг от друга.
К сожалению, делить приложение на сервисы не так просто, как кажется. Как уже упоминалось ранее, несколько различных аспектов приложений — модели предметной области, транзакции и запросы — трудно поддаются такому разделению. Давайте посмотрим на причины этих трудностей.
Проблема № 1: Разделение модели предметной области
Паттерн «модель предметной области» (Domain model) является хорошим способом реализации сложной бизнес-логики. Модель предметной области для интернет-магазина будет включать в себя такие классы, как Заказ, Позиция заказа, Клиент, Товар. В микросервисной архитектуре классы Заказ и Позиция заказа являются частью сервиса Заказ, класс Клиент является частью сервиса Клиент, а класс Товар принадлежит сервису Каталог.

Проблемой в разделении модели предметной области на сервисы является то, что классы часто ссылаются друг на друга. Например, Заказ ссылается на Клиента, который его сделал, а Позиции заказа ссылаются на Товары. Что же делать со ссылками, нарушающими границы сервисов? Позже мы увидим, как понятие агрегата (Aggregate) из DDD (Domain Driven Design) решает эту проблему.
Микросервисы и базы данных
Отличительной особенностью микросервисной архитектуры является то, что данные, принадлежащие сервису, доступны только через API этого сервиса. Например, в интернет-магазине Сервис Заказов имеет базу данных, которая включает в себя таблицу ORDERS, а Сервис Клиентов имеет свою базу данных, которая включает в себя таблицу CUSTOMERS. Из-за такой инкапсуляции сервисы слабо связаны, и разработчик может изменить схему своего сервиса без необходимости координировать свои действия с разработчиками, работающими над другими сервисами. Во время выполнения приложения сервисы изолированы друг от друга. Например, сервис никогда не будет ожидать окончания блокировки базы данных, принадлежащей другому сервису. С другой стороны, функциональное разделение базы данных затрудняет поддержание целостности данных, а также реализацию многих типов запросов.
Проблема № 2: Транзакции
Традиционное монолитное приложение может полагаться на транзакции, чтобы обеспечить соблюдение бизнес-правил. Представьте, например, что у клиентов интернет-магазина есть кредитный лимит, который должен быть проверен перед созданием нового заказа. Приложение должно гарантировать, что несколько одновременных попыток размещения заказа не превысят кредитный лимит клиента. Если заказы и клиенты находятся в одной базе данных, то тривиальным решением вопроса является использование транзакции (с соответствующим уровнем изоляции):
BEGIN TRANSACTION
…
SELECT ORDER_TOTAL FROM ORDERS WHERE CUSTOMER_ID = ?
…
SELECT CREDIT_LIMIT FROM CUSTOMERS WHERE CUSTOMER_ID = ?
…
INSERT INTO ORDERS …
…
COMMIT TRANSACTIONК сожалению, мы не можем использовать такой простой подход для поддержания согласованности данных при микросервис-ориентированном подходе. Таблицы ORDERS и CUSTOMERS принадлежат различным сервисам и могут быть доступны только через API. Они даже могут находиться в различных базах данных.
В данном случае традиционным решением будут распределенные транзакции, но для современных приложений это неподходящая технология. Теорема CAP требует от разработчика сделать выбор между доступностью (Availability) и согласованностью данных (Consistency), и доступность, как правило, является предпочтительным выбором. Кроме того, многие современные технологии, такие как большинство NoSQL-баз данных, не поддерживают даже обычные транзакции, не говоря уже о распределенных. Важное значение имеет и поддержание целостности, так что нам нужно другое решение. Ниже мы увидим, что решением является использование cобытийно-ориентированной (Event-driven, message-driven) архитектуры, основанной на Event Sourcing.
Проблема № 3: Запросы к базе данных
Наряду с поддержанием целостности данных проблемой являются и запросы к базе данных. В традиционных монолитных приложениях чрезвычайно распространены запросы, использующие соединения (Joins). Например, можно легко найти недавно зарегистрированных клиентов и их крупные заказы с помощью запроса:
SELECT * FROM CUSTOMER c, ORDER o
WHERE
c.id = o.ID
AND o.ORDER_TOTAL > 100000
AND o.STATE = 'SHIPPED'
AND c.CREATION_DATE > ?Мы не можем использовать этот вид запроса в микросервис-ориентированном интернет-магазине. Как уже упоминалось ранее, таблицы ORDERS и CUSTOMERS принадлежат различным сервисам и могут быть доступны только через API. Некоторые сервисы могут даже не использовать SQL-базу. Но можно использовать подход, известный как Event Sourcing, что делает поиск информации еще более сложной задачей.
Дальше мы увидим, что решением является сохранение материализованных представлений с помощью подхода, известного как Command Query Responsibility Segregation (CQRS). Но сначала, давайте рассмотрим вопрос Domain-Driven Design (DDD) при разработке микросервисов.
DDD-агрегаты как строительные блоки микросервисов
Как видите, есть несколько проблем, которые необходимо решить ради успешной разработки приложений с использованием микросервисов. Решение некоторых из этих проблем может быть найдено в обязательной для прочтения книге Эрика Эванса “Domain-Driven Design”. В ней описывается подход к проектированию сложного программного обеспечения, что очень полезно при разработке микросервисов. В частности, Domain-Driven Design позволяет создавать модульную модель предметной области, которая может быть распределена по сервисам.
Что такое агрегаты?
В Domain-Driven Design Эванс определяет несколько строительных блоков для моделей предметной области. Многие из них стали частью повседневного языка разработчиков, включая Entity, Value object, Service, Repository и т.д. Однако, один строительный блок — агрегат — был, в основном, проигнорирован разработчиками, за исключением DDD-пуристов. Но оказывается, что агрегаты являются ключом к разработке микросервисов.
Агрегат представляет собой кластер объектов предметной области, которые можно рассматривать как единое целое. Он состоит из корневого объекта-сущности (Entity) и, возможно, одного и более других связанных с ними объектов-сущностей и объектов-значений (Value Object). Например, модель предметной области для интернет-магазина содержит такие агрегаты, как Заказ и Клиент. Агрегат Заказ состоит из корневой сущности Заказ, одного или нескольких объектов-значений Позиция заказа наряду с другими объектами-значениями, такими как Стоимость, Адрес доставки и Платежные реквизиты. Агрегат Клиент состоит из сущности Клиент и нескольких объектов-значений, таких как Информация о доставке и Информация о платеже.
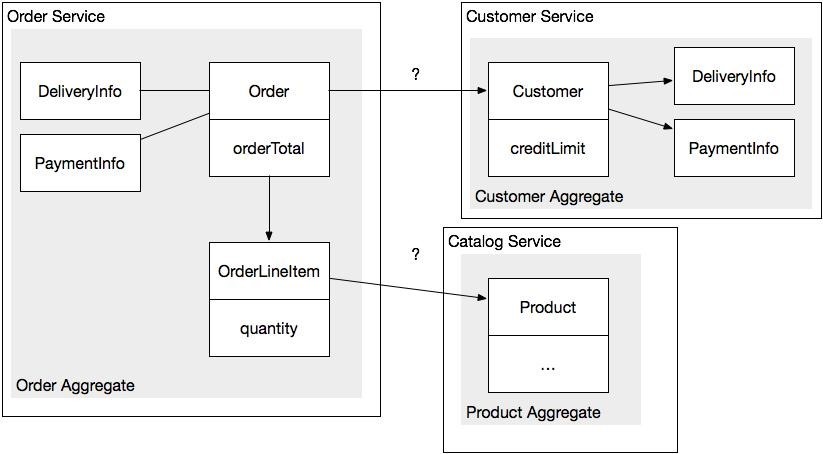
Использование агрегатов разделяет модель предметной области на куски, которые легче понять по отдельности. В нем также определяется набор операций, таких как загрузка и удаление. Агрегат обычно загружается из базы данных целиком. Удаление агрегата удаляет и все объекты. Преимущество агрегатов, однако, выходит далеко за пределы модульности модели предметной области, потому что агрегаты должны подчиняться определенным правилам.
Межагрегатные связи должны использовать первичные ключи
Первое правило заключается в том, что агрегаты всегда ссылаются друг на друга через уникальный идентификатор (например, первичный ключ) вместо прямых ссылок на объекты. Например, Заказ ссылается на своего Клиента, используя CustomerId, а не ссылку на объект клиента. Аналогичным образом, Позиция заказа ссылается на Товар, используя ProductID.
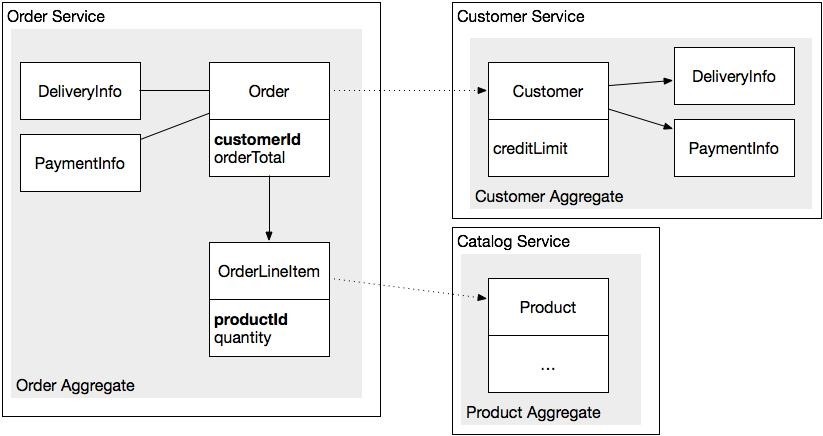
Такой подход сильно отличается от традиционного, при котором внешние ключи в модели предметной области считаются плохой практикой. Использование идентификатора, а не ссылки на объект, означает, что агрегаты слабо связаны. Вы можете легко разместить различные агрегаты в различных сервисах. На самом деле, бизнес-логика сервиса состоит из модели предметной области, которая представляет собой набор агрегатов. Например, OrderService содержит агрегат Заказ, а CustomerService содержит агрегат Клиент.
Одна транзакция создает или обновляет один агрегат
Второе правило заключается в том, что транзакция может создать или обновить только один агрегат. Когда я впервые прочитал об этом правиле много лет назад, это не имело никакого смысла! В то время я разрабатывал традиционные монолитные приложения на основе РСУБД, и поэтому транзакции могли обновлять произвольные данные. Сегодня же это ограничение идеально подходит для микросервисной архитектуры. Это гарантирует, что транзакция содержится внутри сервиса. Это ограничение также соответствует ограничениям транзакций большинства NoSQL-баз данных.
При разработке модели предметной области ключевым является решение, насколько большим нужно делать каждый конкретный агрегат. В идеале, агрегаты должны быть небольшими. Это улучшает модульность за счёт разделение ответственности. Так эффективнее, поскольку агрегаты обычно загружаются полностью. Кроме того, так как обновление каждого агрегата происходит последовательно, использование более мелких агрегатов позволит увеличить количество одновременных запросов, которое может обрабатывать приложение, и тем самым улучшить масштабируемость. Это также снижает вероятность того, что два пользователя попытаются одновременно обновить один и тот же агрегат.
С другой стороны, так как агрегат является сферой деятельности транзакции, возможно, потребуется определить агрегат покрупнее, чтобы сделать конкретное обновление атомарным.
Например, выше сказано, что в модели предметной области интернет-магазина Заказ и Клиент — это отдельные агрегаты. Альтернативой является сделать Заказ частью агрегата Клиент. Преимуществом большого агрегата Клиент является то, что приложение сможет атомарно обеспечивать проверку кредитного лимита. Недостаток подхода в том, что он сочетает в себе функциональность Заказа и Клиента в одном и том же сервисе. Это снижает масштабируемость, так как транзакции, обновляющие разные заказы одного и того же клиента, не смогут выполняться параллельно. Кроме того, два пользователя могут вступить в конфликт, если они попытаются редактировать различные заказы одного клиента. С увеличением количества заказов загрузка агрегата Клиент будет становиться всё более дорогой. Из-за этих проблем лучше делать агрегаты настолько маленькими, насколько это возможно.
Даже соблюдая требование по созданию или обновлению транзакцией только одного агрегата, приложения по-прежнему должны поддерживать согласованность между агрегатами. Например, сервис Заказ должен проверить, что новый агрегат Заказ не превысит совокупный кредитный лимит клиента. Есть несколько различных способов поддержания согласованности. Одним из вариантов является обман приложения и создание/обновление нескольких агрегатов в одной транзакции. Это возможно только тогда, когда все агрегаты принадлежат одному и тому же сервису и сохраняются в одной и той же РСУБД. Другой, более правильный вариант заключается в поддержании согласованности между агрегатами с использованием событийно-ориентированного подхода.
Использование событий для поддержания согласованности данных
В современном приложении есть различные ограничения по транзакциям, которые делают его сложным для поддержания согласованности данных в сервисах. Каждый сервис имеет свои собственные данные, но использование распределенных транзакций не является жизнеспособным вариантом. Кроме того, многие приложения используют NoSQL-базы, которые не поддерживают даже обычные локальные транзакции, не говоря уже о распределенных. Следовательно, современное приложение должно использовать управляемую событиями модель транзакции, известную как «согласованность в конечном счете» (Eventually Consistent).
Что такое событие (Event)?
Как гласит словарь Merriam-Webster (и Капитан Очевидность), «событие» — это то, что происходит (случается):

В этой статье мы определяем событие предметной области (Domain Event) как то, что произошло с агрегатом. Событие обычно представляет собой изменение состояния. Рассмотрим, например, агрегат Заказ. События, изменяющие его состояние, включают в себя Заказ создан, Заказ отменен, Заказ отправлен. События могут представлять собой попытки нарушить бизнес-правила, например, кредитный лимит Клиента.
Использование событийно-ориентированной (Event-Driven) архитектуры
Сервисы используют события для обеспечения согласованности между агрегатами следующим образом: агрегат публикует событие всякий раз, когда происходит что-то заметное. Например, его состояние меняется, или есть попытка нарушения бизнес-правила. Другие агрегаты подписываются на событие и реагируют на него путем обновления своего собственного состояния.
Интернет-магазин проверяет кредитный лимит клиента при создании заказа, используя следующую последовательность шагов:
- Агрегат Заказ, который создается со статусом NEW, публикует событие OrderCreated.
- Агрегат Клиент получает уведомление о событии OrderCreated, резервирует кредит для заказа и публикует событие CreditReserved.
- Агрегат Заказ получает уведомление о событии CreditReserved и меняет свой статус на УТВЕРЖДЕН.
Если кредитная проверка терпит неудачу из-за нехватки средств, агрегат Клиент публикует событие CreditLimitExceeded. Это событие не отражает изменения состояния, а представляет собой неудачную попытку нарушить бизнес-правила. Агрегат Заказ получает уведомление об этом событии и меняет свое состояние на ОТМЕНЕН.
Микросервисная архитектура как сеть событийно-управляемых агрегатов
В этой архитектуре бизнес-логика каждого сервиса состоит из одного или нескольких агрегатов. Каждая транзакция, выполняемая сервисом, обновляет или создает один единственный агрегат. Сервисы поддерживают согласованность данных между агрегатами с помощью событий.
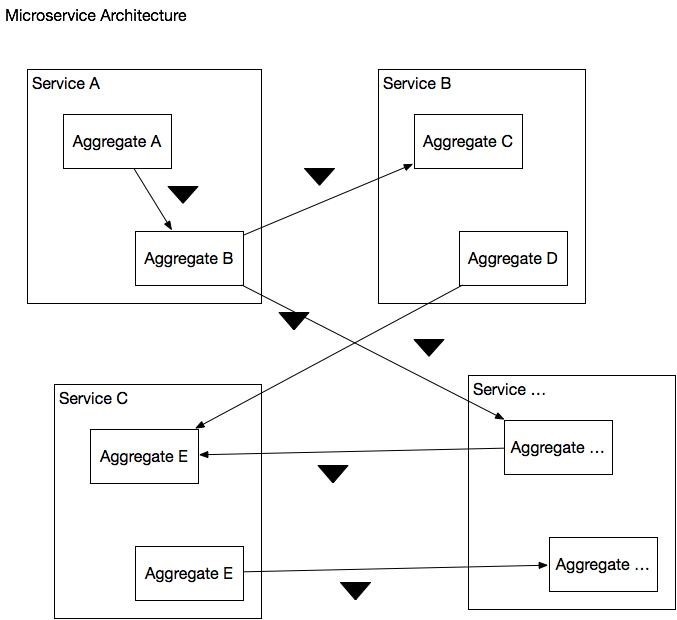
Отличительной особенностью подхода является то, что агрегаты представляют собой слабо связанные строительные блоки. Они могут быть развернуты и как монолитное приложение, и как набор отдельных сервисов. В начале проекта вы могли бы использовать монолитную архитектуру. А позже, с ростом размера приложения и команды разработчиков, вы можете легко переключиться на микросервисную архитектуру.
Резюме
Микросервисная архитектура функционально разделяет приложение на сервисы, каждый из которых соответствует определенному бизнес-объекту или бизнес-процессу. Одной из основных проблем при разработке микросервисных бизнес-приложений является то, что транзакции, модели предметной области и запросы противостоят разделению на сервисы. Вы можете разделить модель предметной области, применяя концепцию «агрегата» из Domain Driven Design. Бизнес-логика каждого сервиса представляет собой модель предметной области, состоящую из одного или нескольких агрегатов DDD.
Внутри каждого сервиса транзакция создает или обновляет один единственный агрегат. Поскольку распределенные транзакции не являются жизнеспособной технологией для современных приложений, для поддержания согласованности между агрегатами (и сервисами) используются события.
Во второй части статьи мы рассмотрим, как реализовать надежную архитектуру, управляемую событиями с помощью Event Sourcing, а также как реализовать запросы в микросервисной архитектуре с помощью CQRS.
Основные тезисы:
- Event Sourcing — это механизм надежного изменения состояния и публикации событий, позволяющий преодолеть ограничения других решений.
- Событийно-ориентированный подход, использующий Event Sourcing, хорошо согласуется с микросервисной архитектурой.
- Снапшоты могут повысить производительность запросов состояния агрегатов за счёт сочетания в себе всех событий, произошедших до определенного момента времени.
- Event sourcing может создавать проблемы для запросов, но они преодолеваются с помощью CQRS и материализованных представлений.
- Event sourcing и CQRS не требуют каких-либо специальных инструментов или программного обеспечения, многие существующие фреймворки могут взять на себя часть необходимой низкоуровневой функциональности.
Надежное обновление состояния и публикация событий
На первый взгляд, обеспечение согласованности между агрегатами с помощью событий кажется довольно простой задачей. Сервис, создавая или обновляя агрегат в базе данных, просто публикует событие. Но есть проблема: обновление базы данных и публикация события должны выполняться атомарно. Например, если что-то сломалось после обновления базы данных, но перед публикацией события, то система окажется в неустойчивом состоянии. Традиционным решением в данном случае являются распределенные транзакции с участием базы данных и брокера сообщений. Но, по причинам, описанным в первой части статьи, распределенные транзакции не являются жизнеспособным вариантом.
Есть несколько способов решения этой проблемы без использования распределенных транзакций. Например, можно использовать брокер сообщений (вроде Apache Kafka).
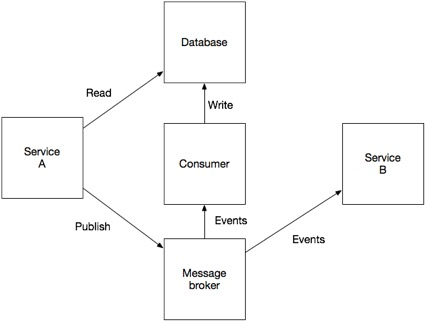
Отдельно выделенный получатель сообщений подписывается на сообщения брокера, и, получив их, обновляет базу данных. Такой подход гарантирует, что и база данных обновляется, и событие публикуется. Его недостаток заключается в том, что это гораздо более сложная модель согласованности, в которой приложение не может сразу же прочитать то, что оно само отправило для записи в базу данных.
Другим вариантом решения может быть паттерн Transaction log tailing: берутся записи из журнала транзакций, преобразуются в события и отправляются брокеру сообщений. Важным преимуществом этого подхода является то, что он не требует каких-либо изменений приложения. Недостаток, однако, заключается в том, что это может затруднить реверс-инжиниринг бизнес-событий высокого уровня — причина для обновления базы данных — от низкоуровневых изменений до строк в таблицах.

Третий вариант решения: использование таблицы базы данных в качестве временной очереди сообщений. Когда сервис обновляет агрегат, он внутри локальной транзакции добавляет событие в специальную таблицу базы данных EVENTS. Отдельный процесс периодически просматривает таблицу EVENTS и публикует события, отправляя их брокеру сообщений.
Приятной особенностью этого решения является то, что служба может публиковать бизнес-события высокого уровня. Недостаток: этот подход потенциально подвержен ошибкам, так как код публикации событий должен быть синхронизирован с бизнес-логикой.

Все три варианта имеют существенные недостатки. Публикация событий через брокер сообщений с отложенным обновлением базы данных не обеспечивает условия модели согласованности Read-your-writes. Публикация событий на основе журнала транзакций обеспечивает согласованность при чтении данных, но не всегда может публиковать бизнес-события высокого уровня. Использование таблицы базы данных в качестве очереди сообщений обеспечивает согласованность при чтении и публикацию бизнес-событий высокого уровня, но подразумевает, что разработчик должен не забыть опубликовать событие при изменении состояния.
К счастью, есть еще один вариант решения. Это событийно-ориентированный подход к сохранению состояния и бизнес-логике, известный как Event Sourcing.
Разработка микросервисов с помощью Event Sourcing
Event Sourcing представляет собой событийно-ориентированный подход к сохранению состояния. Это не новая идея. Впервые я узнал об Event Sourcing более пяти лет назад, но он оставался диковинкой, пока я не начал разрабатывать микросервисы. Event Sourcing оказался отличным способом реализации событийно-ориентированной микросервисной архитектуры.
Сервис, использующий Event Sourcing, хранит состояние агрегатов как последовательность событий. Когда создается или обновляется агрегат, сервис сохраняет одно или несколько событий в специальном хранилище событий в базе данных.
Чтобы получить текущее состояние агрегата, производится загрузка событий и их воспроизведение. В терминах функционального программирования, сервис реконструирует текущее состояние агрегата, выполняя функционал fold/reduce над событиями. Поскольку события теперь и есть состояние, мы больше не имеем проблем с атомарностью обновлений состояний и публикацией событий.
Рассмотрим, например, сервис Заказ. Вместо того, чтобы хранить каждый заказ как строки в таблице ORDERS, он хранит каждый агрегат Заказ в виде последовательности событий, таких как ЗаказСоздан, ЗаказОдобрен, ЗаказОтправлен и т.д. Вот как это могло бы быть сохранено в интернет-магазине на SQL базе данных.
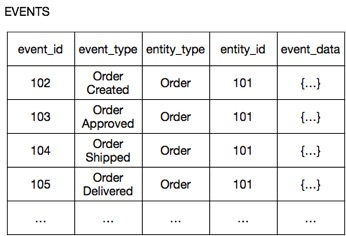
Колонки entity_type и entity_id columns — идентификаторы агрегата.
event_id — идентификатор события.
event_type — тип события.
event_data — сериализованные атрибуты события в формате JSON.
Некоторые события содержат много данных. Например, событие ЗаказСоздан содержит данные о составе заказа, платежную информацию и информацию о доставке. Событие ЗаказОтправлен содержит минимум информации и представляет собой просто переход между состояниями.
Event Sourcing и публикация событий
Строго говоря, Event Sourcing просто хранит состояние агрегатов как события. Его очень просто использовать в качестве надежного механизма публикации событий. Сохранение события по своей природе является атомарной операцией, что гарантирует, что хранилище событий будет предоставлять доступ к событиям всем заинтересованным сервисам. Например, если события сохраняются в таблице EVENTS, упомянутой выше, то подписчики могут просто периодически опрашивать таблицу для получения новых событий. Более сложные хранилища событий будут использовать другой подход, который даёт аналогичные гарантии, но является более производительным и масштабируемым. Например, Eventuate Local использует паттерн Transaction log tailing. Он читает события, вставленные в таблицу EVENTS из потока репликации MySQL, и публикует их с помощью Apache Kafka.
Использование снапшотов состояния для повышения производительности
Агрегат Заказ характеризуется относительно небольшим количеством переходов между состояниями, и поэтому он имеет лишь небольшое количество событий. В этом случае будут эффективными запрос из хранилища событий и реконструкция текущего состояния агрегата Заказ. Однако некоторые агрегаты имеют большое количество событий. Например, агрегат Клиент может потенциально иметь множество событий Credit Reserved. Со временем их загрузка и обработка стала бы неэффективной.
Общим решением проблемы является периодическое сохранение снапшота состояния агрегата. Приложение восстанавливает состояние агрегата путем загрузки последнего снапшота и только тех событий, которые произошли с момента его создания. В терминах функционального программирования, снимок представляет собой первоначальное значение для fold/reduce. Если агрегат имеет простую, легко сериализуемую структуру, то снимок может быть, например, в формате JSON. Снимки более сложных агрегатов могут быть сделаны с помощью паттерна Memento.
Например, агрегат Клиент в интернет-магазине имеет очень простую структуру: информация о клиенте, его кредитный лимит и данные о резервировании его кредитных средств. Снимок Клиента является просто набором данных о его состоянии в формате JSON. На рисунке показано, как воссоздать состояние Клиента из снимка, соответствующего состоянию Клиента на момент поступления события 103. Сервису клиентов нужно просто загрузить снимок и обработать события, произошедшие после 103-го.
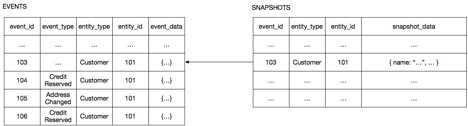
Сервис клиентов воссоздает состояние клиента, десериализуя JSON моментального снимка, а затем загружая и обрабатывая события со 104 по 106.
Реализация Event Sourcing
Хранилище событий представляет собой гибрид базы данных и брокера сообщений. Оно представляет собой базу данных, так как имеет API для вставки и извлечения событий агрегатов с помощью первичного ключа, но оно также и брокер сообщений, поскольку имеет API для подписки на события.
Есть несколько различных способов реализации хранилища событий. Одним из них является создание своего собственного event sourcing-фреймворка. Вы можете, например, сохранять события в РСУБД. Это простой, хотя и низко-производительный способ публикации событий. Подписчики просто периодически опрашивают таблицу EVENTS для получения новых событий.
Другой вариант: использовать специальное хранилище событий, которое, как правило, предоставляет богатый набор функций, более высокую производительность и масштабируемость. Грег Янг (Greg Young), пионер в event sourcing, создал на основе .NET хранилище событий с открытым исходным кодом под названием Event Store (https://geteventstore.com). Компания Lightbend, ранее известная как Typesafe, разработала микросервисный фреймворк Lagom, основанный на event sourcing. Можно отметить и стартап Eventuate, имеющий event sourcing-фреймворк, который доступен в качестве облачного сервиса, является проектом с открытым исходным кодом и использует Kafka и РСУБД.
Преимущества и недостатки Event Sourcing
Event sourcing имеет как преимущества, так и недостатки. Основным преимуществом подхода является то, что события гарантированно публикуются всякий раз, когда изменяется состояние агрегата. Это хорошая основа для управляемой событиями микросервисной архитектуры. Кроме того, поскольку каждое событие может записать идентификатор пользователя, который внес изменения, event sourcing предоставляет журнал аудита, который является гарантированно точным. Поток событий может быть использован и для других целей, в том числе для отправки уведомлений пользователям.
Еще одно преимущество event sourcing — хранение всей истории каждого агрегата. Вы можете легко реализовать временные запросы, которые возвращают состояние агрегата в прошлое. Для того, чтобы определить состояние агрегата в конкретный момент времени, нужно просто обработать события, которые произошли до этого момента. Например, можно легко рассчитать доступный кредит клиента на какой-то момент в прошлом.
Благодаря сохранению события, а не самого агрегата, Event sourcing обычно позволяет избегать проблемы «потери соответствия» (impedance mismatch). События, как правило, имеют простую, легко-сериализуемую структуру. Посредством сериализации сервис может сделать снимок состояния сложного агрегата. Паттерн Memento добавляет уровень косвенности между агрегатом и его сериализованным представлением.
Однако в технологии event sourcing не всё так гладко, и она имеет некоторые недостатки. Это другая, непривычная модель программирования, которую нужно изучить. Для того, чтобы существующее приложение начало использовать event sourcing, необходимо переписать его бизнес-логику. К счастью, это довольно механическое преобразование, которое можно сделать при переносе приложения на микросервисную структуру.
Еще один недостаток event sourcing заключается в том, что брокер сообщений обычно гарантирует хотя бы одну доставку. Обработчики событий, которые не являются идемпотентными, должны самостоятельно обнаружить и отвергнуть повторяющиеся события. В этом случае event sourcing-фреймворк может помочь путем присвоения каждому событию автоинкрементного идентификатора. Обработчик событий затем может обнаружить дубликаты, отслеживая максимальный идентификатор событий, которые он уже обработал.
Еще одной проблемой event sourcing является то, что схема событий (и снапшотов!) будет развиваться с течением времени. Поскольку события сохраняются навсегда, то для реконструкции состояния агрегата сервису может понадобиться обработать события, соответствующие нескольким различным версиям схемы. Один из способов упростить сервис — заставить event sourcing-фреймворк приводить все события к последней версии схемы, когда он загружает их из хранилища событий. В результате сервису нужно будет только обработать только последнюю версию событий.
Другим недостатком event sourcing является то, что запрос в хранилище событий может быть сам по себе сложной задачей. Представим, что вам нужно найти клиентов, достойных выдачи кредита, имеющих низкий кредитный лимит. Вы не можете просто написать SELECT * FROM CUSTOMER WHERE CREDIT_LIMIT <? AND CREATION_DATE >?.. Столбца, содержащего кредитный лимит, не существует. Вместо этого вы должны использовать более сложный и потенциально неэффективный запрос, содержащий вложенные SELECT для вычисления кредитного лимита путем обработки события, устанавливающие начальный кредитный лимит и затем меняющие его. Что еще хуже, NoSQL-хранилища событий, как правило, поддерживают поиск только по первичному ключу. Поэтому вы должны реализовывать запросы с помощью подхода Command Query Responsibility Segregation (CQRS).
Реализация запросов с помощью CQRS
Event sourcing является одним из основных препятствий для реализации эффективных запросов в микросервисной архитектуре. Однако это не единственная проблема. Рассмотрим, например, SQL-запрос, который находит новых клиентов, сделавших дорогие заказы.
SELECT *
FROM CUSTOMER c, ORDER o
WHERE
c.id = o.ID
AND o.ORDER_TOTAL > 100000
AND o.STATE = 'SHIPPED'
AND c.CREATION_DATE > ?В микросервисной архитектуре вы не можете соединить в одном запросе таблицы CUSTOMER и ORDER. Каждая таблица принадлежит своему сервису и доступна только через API этого сервиса. Вы не можете писать традиционные запросы, которые соединяют (join) таблицы, принадлежащие различным сервисам. Event sourcing усугубляет ситуацию, мешая писать простые прямые запросы. Давайте посмотрим на способ реализации запросов в микросервисной архитектуре.
Использование CQRS
Хорошим способом реализации запросов является использование архитектурного паттерна, известного как Command Query Responsibility Segregation (CQRS). Приложение разбивается на две части:
- командная часть обрабатывает команды (например, HTTP POST, PUT, DELETE) для создания, обновления и удаления агрегатов. Эти агрегаты, конечно же, реализованы с использованием Event sourcing.
- запросная часть приложения обрабатывает запросы (например, HTTP GET), запрашивая один или несколько материализованных представлений (materialized views) агрегатов. Запросная часть поддерживает представления синхронизированными с агрегатами, подписавшись на события, публикуемые командной частью.
В зависимости от требований, запросная часть приложения может использовать одну или несколько следующих баз данных:
| Если вам нужно | Тогда используйте | Например |
|---|---|---|
| Поиск JSON-объектов по первичному ключу | Документоориентированную базу данных, например, MongoGB, или хранилище данных типа «ключ — значение», например, Redis. | Реализация истории заказов с помощью MongoDB документа клиента, содержащего все его заказы. |
| Обычный поиск JSON-объектов | Документоориентированную базу данных, например, MongoGB. | Реализация представления для клиентов с помощью MongoDB. |
| Полнотекстовый поиск | Движок для полнотекстового поиска, например, Elasticsearch. | Реализация полнотекстового поиска в заказах с помощью Elasticsearch документов для каждого заказа. |
| Графовый запрос | Графовая система управления базами данных, например, Neo4j. | Реализация системы обнаружения мошенничества с помощью графа клиентов, заказов и других данных. |
| Традиционные SQL-запросы | РСУБД | Стандартные бизнес-отчеты и аналитика. |
Во многих отношениях, CQRS — это более общий событийно-ориентированный вариант широко применяемого подхода использования РСУБД в качестве хранилища данных и поискового движка для полнотекстового поиска (вроде Elasticsearch). CQRS использует более широкий диапазон типов баз данных, а не полнотекстовые поисковые движки. Кроме того, за счет подписки на события он обновляет представления запросной части приложения почти в реальном времени.
На следующей иллюстрации показана схема CQRS применительно к интернет-магазину.
Сервисы Customer Service и Order Service входят в командную часть приложения. Они предоставляют API-интерфейсы для создания и обновления клиентов и заказов. Сервис Customer View Service входит в запросную часть. Он предоставляет API для получения данных о клиентах с помощью запросов.
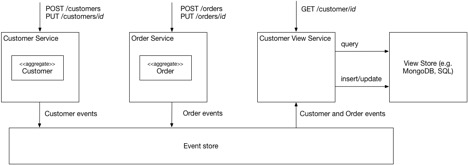
Customer View Service подписывается на события, публикуемые командной частью приложения, и обновляет хранилище представлений, реализованное на MongoDB. Коллекция MongoDB содержит документы, по одному на каждого клиента. У каждого документа есть атрибуты, описывающие конкретного клиента, а также атрибут с последними заказами клиента. Эта коллекция поддерживает разнообразные запросы, включая вышеописанные.
Преимущества и недостатки CQRS
Основное преимущество CQRS заключается в том, что благодаря ему появляется возможность реализовывать запросы в микросервисной архитектуре, особенно использующие event sourcing. Это позволяет приложению эффективно поддерживать разнообразный набор запросов. Другим преимуществом является то, что разделение ответственности зачастую упрощает командную и запросную части приложения.
Одним из недостатков является то, что CQRS требует дополнительных усилий по разработке и эксплуатации системы. Необходимо создать и развернуть сервис запросной части, который умеет обновлять представления и делать запросы к ним. Кроме того, необходимо развернуть хранилище представлений.
Другой недостаток CQRS связан с временным лагом между командами и запросами. Как и следовало ожидать, существует задержка между моментом, когда командная часть обновляет агрегат, и когда представления запросной части готовы отразить эти изменения. Клиентское приложение, которое обновляет агрегат, а затем сразу же делает запрос с использованием представлений, может увидеть предыдущую версию агрегата. Поэтому приложение должно быть написано таким образом, чтобы не допустить получения пользователем этого потенциального несоответствия.
Резюме
Одна из основных проблем при использовании событий для поддержания целостности данных между сервисами — это атомарное обновление базы данных и одновременная публикация событий. Традиционное решение заключается в использовании распределенных транзакций, с задействованием базы данных и брокера сообщений. Однако этот подход не является жизнеспособным для современных приложений. Лучшим решением является использование Event sourcing, событийно-ориентированного подхода к проектированию бизнес-логики и системы сохранения состояния.
Еще одной проблемой в микросервисной архитектуре представляют собой запросы. В них часто необходимо объединять данные, принадлежащие нескольким сервисам. Однако больше нельзя так просто использовать соединения (joins), так как данные являются приватными для каждого сервиса. Еvent sourcing еще более затрудняет эффективную реализацию запросов, так как текущее состояние не хранится само по себе. Решение заключается в использовании CQRS и поддержании в актуальном состоянии одного или более материализованного представления, к которому легко можно делать запросы.