Множество программистов, которые пишут крутые и полезные программы, подобно тем, что мы видим в Интернете, или ежедневно используем, не имеют достаточной теоретической базы в области информатики. Несмотря на это, они все же создают интересные решения и мы им благодарны за это.
Однако, теоретические познания в информатике могут быть весьма полезными. Данная статья рассчитана на программистов, которые хорошо овладели своей специальностью, но не имеют должной академической подготовки. Речь пойдет об одном из самых полезных навыков – оценке эффективности алгоритмов, или сложности алгоритмов.
Естественно, в короткой статье невозможно полностью объяснить все приемы и передать все те знания, что необходимы для полного понимания вопроса. Например, в Массачусетском технологическом институте (MIT), оценке сложности посвящен целый курс, причем не такой уж маленький. Крайне рекомендую его изучить, надеюсь, знания английского вам позволят. Кстати, о необходимости языка для программиста тоже хочется много всего сказать, но не сейчас.
Когда задача имеет несколько похожих на первый взгляд алгоритмических решений, бывает сложно понять, какое из них на практике окажется наиболее оптимальным.
С этой целью, используются математические обозначения, самым известным из которых является «большое О» (Big O), для оценки асимптотики функций. Под асимптотикой понимается характер изменения функции при ее стремлении к определенной точке.
Говоря проще, мы пытаемся проанализировать, как будет расти наш график (чаще всего нагрузки на ЦП), с ростом входных данных, которые обозначаются буквой n.
Исходя из вышесказанного, O(ƒ(n)) и есть сложность алгоритма.
На самом деле, существует на только «большое О», но и ряд других обозначений. Рассмотрим их:
O(ƒ(n)) – (Big-O) – верхняя граница, «не хуже чем»
o(ƒ(n)) – (Little-o) – верхняя граница, «лучше чем»
Ω(ƒ(n)) – (Omega) – нижняя граница, «не лучше чем»
Θ(ƒ(n)) – (Theta) – точная оценка.
На практике, в подавляющем большинстве, используют оценку Big O, как наиболее простую в вычислении. Нам ведь важен не столько точный математический результат, сколько приблизительная оценка «качества» нашего алгоритма.
В целом, расчет заключается в определении количества операций, или количества шагов, над входными данными. Например, в качестве n возьмем структуру данных – массив — из неопределенного количества элементов и выведем его на экран:
- function printArray($n) {
- foreach ($n as $member) {
- echo $member;
- }
- }
Сложность printArray будет O(n), потому что количество операций равно количеству элементов. Про такой рост еще говорят, что он — линейный. Или, например, у нас имеется вложенный цикл такого вида:
- foreach ($n as $member) {
- foreach ($n as $element) {
- echo $element;
- }
- }
Здесь мы выполнили n операций n раз. Сложность в данном случае ужасная, она показывает степенной рост – O(n²). Если нам требуется еще один такой же вложенный цикл, получится n³ и так далее.
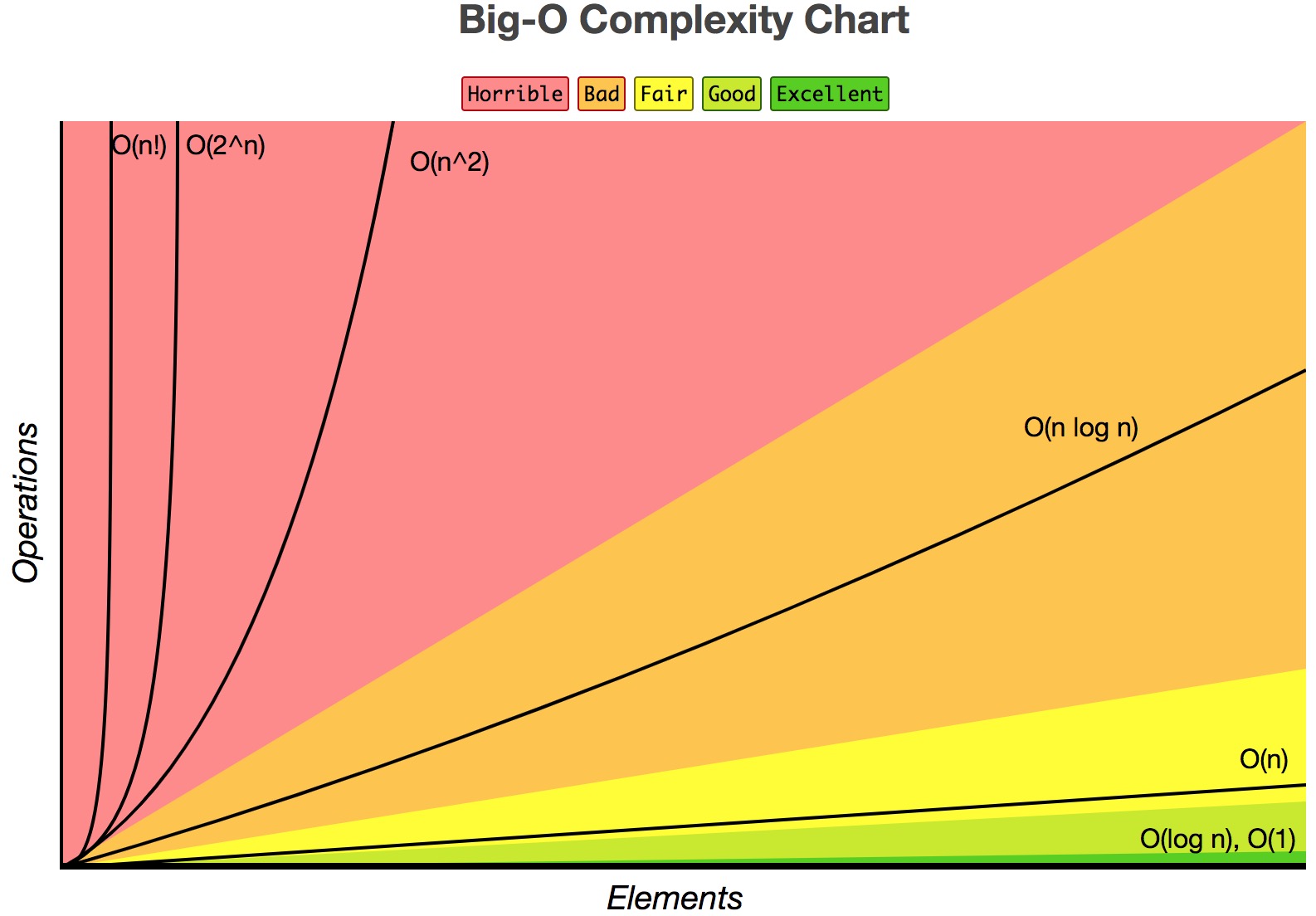
Рассмотрим еще один интересный пример вычисления произвольно взятого элемента ряда Фибоначчи. Классическая формула гласит: Fn = Fn-1 + Fn-2 для n >= 2.
Данный алгоритм можно реализовать с помощью рекурсии:
- function fibonacci($n)
- {
- if ($n <= 1) {
- return $n;
- } else {
- return fibonacci($n — 1) + fibonacci($n — 2);
- }
- }
- echo fibonacci(10); //55
Кажется нормальное решение, даже красивое для неопытного взгляда. Но что если потребуется вычислить 100-е число? Не так уж и много, подумаешь, всего лишь сотое. Однако, сложность данного алгоритма настолько высока, что даже незначительное увеличение входного числа, дает огромный рост.
Давайте рассмотрим наше решение более детально. Данный пример интересен еще и тем, что в качестве входных данных у нас одно единственное число, а не массив. Но, тем не менее, количество операций тесно связано с его значением.
На каждой «итерации» рекурсии, мы удваиваем количество операций, вызываем ее дважды. То есть 2*2*2*2… Получается дерево. Поскольку условием задано, что если n <= 1, то возвращаем само значение, на «листьях» кол-во операций не удваивается. Но если говорить про Big O («не хуже»), то можно приблизительно судить о сложности, что она O(2n). Можно рассчитать более точно ~Θ(1.6n), но на практике чаще всего достаточно приблизительной оценки. Видим экспоненциальный рост, который еще хуже степенного.
Итак, мы выяснили, что наш алгоритм расчета числа Фибоначчи ужасен. Что делать? Очевидно, разработать более эффективное решение!
Попробуем сделать по-другому, просто возьмем да просуммируем в цикле все числа, начиная с нуля, вплоть до искомого:
- function fibonacci($n)
- {
- $prevOne = 0;
- $prevTwo = 1;
- $current = 0;
- if ($n == 1) {
- return 1;
- }
- for ($i = 1; $i < $n; $i++) {
- $current = $prevOne + $prevTwo;
- $prevOne = $prevTwo;
- $prevTwo = $current;
- }
- return $current;
- }
Решение не блещет изяществом, однако его эффективность можно оценить как O(n). То есть оно, на самом деле, гораздо лучше предыдущего. В принципе, на этом можно было бы остановиться, мы добились вполне хороших результатов. Далеко не каждый алгоритм, в реальной жизни, удается оптимизировать до такого состояния. Но мы попробуем пойти дальше.
Задача в примере чисто математическая, посмотрим, что еще написано в справочнике. Ага, оказывается, есть куда более эффективное, с точки зрения алгоритмов, решение: формула Бине. Из нее следует, что для всех n >= 0, Fn — есть ближайшее целое число к φn/√5, где φ – золотое сечение.
Перепишем нашу функцию:
- function fibonacci($n)
- {
- $goldenRatio = (1 + sqrt(5))/2;
- return round(pow($goldenRatio, $n)/sqrt(5));
- }
Теперь у нас самый лучший по эффективности алгоритм, который только можно себе представить. Его сложность вообще не зависит от n, количество операций константно и ничтожно мало. Про такие обычно пишут O(1).
Следует отметить, в ситуациях, где не предвидится рост входных данных, их количество всегда константно и невелико, алгоритмическая сложность не имеет большого значения. Если смотреть на график, то в околонулевой точке все функции показывают примерно одинаковые результаты для современных компьютеров.
Влияние плохого алгоритма, в таком случае, начинает ощущаться лишь на больших нагрузках. Однако, даже в этом случае, часто слабым звеном системы становится совершенно не ЦП, а, допустим, пропускная способность интернет подключения. Или объем RAM, хотя BigO вычисляют и для оперативной памяти, да и вообще для потребления любых ресурсов компьютера.
Совсем другое дело, когда речь идет об устройствах с ограниченной производительностью, таких как смартфоны и уж тем более, если требуется программировать микроконтроллеры.