Последние 3 года я занимался приложением, которое работает на Google App Engine. Google предлагает увлекательный, уникальный сервис. Все, что вы прочитаете здесь, — мое личное мнение.
Облако Google (est. 2008)
Прежде всего обозначим, что такое Google App Engine (GAE). Это платформа для запуска ваших веб-приложений, таких как Heroku. Но они немного отличаются, если присмотреться. Heroku — универсальная платформа для облачных вычислений, как и AWS. Но, опять же, они разные. Постараюсь объяснить.
Google запустил GAE в 2008 году, когда облачные вычисления еще были в зачаточном состоянии. Amazon был впереди, когда Google начал сдавать в аренду свою IT-инфраструктуру в 2006 году. Но с GAE Google очень рано предложил сложную платформу как услугу (PaaS), которая соответствовала Amazon со своим сервисом Elastic Beanstalk в 2011. Что особенного в GAE?
GAE — полностью управляемая платформа приложений. Я не знаю платформы, которая приближается к полному пакету GAE: управление журналом, доставка почты, масштабирование, memcache, манипуляция изображениями, распределенные задания Cron, балансировка нагрузки, управление версиями, очередь задач, поиск, анализ производительности, облачная отладка, сеть доставки контента — и это без упоминания о вспомогательных службах, появившихся в облаке Google, таких как SQL, BigQuery, хранение файлов… список можно продолжить.
Используя Google App Engine, вы можете запустить приложение поверх лучшей в мире (возможно) инфраструктуры. Кроме того, вы получаете функциональность «из коробки», которая потребует по крайней мере, дюжины дополнений от третьих сторон на Heroku или нескольких недель установки. Это призыв GAE.
Достойные упоминания приложения, которые работают на GAE, включают Snapchat и Khan Academy.
Разработка
Веб-приложение, над которым я работал все это время, представляет собой одно большое приложение Java. App Engine также поддерживает Python, PHP и Go. Вы можете задаться вопросом, почему выбор настолько ограничен. Чтобы иметь полностью управляемую среду, Google должен интегрировать платформу с окружающей средой. Можно сказать, что среда и платформа тесно связаны. Это требует больших усилий и инвестиций, что становится ясным после начала разработки для GAE.
SDK
Каждое приложение должно применять специальный SDK (Software Development Kit) для использования API, предлагаемых GAE. SDK огромен. Например, загрузка Java SDK составляет примерно 190 МБ. Некоторые JAR не нужны в большинстве случаев использования, а некоторые нужны только во время разработки.
SDK — не только мост в мир Google App Engine, он также служит симулятором локальной машины. Практически для каждого сценария использования GAE API есть шаблон, который вы можете использовать как основу для вашего проекта.Что это означает? Во-первых, при запуске приложения локально вы будете очень близки к тому, как оно будет вести себя на производстве. Во-вторых, вы можете легко написать тесты интеграции с API. Как правило, это может вас далеко завести; разница между производственным и заглушенным поведением довольно невелика.
Java APIs
Говоря об API, вы удивляетесь, когда используете некоторые Java-API. Поскольку GAE запускает приложение в песочнице, он запрещает использование определенных Java-API. Основные ограничения: запись в файловую систему, некоторые методы java.lang.System и использование Java Native Interface (JNI). Есть также особенности использования потоков и сокетов, но об этом позже.
Интересная вещь: Java SDK фактически гарантирует, что вы не используете ограниченные API локально. Когда вы запускаете приложение или просто тест интеграции, в нем используется агент Java, который отслеживает ваш вызов каждого метода. Он немедленно выдает исключение для любого обнаруженного нарушения. Это полезно при раннем обнаружении нарушений, а не только в производстве, но имеет раздражающий побочный эффект: при определении эффективности приложения подавляющее количество проверок будет подаваться со стороны агента. В конце концов оказывается, что судить о фактической производительности приложения трудно, так как чем больше вызовов методов вы делаете, тем больше накладных расходов генерирует агент.
Java Development Kit (JDK)
Следующее, что вы могли заметить в начале разработки: вы не можете использовать Java 8. Несмотря на то что срок жизни Java 7 закончился в 2015 году, он все еще очень живой. Третья по-важности проблема на отслеживании проблем GAE — поддержка Java 8 (вторая проблема — поддержка Python 3). Java 8 был создан в 2013. С тех пор единственная новость о каком-либо прогрессе в этом вопросе — сообщение в списке рассылки App Engine с 2016 года, в котором говорится, что инженеры активно работают. Ну, неплохо.
Очевидно, что это ограничение сильно раздражает любого разработчика. Лично для меня недостающая поддержка лямбды достаточно ощутима. Конечно, можно перейти на один из многих языков JVM, таких как Groovy, Scala или Kotlin, которые предлагают гораздо больше возможностей, чем Java 8. Но это дорогостоящие и рискованные инвестиции для нашего проекта. Мы также исследовали возможности retrolambda, бэкапорта лямбды для Java 7, но не гнались за ним, хотя в первых тестах он выглядел многообещающим.
Оставаться на старой версии — нести ответственность за бизнес. Это затрудняет поиск разработчиков. В общем, безопасность приложений находится под угрозой. Поддержка Google сообщила, что мы все равно будем получать исправления безопасности для производства JDK 7. В итоге все крупные библиотеки, такие как Spring, перестанут поддерживать JDK7. Это тупик.
Развертывание
Чтобы развернуть приложение, вам необходимо создать файл конфигурации appengine-web.xml. Там вы указываете ID приложения и версию плюс некоторые дополнительные настройки, например, указывая приложение как threadsafe, чтобы иметь возможность одновременно получать несколько запросов на экземпляр.
Загрузка
App Engine рассчитывает получить приложение Java в виде упакованного файла WAR. Вы можете загрузить его на свои серверы с помощью скрипта appcfg из SDK. Eсть плагины для Maven и Gradle, которые загружают так же просто, как пишут mvn appengine:update. Загрузка может занять довольно много времени для типичных приложений Java, вам нужно быстрое подключение к интернету. Как только процесс завершится, вы увидите свою недавно развернутую версию в Google Cloud Console:

Статистические файлы
Статические файлы, такие как изображения, таблицы стилей и скрипты, являются частью любого веб-приложения. В appengine-web.xml файлы можно пометить как статические. Google будет обслуживать эти файлы напрямую – без использования вашего приложения. Это не совсем Content Delivery Network (CDN), поскольку она не распространяется на сотни пограничных узлов, но помогает снизить нагрузку на серверы.
Версии
Положительная сторона App Engine в следующем: все, что вы разворачиваете, имеет определенную версию. Доступ к любой версии можно получить по адресу https: // <version> -dot- <app-id>.appspot.com. Но какая из них актуальна?
Можно пометить версию как версию по умолчанию. Это означает, что при переходе на https: / / <App-id>.appspot.com (или доменное имя, которое вы указали для приложения) это будет версия, получающая все запросы. Переключение версии по умолчанию очень просто: требуется только клик по кнопке или простая команда терминала. GAE может немедленно переключиться или перенести ваш трафик, чтобы предотвратить подавление новой версии.
Есть еще один вариант (его мы никогда не использовали), который позволяет распределять трафик между несколькими версиями. Это дает возможность постепенно разворачивать новую версию, предоставляя ей только часть пользовательской базы, прежде чем сделать версию доступной для всех.
Поскольку создавать новые версии и переключать производственный трафик между ними просто, GAE — идеальная платформа для развертывания сине-зеленого деплоя. Каждый раз, когда нам приходилось откатываться из-за ошибки в новой версии, разворачивать деплой было легко. Непрерывная доставка также должна быть достижима с помощью написания нескольких разумных скриптов деплоя.
Примеры
Каждая версия может запускать любое количество экземпляров (единственным ограничением является ваша кредитная карта). Фактическое число — результат входящего трафика и конфигурации масштабирования вашего приложения; мы рассмотрим это позже. Google будет распределять входящие запросы между всеми запущенными экземплярами этой версии. Вы можете увидеть список экземпляров, включая некоторые основные показатели, такие как запросы и латентность в Google Cloud Console:

Давайте будем откровенны: опции оборудования, которые вы можете выбрать для запуска этих экземпляров, ничтожны. App Engine в основном предлагает четыре разных класса экземпляров: от 128 Мбайт и 600 МГц (вы читаете это правильно) до 1024 МБ и 2,4 ГГц. Да, опять же, это правда. И действительно грустно. На ноутбуке разработчика наше приложение запускалось почти в два раза быстрее, чем в производстве.
Сервисы
До сих пор я говорил только об одном монолитном приложении. Но что делать, если ваше приложение состоит из нескольких сервисов? Каждое приложение — сервис. Если у вас только одно приложение, оно просто называется default. Вы можете разделить приложение напрямую через https://<version>-dot-<service>-dot-<app-id>.appspot.com.
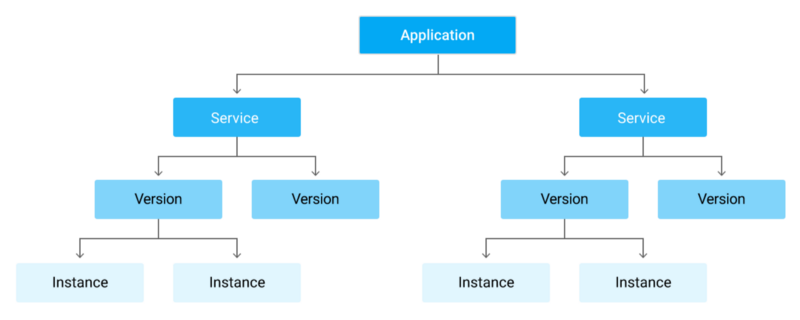
Вы можете легко развернуть несколько версий каждого сервиса, масштабировать и контролировать их отдельно. И поскольку каждая служба отделена от других, можно запускать любую комбинацию поддерживаемых языков. Однако, к сожалению, некоторые параметры конфигурации распределены между всеми службами. Поэтому они изолированы не идеально. Тем не менее, GAE подходит для микросервисов. В Google есть подробная инструкция.
По причинам, которые станут понятными позже, мы решили разделить наше приложение на два сервиса: frontend (ориентированный на пользователя) и backend (фоновая работа). Но фактически мы не разделили монолит на две части (это заняло бы месяцы), а просто развернули одно и то же приложение дважды и отправили пользователей в один сервис, а фоновую работу — в другой.
Операции
Давайте поговорим о том, что значит запускать приложение в App Engine. Как вы увидите, он накладывает ряд ограничений. Мрачновато. Позже вы поймете, почему.
Запуск приложения
Когда App Engine запускает новый экземпляр, приложение должно инициализировать. Он либо напрямую отправит HTTP-запрос от пользователя в приложение, либо, если это позволяют настройки и масштабирование, отправит так называемый запрос на разогрев. В любом случае первый запрос называется запросом загрузки.
С другой стороны, сам экземпляр быстро запускается. Если вы запускали сервер в облаке до этого, должно быть, вы ждали более минуты. Не на GAE. Думаю, Google держит пул серверов, готовых к работе. Затруднением всегда будет ваше приложение. Запуск нашего приложения занял более 40 секунд. Поэтому, если мы не хотим разделять огромный монолит на отдельные сервисы, нужно, чтобы он начал работать более эффективно. Приложение использует Spring. У Google даже есть специальная запись для документации только для этого: оптимизация Spring Framework для приложений App Engine. Там мы нашли вдохновение для самой важной оптимизации запуска.
Мы избавились от сканирования траектории Spring. Это медленно в App Engine (вероятно, из-за ужасного процессора). К счастью, есть библиотека под названием classindex. Она записывает полный путь классов со специальной аннотацией к текстовому файлу. Просто прочитав бины из текстового файла, инициализация Spring снизилась примерно на 8–10 секунд.
Обработка запросов
Первое, что я должен упомянуть, — требование App Engine обрабатывать запрос пользователя в течение 60 секунд и фоновый запрос в течение 10 минут. Когда приложение слишком долго реагирует на запрос, он прерывается с кодом состояния 500, и генерируется исключение DeadlineExceededException.
Это не должно быть проблемой. Если ваше приложение отвечает более 60 секунд, скорее всего, вы потеряете пользователя. Но поскольку экземпляр запускается через HTTP-запрос, это также означает, что он должен запускаться через 60 секунд. В производстве мы наблюдали изменения во времени запуска до 10 секунд. Это означает, что теперь у вас менее 50 секунд, чтобы запустить приложение. Такой долгий запуск — не редкость для Java-приложения.
Я хотел бы выделить одну приятную маленькую функцию — географические заголовки HTTP для каждого входящего запроса пользователя. Google добавляет заголовки, которые содержат страну пользователя, регион, город, а также широту и долготу указанного города. Это может быть очень полезно, например, для предварительного заполнения кодов стран телефонного номера или обнаружения необычных мест входа в учетную запись. По моим наблюдениям, точность достаточно высокая. Как правило, получать подобную информацию с таким уровнем точности от сторонних разработчиков или баз данных трудоемко и/или дорого.. Так что бесплатное ее предоставление App Engine — хороший бонус.
Проделанная работа
Потоки
Как упоминалось ранее, существуют ограничения на использование потоков Java. В то время как можно запустить новый поток, хотя и с помощью настраиваемого GAE ThreadManager, поток не может «пережить» запрос, в котором был создан. Это может раздражать, так как сторонние библиотеки, конечно, не следуют ограничениям App Engine. Найти совместимую библиотеку или адаптировать, казалось бы, несовместимую, стоило нам много пота, слез и труда на протяжении многих лет. Например, мы не можем применять библиотеку метрик Dropwizard »из коробки», так как она использует фоновый поток.
Очередь
Но есть и другие способы выполнения фоновой работы: в облаке вы применяете подход «разделяй и властвуй» на уровне экземпляра. С помощью очередей задач вы можете запустить работу для последующей обработки. Например, когда необходимо отправить электронное письмо, вы можете поставить новую задачу с нагрузкой и URL-адресом в очереди push. Затем один из ваших экземпляров получит нагрузку в качестве POST HTTP-запроса для указанной конечной точки. Если не удастся, App Engine повторит операцию.
Шаблон действительно помогает, когда у вас много работы. Запустите пакет задач, которые выполняются изолированно. App Engine позаботится об отказе. Нет необходимости в пользовательском повторном коде. Представьте себе, насколько неудобно было бы без него. пришлось бы запускать сотни задач, и если бы произошла ошибка, нужно было бы либо остановиться, либо начать с нуля или тщательно отследить, что не удалось, и снова поставить задачи в очередь для другой попытки.
Как и остальная часть App Engine, очереди задач красиво масштабируются. Очередь может принимать практически неограниченные задачи. Минусом является нагрузка до 1 МБ. Обычно мы просто передаем ссылки на данные в очередь. Но тогда нужно проявлять особую осторожность при обработке данных, так как между временем постановки задачи и временем ее завершения может что-то произойти.
Очереди настраиваются в файле queue.xml. Ниже приведен пример очереди push, которая запускает до одной задачи в секунду с максимум двумя повторениями:
<queue>
<name>my-push-queue</name>
<rate>1/s</rate>
<retry-parameters>
<task-retry-limit>2</task-retry-limit>
</retry-parameters>
</queue>Cron
Еще один чрезвычайно ценный инструмент — распределенный Cron. В cron.xml вы можете настроить GAE, чтобы он выдавал запросы через определенные промежутки времени. Это просто запросы HTTP GET, которые получит один из ваших экземпляров. Наименьший возможный интервал – 1 раз в минуту. Это очень полезно для регулярных отчетов, электронной почты и очистки.
Вот как выглядит запись в cron.xml :
<cron>
<url>/tasks/summary</url>
<schedule>every 24 hours</schedule>
</cron>Задача Cron также может быть объединена с очередями по запросу: они позволяют активно извлекать пакет задач из очереди. В зависимости от варианта использования создание экземпляра с большим количеством задач в пакете может быть более эффективным, чем передача их в экземпляр по отдельности.
Как и все другие файлы конфигурации App Engine, cron.xml является общим для всех служб и версий приложения. Это может раздражать. Когда мы разворачивали версию, в которую была добавлена новая запись Cron, App Engine начинал отправлять запросы не существующей в действующей версии конечной точке. Предполагаю, что при использовании App Engine для размещения микросервисов проблемы серьезнее.
Кроме того, задачи Cron не запускаются локально, так как многие работы, как правило, запланированы вне напряженного времени и даже не будут запускаться во время рабочего дня. Но некоторые запускаются каждые несколько минут или часов и вызывают интерес. Например, они могут инициировать уведомления, видимые локально. В конце концов вы введете изменение, которое приведет к нежелательному поведению (как это неоднократно повторялось в нашем проекте), и его локальное обнаружение может помешать вам его отправить. Но моделирование рабочих мест Cron локально сложно (к сожалению, мы не думали об этом). Вероятно, потребуется написать внешний инструмент, который будет анализировать cron.XML, а затем проверять по конечным точкам (фу!).
Масштабирование
App Engine позаботится о масштабировании количества экземпляров на основе трафика. В зависимости от того, как вы настроили свое приложение, можно использовать один из трех режимов:
- Автоматический: будет масштабировать количество экземпляров на основе таких показателей, как частота запросов и задержка ответа. Если у вас большой трафик или приложение медленно реагирует, у вас будет разворачиваться больше экземпляров.
- Мануальный: похож на старые добрые виртуальные частные серверы. Вы сообщаете Google, сколько экземпляров хотите, и Google поставляет их. Размер фиксированного экземпляра полезен, если вы точно знаете, какой трафик собираетесь получить.
- Основной: по существу то же самое, что и режим мануального масштабирования, но когда экземпляр переходит в режим ожидания, он отключается.
Наиболее полезным и интересным здесь, безусловно, является автоматический режим. О «внутренней работе» расскажут параметры max_concurrent_requests, max_idle_instances, min_idle_instances и max_pending_latency. Процитирую инструкцию App Engine:
Планировщик App Engine решает, обслуживать ли каждый новый запрос существующим экземпляром (либо бездействующим, либо принимать параллельные запросы), помещать запрос в очередь ожидающих запросов или запускать новый экземпляр для этого запроса. В решении учитывается количество доступных экземпляров, насколько быстро ваше приложение обслуживает запросы (его латентность) и сколько времени требуется, чтобы развернуть новый экземпляр.
Каждый раз, когда мы пытались настроить эти цифры, мне казалось, что мы занимаемся черной магией. Очень сложно найти правильную настройку. Тем не менее, эти цифры определяют реальную производительность приложения и влияют на ежемесячный счет.
Но в целом автоматическое масштабирование довольно зловещее. Оно особенно подходит для работы с фоновыми процессами (например, для создания отчетов, отправки электронных писем), поскольку это часто происходит как внезапный всплеск.
Java не подходит для такого автоматического масштабирования из-за медленного времени запуска. Что еще хуже, для планировщика очень часто назначается запрос на запуск (холодного) экземпляра. С 2012 года существует проблема, связанная с запросами пользователей, которые никогда не блокируются для холодных экземпляров. Google не прокомментировал эту проблемы, кроме изменения статуса на «принято».
Это также объясняет, почему мы разделяем приложение на два сервиса. Раньше мы замечали, что с увеличением фоновых запросов страдали пользовательские. Это связано с тем, что App Engine значительно увеличил количество экземпляров. Поскольку запросы равномерно распределены по всем экземплярам, в холодные экземпляры стало попадать больше запросов пользователей. Разделив приложение, мы сократили количество запросов. Кроме того, мы смогли применить различные стратегии масштабирования для этих двух сервисов.
Последнее: в сайд-проекте я использовал Go On App Engine и обнаружил новую перспективу в App Engine. Среди особенностей Go — возможность запуска приложения практически мгновенно. Это делает App Engine и Go идеальным сочетанием, как Бэтмен и Робин. Вместе они воплощают все, чего я лично ожидал от облака с самого начала. Оно действительно масштабируется до рабочей нагрузки, и делает это без усилий. Даже безумные аппаратные опции не представляют реальную проблему для Go.
Данные
Когда запущен App Engine, единственные параметры базы данных — Google Datastore для структурированных данных и Google Blobstore для двоичных данных. С тех пор они добавили Google Cloud SQL (управляемый MySQL) и Google Cloud Storage (например, Amazon S3), который заменил Blobstore. С самого начала App Engine также предлагал управляемый Memcache.
Раньше было очень сложно подключиться к сторонней базе данных, поскольку HTTP можно было использовать только для связи. Но обычно для баз данных требуется необработанный TCP. Ситуация изменилась несколько лет назад, когда был выпущен Socket API. Но он все еще находится в Beta, что делает выбор неоднозначным для критически важного использования. Таким образом, с точки зрения базы данных, все еще существует vendor lock-in.
Во всяком случае в начале было только хранилище данных.
Datastore
Datastore — проприетарная база данных NoSQL, полностью управляемая Google. Она отличается от всего, чем я пользовался. Это массовое масштабирование с уникальными чертами, гарантией и ограничениями.
На раннем этапе Datastore был основан на настройке master-slave, в которой соблюдалась строгая последовательность чтения. Спустя несколько лет после того, как Datastore произвел несколько серьезных выплат, Google представил новый вариант конфигурации — «Высокая репликация». API остался прежним, но латентность увеличилась, и некоторые чтения стали последовательными (подробнее об этом позже). Потенциал роста был значительно выше. Он даже имеет SLA на время безотказной работы на 99,95%. Я никогда не испытывал проблем с доступностью Datastore.
Объекты
Основы Datastore просты. Вы можете читать и писать объекты. Они классифицируются под определенным типом. Сущность состоит из свойств. Свойство имеет имя и значение, которому присвоен определенный тип. Подобно string, boolean, float или integer. У каждого объекта есть уникальный ключ.
Запись
Нет никакой схемы. Объекты с одинаковым видом могут выглядеть совершенно по-разному. Это делает разработку элементарной: просто добавьте новое свойство и сохраните его. Обратная сторона заключается в том, что нужно будет написать пользовательский код миграции для переименования свойств, потому что объект не может быть обновлен на месте — он должен быть загружен, изменен и сохранен снова. В зависимости от объема объектов обновление может стать нетривиальной задачей, поскольку, возможно, придется использовать очередь задач, чтобы обойти требования времени запроса. По моему опыту, это приводит к старым именам, так как рефакторинг дорогостоящий и опасный.
Есть некоторые ограничения для работы с объектами. Двумя наиболее важными являются следующие:
- объект может занимать всего 1 МБ, включая дополнительные метаданные кодированного объекта;
- вы можете писать только в объект (группу, если быть точным) до одного раза в секунду.
На практике это может быть проблемой. Мы редко достигали лимита размера, но когда достигали, было больно. Данные клиента могут потеряться. Когда вы нажимаете ограничение скорости записи, обычно это получается при следующей попытке. И конечно вы должны проектировать ваше приложение таким образом, чтобы снизить вероятность подобных проблем. Например, что-то вроде регулярно обновляемого счетчика требует много работы, чтобы заставить его работать правильно. Google имеет инструкцию по использованию сегментирования для создания счетчика.
Чтение
Объект может быть извлечен с помощью его ключа или запроса. Чтение по ключу строго согласовано. Это означает, что вы получите последние данные, даже если обновили объект прямо перед их получением. Однако это не относится к запросам. Они в конечном итоге последовательны, поэтому записи не всегда отражаются сразу. Это может привести к проблемам, которые, придется предотвращать, используя, например, моделирование данных (один из вариантов — применение мнемоники в качестве ключа) или специальные функции Datastore.
В запросе всегда указываются тип объекта и необязательные фильтры и / или порядок сортировки. Каждое свойство, используемое в фильтре или в качестве ключа сортировки, должно быть проиндексировано. Добавление индекса может быть реализовано только как часть обычной операции записи. Не автоматически в фоновом режиме, как в большинстве баз данных SQL. Индекс также увеличит время операции записи и стоимость (об этом позже).
Если запрос включает несколько свойств, для него требуется мультииндекс. Он должен быть указан в файле конфигурации datastore-indexes.xml. Вот пример:
<datastore-index kind="Employee" ancestor="false">
<property name="lastName" direction="asc" />
<property name="hireDate" direction="desc"
</datastore-index>В отличие от других баз данных, отсутствие мультииндекса не просто приведет к неэффективному, медленному запросу — он может завершится ошибкой. Datastore старается максимально эффективно выполнять запросы. Неравномерные фильтры, например, поддерживают только одно свойство.
Есть несколько других функций, которые я не могу использовать сейчас: например, разбиение на страницы, проекционные запросы и транзакции. Читайте документацию Datastore, чтобы узнать больше.
По сравнению с другими базами данных операции чтения и записи выполняются очень медленно. Основываясь на моих наблюдениях, чтение по ключу занимает в среднем 10–20 мс. Значительные отклонения наблюдаются редко. Предполагаю, что Google сериализует объекты, и только индексы хранятся в памяти.
Ценовая модель следующая: вы платите за сохраненные данные, операции чтения, записи и удаления. Вот и все. Обратите внимание, что памяти базы данных нет в этом списке. Сами операции дешевы: чтение сущностей 100k стоит $ 0.06, операции записи 100k стоят $0.18. Операция записи может быть фактической записью объекта, но и записью каждого индекса. Если вы ничего не пишете, то ничего не платите. Но за одну минуту вы могли писать гигабайты данных. И вот кикер: производительность чтения и записи в основном одинакова для базы данных без объектов.
API
API по сравнению с Datatore — очень низкого уровня. Поэтому для любого серьезного приложения Java нет никакого способа обойти Objectify. Это библиотека, написанная Jeff Schnitzer. Если Google еще не сделал этого, они должны написать ему огромный чек, чтобы сделать App Engine лучше. Jeff Schnitzer написал Objectify для своего бизнеса, но неустанная самоотверженность на протяжении многих лет, обширная документация и поддержка, которую он предлагает на форумах, поражает. С Objectify работа с Datatore стала проще.
Вот пример из документации:
@Entity
class Car {
@Id String vin;
String color;
}ofy().save().entity(new Car("123123", "red")).now();
Car c = ofy().load().type(Car.class).id("123123").now();
ofy().delete().entity(c);Objectify позволяет легко объявлять объекты как простые классы, а затем берет на себя маппинг с Datatore.
Objectify имеет несколько интересных фокусов. Например, он поставляется с кешем первого уровня. Это означает вот что: всякий раз, когда вы запрашиваете объект по ключу, он просматривает кеш области запроса и выясняет, был ли объект уже извлечен. Это может быть полезно для улучшения производительности, но может и сбить с толку: когда вы извлекаете и изменяете объект, но несохраняете его, следующее чтение предоставит измененный объект. Это может привести к Heisenbugs.
Разработка и тестирование
Поскольку App Engine является частной облачной базой данных, его локальное использование невозможно. Когда вы запускаете приложение на своем компьютере, в SDK запускается макет Datastore. Его поведение очень близко к производственной среде, но производительность намного выше, что может ввести в заблуждение.
Для выполнения тестов на Datastore SDK может запустить локальный Datastore. Тем не менее это должна быть другая реализация, так как локальный Datastore ведет себя иначе. Это становится очевидным, когда вы понимаете, что недостающий мультииндекс выдает ошибку при выполнении приложения локально, но не при тестировании одного и того же запроса. За эти годы я случайно выпустил в производство несколько запросов с отсутствующими индексами, хотя у меня был тест. После обращения в службу поддержки они признали недочет и пообещали исправить это. Прошел год — никаких изменений.
Резервные копии
Создание резервных Datastore — жестокий процесс. Существует ручной и автоматический способ. Конечно, при наличии производственного приложения вы бы хотели делать регулярные резервные копии. Официально функция была введена в 2012 году, но все еще находится в Alpha!
При добавлении записи в cron.xml можно запустить процесс резервного копирования. Запись будет включать имена объектов для резервного копирования, а также Google Cloud Storage-корзину, чтобы сохранить их. Когда придет время, он запустит несколько экземпляров Python с кодом резервного копирования, переберет хранилище данных и сохранит их в каком-либо формате резервного копирования на ваш блок. Интересно, что у корзины есть предел хранения файлов, поэтому лучше время от времени менять корзину.
Это худшее в Datastore.
Memcache
Другим важным способом хранения данных в App Engine является Memcache. По умолчанию вы получаете общий Memcache. Это означает, что он работает на максимальной основе, но с ограниченными возможностями. Существует также выделенный Memcache за $ 0,06 за ГБ в час.
Objectify может использовать это как кеш второго уровня. Просто аннотируйте объект с Cache, и он будет спрашивать Memcache перед Datastore и сокращать каждый объект. Это может оказать огромное влияние на производительность. Memcache будет отвечать в течение примерно 5 мс, что намного быстрее, чем Datastore. Я не слышал ни об одной проблеме с кешем. Так что Memcache хорошо работает в производстве.
Big Query
BigQuery — хранилище данных, управляемое Google. Вы импортируете данные, которые могут быть петабайтами, и можете выполнять анализ с помощью пользовательского языка запросов.
Он хорошо интегрируется с Datastore, так как позволяет импортировать файлы резервного копирования Datastore из Google Cloud Storage. Я пользовался интеграцией, но не всегда успешно. Для некоторых объектов я получил загадочную ошибку и не мог понять, что пошло не так. Но некоторые объекты действительно работали. И, немного поиграв с документацией на языке запросов, я создал первые идеи. Все учтено, это был хороший способ провести простой анализ. Наверняка ничего нельзя было сделать без написания специального кода. На самом деле я не использовал весь потенциал сервиса. Все отправленные запросы могли быть сделаны в любой базе данных SQL напрямую, наш набор данных был довольно небольшим. Только из-за особенностей работы Datastore мне пришлось прибегнуть к сервису BigQuery.
Мониторинг
Google Cloud Console предоставляет множество функций для диагностики поведения приложения в процессе производства. Просто взгляните на навигацию Google Cloud Console:
Это результат приобретения Google Stackdriver в 2014 году. Он по-прежнему выглядит как отдельный автономный сервис, но его интеграция в Google Cloud Console улучшается.
Давайте посмотрим на его возможности.
Ведение протокола
Крайне важно быстро и легко получать доступ к логам приложения. Это то, чего не доставало в App Engine. Он не был способен искать приложения во всех версиях. Когда вы что-то искали, нужно было знать, какая версия была в данный момент в сети, или проверять несколько версий. Это было почти непригодно для применения и очень медленно.
С тех пор они добавили полезные фильтры для отображения только определенных модулей, версий, уровней журналов, пользовательских агентов или кодов состояния. App Engine до сих пор не быстрый, но стал намного лучше по сравнению с ранними версиями. Вот как это выглядит:
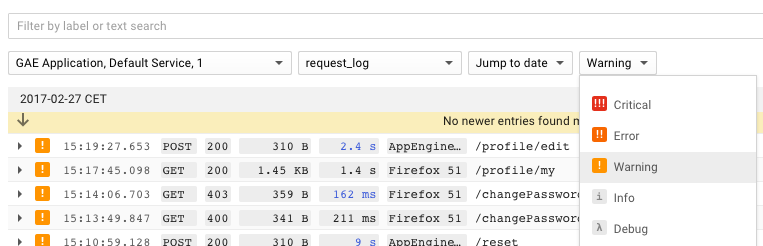
Уникальная идея состоит в том, что журналы группируются по запросу. Во всех других инструментах, с которыми я столкнулся (например, Kibana), вы получите только строки журнала, соответствующие поиску. Вы получаете больше контекста, когда указаны и другие строки журнала. Я считаю, это полезно при исследовании проблем в журналах, так как помогает понять, что произошло. Мне не хватает такой функции в других средствах просмотра журналов.
Еще одна интересная особенность App Engine заключается в том, что каждому входящему HTTP-запросу автоматически присваивается идентификатор. Это может оказаться полезным для корреляции с журналами. Например, во время отправления электронных писем произошло неперехваченное исключение и включился идентификатор запроса. Это делало поиск журналов тривиальным. То же самое можно сделать для отслеживания ошибок интерфейса.
Метрики
Cloud Console предоставляет доступ к нескольким основным метрикам приложения: объем запроса и задержки, объем трафика, использование памяти, количество экземпляров и количество ошибок. Это полезно в качестве отправной точки при исследовании проблемы и когда вы хотите получить образ общего состояния приложения.
Ниже приведен пример с объемом запросов приложения:

Трассировка
Поскольку экземпляр App Engine является черным ящиком, вы не можете использовать другие инструменты для диагностики его производительности. Если консоли ведения журнала недостаточно, страница трассировки предоставляет более подробные данные. Это позволяет искать распределение задержек по определенным запросам.
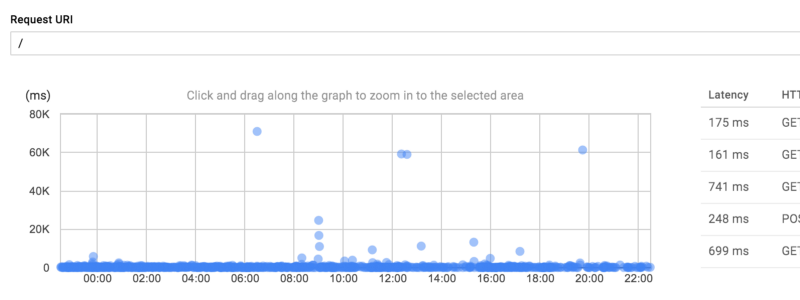
При выборе конкретного запроса открывается временная шкала. Она отображает удаленные вызовы процедур (RPC), которые не видно в журналах. Сводка для каждого RPC по типу находится сбоку. При нажатии на RPC появляется более подробная информация (например, размер ответа).
Это может быть очень полезно, когда вы хотите найти причину медленного запроса. В следующем примере можно увидеть, что запрос вызывает несколько быстрых вызовов Memcache и очень медленную операцию записи Datastore.
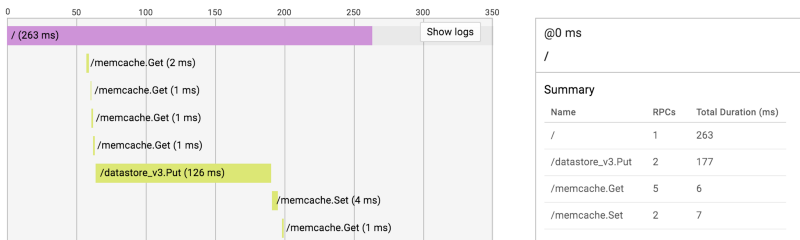
Единственная проблема в том, что RPC не содержат достаточной информации, чтобы выяснить, что именно произошло. Подробный вид операции Datastore выглядит следующим образом:
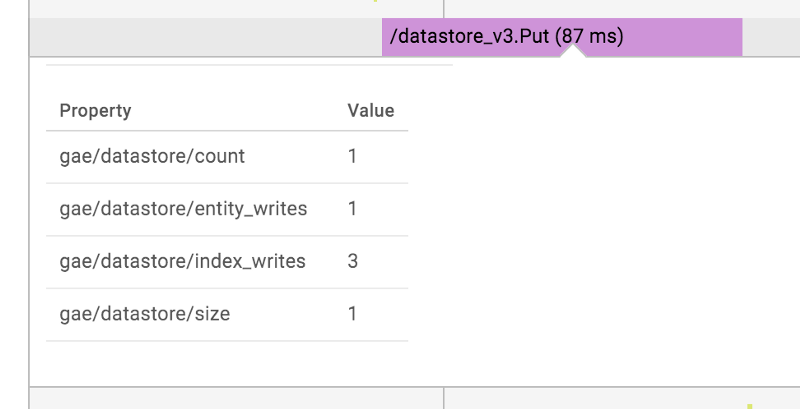
Вид не включает имя обновленного объекта. Это может сделать весь экран практически бесполезным. Чтобы получить более подробную информацию из контекста, нужно нажать кнопку «показать журналы» в правом верхнем углу.
Ресурсы
Важно также отметить, что цены полностью основаны на использовании. Это означает, что стоимость приложения масштабируется практически байт за байтом, час за часом и операция за операцией. Отсутствие фиксированной стоимости удобно для начала: если ваше приложение никто не использует — есть квота, вы ничего не платите.
Самый большой пункт в счёте, безусловно, будет для инстансов, которые я использовал в моем последнем проекте. Следующий большой кусок, скорее всего, стоимость чтения / записи Datastore, 15% от общей стоимости.
В Google Cloud Console есть приятный интерфейс для отслеживания всех квот:
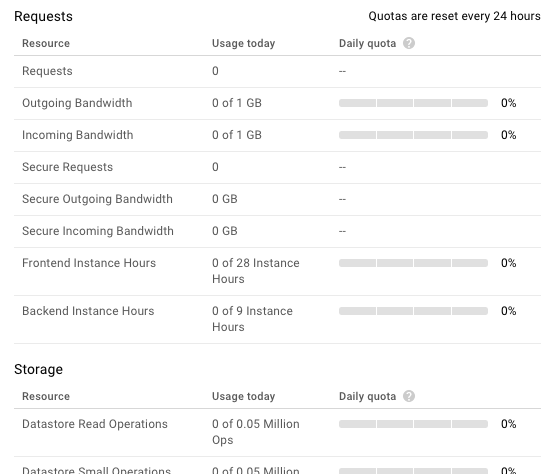
Чтобы быть более конкретным, уточню: говоря «все квоты», я имею в виду все квоты, о которых говорит Google. У нас действительно была проблема, когда мы попали в невидимую квоту. Думаю, в то время API, возможно, был в Beta-версии. В любом случае одна часть нашего приложения перестала работать, и мы понятия не имели, почему. К счастью, мы были подписаны на поддержку Google Cloud. Они сообщили об указанной квоте, и нам пришлось переписать часть приложения, чтобы оно снова работало.
У нас также был небольшой перерыв в связи с запутанной ценовой настройкой. В какой-то момент одно из наших приложений внезапно перестало работать и ответило на страницу ошибкой по умолчанию. Потребовалось десять минут, чтобы понять, что мы достигли установленного бюджета. После того как мы подняли бюджет, все снова заработало.
Поддержка
О поддержке Google Cloud можно сказать многое. Во-первых, без поддержки у нас были бы серьезные неприятности, поэтому она обязательна для любого важного приложения. Например, примерно раз в год наше приложение прекращает подавать запросы. После обращения в службу поддержки Google мы узнали, что наше приложение перемещено в «другой кластер». Оно снова заработало. Это очень страшная ситуация. Вы не можете ничего сделать, кроме как «молиться богам Google».
Во-вторых, качество поддержки менялось. Иногда мы писали десятки сообщений, а любую поддержку это бесит. Но в конце концов наш вопрос решался или мы получали достаточно информации, чтобы решить его самостоятельно.
Новый век
Google работает над новым типом App Engine — гибкой средой. В настоящее время он находится в Beta. Цель Google — предложить лучшее: легкость и комфорт работы на App Engine в сочетании с гибкостью и мощью Google Compute Engine. Это позволит использовать любую платформу программирования (например, Java 9!) на любой из вычислительных машин Google Compute Engine (например, 416 ГБ оперативной памяти!), позволяя Google заботиться о поддержке серверов и обеспечивать бесперебойную работу приложения.
Google работаeт над этим уже несколько лет. Естественно, нам интересно. До сих пор мы не были так взволнованы.
Дизайн шкалы
Теперь вы можете посмотреть ограничения, которые App Engine накладывает на ваше приложение. Потерпите меня еще немного. Google App Engine создан Google. Эти ребята знают, как создавать масштабируемые системы. Ограничения — необходимость. Они заставляют вас адаптировать приложение под облако. Мы должны принимать это. Если вы сражаетесь с App Engine, вы боретесь с «новыми» правилами облака. Этот урок я усвоил за три года работы в Google App Engine.
Однако некоторые ограничения являются результатом пренебрежения со стороны Google. Кажется, они делают минимальные инвестиции. На самом деле у меня было это чувство в течение последних двух лет. Работать с устаревшим техническим стеком, не надеясь на улучшения, сложно. Бесит, если известные проблемы не исправляются. Удручает получать так мало информации о том, куда направляется платформа. Вы чувствуете себя в ловушке.
В целом мне понравилось, как App Engine позволил команде разработчиков сосредоточиться на создании приложения, делая пользователей счастливыми и зарабатывая деньги. Google много хлопотал. Но «старый» App Engine на подходе. Я не думаю, что начинать на нем новые проекты — хорошая идея. С другой стороны, если гибкая среда App Engine Flexible сможет исправить основные проблемы своего предшественника, она может стать очень перспективной платформой для разработки приложений.