Все чаще и чаще современный разработчик сталкивается с необходимостью поддержки разных языков в рамках одного проекта. Говоря о разных языках мы здесь имеем ввиду любой язык, в алфавите которого присутствуют символы , отличные от латинских. Латинский язык мы не считаем за отдельный язык, ибо символы этого алфавита, как правило, присутствуют всегда и нормально поддерживаются на уровне баз данных. В этом материале мы будем говорить о по-настоящему многоязычных приложениях, в которых, наряду с латинскими символами, могут присутствовать, скажем, русские, китайские и так далее буквы.
Организация подобных приложений сложна, потомучто она влечет за собой множество проблем и вопросов, которые разработчику приходится решать. Неправильное проектирование такого приложения ведет к тому, что добавление нового языка в проект сопровождается изменением таблиц, редактированием скриптов и другими всевозможными подводными камнями. В результате таких переработок проект может начать работать нестабильно или вообще перестать работать, такие переделки могут потребовать значительных временных и рабочих ресурсов. В общем, в этом материале мы поговорим с вами о том, как же упростить себе жизнь на этапе проектирования и по максимуму облегчить процессы, описанные выше.
GetText – описание возможностей
В преодолении вышеуказанных препятствий, система GetText предлагает нам помощь в следующем:
- освобождает наши скрипты от языкозависимых данных, точнее нам не надо будет заботиться о том, с каким языком будут работать наши скрипты;
- предлагает набор утилит для работы с языковыми данными;
- а также, разработки сторонних авторов позволяют в значительной степени облегчить труд переводчиков и стандартизировать данные;
- и, очень важная особенность, если вы по каким-то причинам не перевели те или иные строки, скажем, на китайский, то GetText вернем вам их на языке поумолчанию (обычно английский), что очень удобно, так как освобождает нас от полного перевода всех текстов.
Все эти возможности в свое время привлекли мое внимание и теперь разработка моих скриптов в значительной степени стала более эффективной. Возможности этой утилиты при командной разработке или при значительном разделении труда при производстве приложений вообще трудно переоценить.
От описательной части, перейдем к делу.
Найтройка GetText
Прежде чем перейти к процессу освоения новой технологии, давайте произведем установку нужного софта, или проверим наличие оного.
Поскольку в основном (по моему опыту) разработка ведется на основе Windows систем, то в рамках данной статьи я буду говорить именно о работе в Windows. В Linux системах как правило указанных действий вообще производить не надо, так как все нужные утилиты там устанавливаются поумолчанию.
Для получения нужных нам файлов идем сюда: http://sourceforge.net/projects/gettext. На этой странице вы найдете два пакета программ: gettext-win32 и libiconv-win32. Первый – это собственно файлы GetText, второй – это утилита для работы с текстом в разных кодировках, которая таже требуется для нормальной работы GetText. Вам необходимо скачать файлы: gettext-runtime-0.13.1.bin.woe32.zip (это уже скомпилированные под Windows файлы GetText) и gettext-tools-0.13.1.bin.woe32.zip (это скомпилированные вспомогательные утилиты), а также libiconv-1.9.1.bin.woe32.zip (это скомпилированные файлы iconv).
Для дальнейшей установки нам понадобятся файлы: gettext-runtime-0.13.1.bin.woe32.zip и libiconv-1.9.1.bin.woe32.zip.
Скопируйте файлы intl.dll, gettext.exe, asprintf.dll, envsubst.exe, ngettext.exe из первого пакета в папку SYSTEM32 вашей Windows, затем тоже самое проделайте с файлами charset.dll, iconv.dll, iconv.exe из второго пакета.
Теперь перейдите в папку dlls вашей инсталляции PHP и скопируйте из нее файл libintl-1.dll в туже папку, что и предыдущие файлы.
Далее, найдите php.ini (как правило он находится в папке установки PHP или в папке WINDOWS вашей системы). Раскомментируйте в нем 2 строки: extension=php_gettext.dll (чтобы включить поддержку GetText) и extension=php_iconv.dll (чтобы включить поддержку iconv). Теперь перезапустите ваш сервер (например, Apache) и посмотрите phpinfo();. PHP сообщит вам, что GetText и iconv расширения подключены и включены (enabled).
У нас остался еще один пакет: gettext-tools-0.13.1.bin.woe32.zip. Создайте на своем диске отдельную папку и распакуйте эти утилиты туда.
Поскольку мы с вами говорим о профессиональной работе, то нам понадобится бесплатный редактор poedit (http://www.poedit.org/). Установите его, он нам понадобится в дальнейшем.
И так, когда все действующие лица собраны воедино, давайте посмотрим, как же это работает.
взгляд изнутри
Как правило, наши с вами скрипты в той или иной форме выводят данные. Данные эти можно разделить на несколько типов. Нас в данном случае интересуют статические тексты, которые “зашиты” внутри наших скриптов. Это, например, сообщения об ошибках, какие-то другие вспомогательные данные. Наша задача с вами избавиться от необходимости редактирования скриптов (здесь не имеется ввиду доработка скриптов или исправление ошибок).
Для начала, нам необходимо проделать с нашими скриптами несложные изменения, эти изменения вносятся 1 раз и более никогда. В дальнейшем нам просто надо будет сразу придерживаться определенных правил.
В качестве отступления, я приведу некоторые рассуждения. Часто начинающие, и даже не очень, программисты в своих скриптах пишут сообщения на русском языке. Впреть, я советую вам избавляться от такого подхода и писать сообщения латиницей. Причин здесь несколько: во-первых, при использовании нелатиницы возникает вопрос о кодировке, в которой сообщения содержатся в ваших скриптах, что вызывает дополнительные неудобства для пользователей, которые не говорят по-русски или не совсем разбираются в обилии кодировок, во-вторых, это привносит сложность, когда вам внезапно придется изменить кодировку своего приложения – здесь могут полезть разные нестыковки (один скрипт в одной кодировке, другой – в другой), такой подход вызовет много дополнительных действий. Вы плохо знаете английский? Ничего страшного – пишите мета-тэги, переводчик в последующем сможет подправить любую вашу неправильную фразу, не правя для этого скрипты.
И так, вернемся к тому, что же необходимо проделать с нашими скриптами.
Как правило, в скриптах строки используются следующим образом:
echo 'string';
print ('string');
$label = 'string';
return 'string';и т.д.
Установленное выше расширение PHP добавляет в наш арсенал несколько команд, при помощи которых мы можем преобразовать примеры выше следующим образом:
echo _('string');
print (_('string'));
$label = _('string');
return _('string');или
echo gettext('string');
print (gettext('string'));
$label = gettext('string');
return gettext('string');Эти примеры полностью идентичны. Советую использовать первый способ, так как он более экономичный в плане записи и, на мой взгляд, более наглядный, так как не вносит в структуру скрипта значительного “мусора”.
И так, наши скрипты переделаны указанным способом и мы переходим к следующему этапу.
утилита XGetText
Изменить скрипты – это только половина работы. Что же делать дальше? А дальше нам необходимо создать 2 файла, которые будут содержать в себе все, “обернутые” указанной выше конструкцией, строки. В первом файле они будут содержаться в виде текста, а второй файл – это скомпилированная версия первого.
Для начала нам необходимо извлечь все строки из наших скриптов. Поможет нам в этом утилита xgettext.exe из пакета утилит.
В упрощенном виде, вам необходимо запустить ее следующим образом:
xgettext my_cript.phpВ результате вы получите первый файл: messages.po.
Давайте рассмотрим другие команды этой утилиты:
—files-from=FILE – вы можете составить перечень всех своих скриптов создав отдельный файл, где каждая строка – это название файла. Тогда за один проход утилита может обработать сразу все ваши скрипты. В результате работы вы получите ЕДИНЫЙ .po файл.
—directory=DIRECTORY – добавить директорию в список для поиска скриптов.
—default-domain=NAME – NAME определяет название .po файла (NAME.po).
—output=FILE – перенаправляет вывод данных в указанный (FILE) файл.
—output-dir=DIR – выходящие файл будут созданы в каталоге DIR.
—language=NAME – NAME указывает на каком языке программирования вы написали свои скрипты, в данном случае PHP.
—join-existing – если у вас уже есть .po файл, то вы можете добавлять к нему строковые данные при помощи этой команды не создавая нового файла.
—exclude-file=FILE.po – если в новых скриптах есть строки, которые уже есть в вашем .po файле, вы можете пропустить такие строки при помощи этой команды.
—extract-all – эта команда заставит утилиту извлекать все строки подряд без определения языка программирования. Использование этой опции не рекомендуется – вы получите слишком “мусорный” .po файл.
—keyword[=WORD] – вы можете задать список так называемых стоп слов, которые будут пропущены утилитой.
Остальные опции вспомогательные и вы можете разобраться с ними сами, запустив xgettext —help для вывода англоязычной подсказки.
И так, файл создан, что дальше?
Описание .PO файла
Полученный в результате предыдущих действий файл – это текстовый файл, содержащий в себе все строки, нуждающиеся в переводе.
Далее я приведу пример такого файла:
# SOME DESCRIPTIVE TITLE.
# Copyright (C) YEAR Free Software Foundation, Inc.
# FIRST AUTHOR , YEAR.
#
#, fuzzy
msgid ""
msgstr ""
"Project-Id-Version: PACKAGE VERSION
"
"POT-Creation-Date: 2000-12-08 19:15-0300
"
"PO-Revision-Date: YEAR-MO-DA HO:MI+ZONE
"
"Last-Translator: FULL NAME
"
"Language-Team: LANGUAGE
"
"MIME-Version: 1.0
"
"Content-Type: text/plain; charset=CHARSET
"
"Content-Transfer-Encoding: ENCODING
"
#: prueba.php:12
msgid "Hello world"
msgstr ""
#: prueba.php:12 prueba.php:13
msgid "
"
msgstr ""
#: prueba.php:13
msgid "This is a test"
msgstr "" По сути, это и есть файл, который вы должны отдать переводчику. Переводчик должен задать значение следующим строкам:
#: prueba.php:13
msgid "This is a test" // это оригинальная фраза
msgstr "" // здесь будет переведенная фразаТут многие из вас, наверное, почешут голову и скажут, что все это полный отстой. Советую дочитать материал до конца и вы поймете, что все вовсе не так плохо, потому что далее мы также рассмотрим заявленную нами в названии статьи “профессиональную” работу.
Далее, давайте рассмотрим структуру заголовка файла (только самые важные):
# Copyright (C) YEAR Free Software Foundation, Inc.
# FIRST AUTHOR , YEAR. Укажите здесь свои авторские копирайты.
"Project-Id-Version: PACKAGE VERSION
" Версия проекта и его название.
"Last-Translator: FULL NAME
" Укажите здесь имя и емаил адрес переводчика.
"Language-Team: LANGUAGE
" Название языка (например, Russian).
"Content-Type: text/plain; charset=CHARSET
" Кодировка, в которой сделан перевод (например, UTF-8). Рекомендую вам всегда делать переводы в Unicode кодировке UTF-8. Это избавит вас от многих проблем, а данные от GetText вы всегда сможете получить в той кодировке, в которой вам необходимо.
Ну вот, все заголовки заполнены, а сообщения переведены – двигаемся дальше.
утилита MsgFmt
GetText не может работать с .po файлом. Чтобы информация из него стала доступной, его надо скомпилировать. Этим занимается заявленная в названии утилита. В результате ее работы у вас появится второй файл с расширением .mo.
Msgfmt file.po file.moВот, собственно, и все.
структура каталогов
Для удобства, создайте в корне своего приложения папку locale. Внутри этой директории необходимо создать папки для каждого из поддерживаемых языков: ru/, en/ и так далее. Внутри них необходимо создать папку LC_MESSAGES, а в эту папку, в свою очередь, необходимо поместить созданные нами .moфайлы для каждого языка (.po файлы можете поместить туда же, это не помешает).
Давайте посмотрим, как будет выглядеть дерево папок в финальном виде:
/src
/locale/en/LC_MESSAGES/messages.mo
messages.po
ru/LC_MESSAGES/messages.po
messages.moДля правильного нахождения двухбуквенного сочетания для каждого языка воспользуйтесь этой таблицей: http://www.loc.gov/standards/iso639-2/langcodes.html, или документацией по GetText.
В предыдущих нескольких главах мы с вами познакомились с технологией работы GetText. Настало время рассмотреть варианты “Профессиональной работы”.
профессиональная работа
Все описанные выше шаги необходимы для понимания как все это работает и что за чем следует. Но, как вы понимаете, это все очень сложно и не всегда доступно. Например, врядли вы толково сможете объяснить все это переводчику, а уж тем более просить его переводить какой-то файл непонятного формата – это задача не из легких.
На этом этапе мы с вами воспользуемся замечательным бесплатным редакторов poedit, который вы уже скачали и установили себе в одной из первых глав нашего повествования. С запуском этого редактора мы переходим к профессиональной части.
Poedit поддерживает множество языков интерфейса, в том числе и русский.
При первом запуске выберите язык интерфейса (поддерживается русский). А также редактор попросит ввести ваше имя и емаил. Другие установки оставьте поумолчанию. Во вкладке “Парсеры” удалите все, кроме PHP.
И так – начинаем работать. Во вкладке “Файлы” выбираем “Новый каталог”.
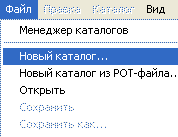
Далее заполняем появившуюся форму.
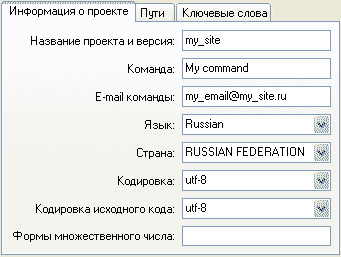
В следующей вкладке задайте путь (пути), где находятся скрипты вашего проекта.
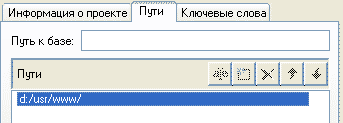
Теперь жмем “ОК”. Редактор начнет рекурсивно обрабатывать все найденные в указанной папке и ее подпапках скрипты на предмет наличия в них “обернутых” строк.
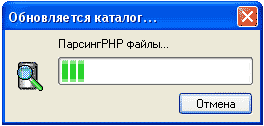
По окончании работы, редактор создаст .po файл и предложит сохранить его на диск. Это файл-проект, который содержит в себе все сообщения, которые нуждаются в переводе для всего вашего проекта (или тех скриптов, которые редактор нашел по указанному вами пути).
Перед вами появится меню, в котором содержится перечень всех новых строк, которые нуждаются в переводе, а во второй вкладке будут показаны те строки, которые исчезли (удалены за ненадобностью) из ваших скриптов. После нажатия “ОК”, .po файл будет обновлен – новые строки добавятся, старые удалятся.
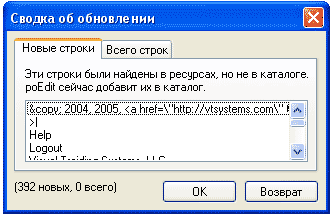
Редактор сам попробует подобрать перевод к новым строкам из уже имеющихся переведенных строк. Строки, к которым перевод удалось подобрать (обращаю ваше внимание, что редактор делает это по странному алгоритму и вам не стоит на него надеяться), будут выделены коричневым цветом. Строки, к которым перевод не подобран и которые нуждаются в переводе будут сине-зелеными, белые строки – это нормально переведенные строки.
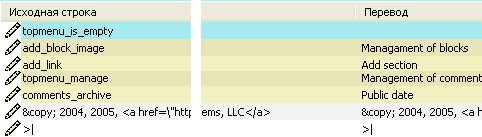
И так, теперь, если передать редактор вместе с .po файлом переводчику, то ему будет очень легко и понятно переводить указанный файл. Редактор поддерживает все языки (в том числе и китайские иероглифы). Давайте рассмотрим все элементы редактора.
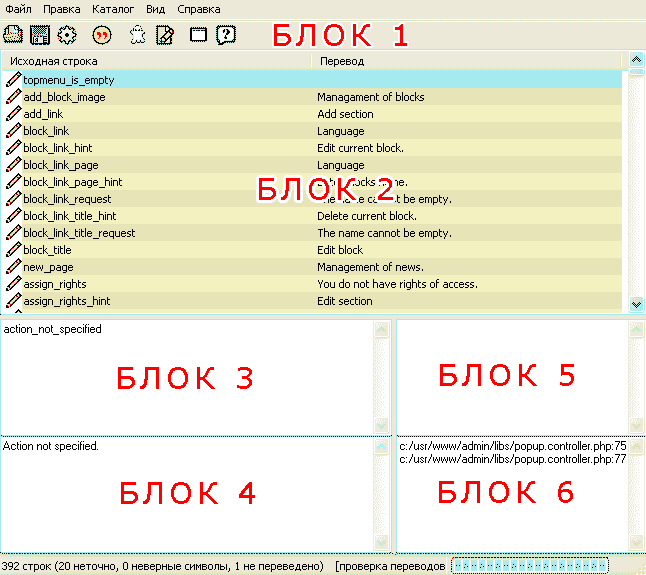
БЛОК 1 – это блок вспомогательного меню, куда вынесены некоторые нужные функции. Первые 2 иконки понятны, о третьей я расскажу ниже. Четвертая иконка включает показ кавычек в окнах оригинала (БЛОК 3) и перевода (БЛОК 4). Пятая иконка — если нажата, то это означает что для строки был подобран перевод самим редактором и этот перевод не точен. Следующая иконка вызывает окно редактирования комментария (БЛОК 6). В поле комментария вы можете дать пояснение переводчику к любой, требующей перевода, строке. Следующая иконка убирает заголовок окна, растягивая область экрана на весь декстоп. Последняя иконка – вызов справки. БЛОК 5 – блок автоматических комментариев. БЛОК 2 – это перечень всех переведенных и непереведенных строк. Нажмите на любую строку, чтобы произвести перевод или отредактировать его.
Как видите, процесс перевода очень прост и вот уже скоро (буквально после нажатия кнопки сохранить) редактор создаст для вас автоматически файл .mo.
У редактора есть еще одна крайне полезная функция. Которая прячется за неописанной ранее иконкой  . она нам понадобится, когда в наш проект внесены изменения: какие-то скрипты удалены или значительно дополнены или просто внесены в них изменения.
. она нам понадобится, когда в наш проект внесены изменения: какие-то скрипты удалены или значительно дополнены или просто внесены в них изменения.
После нажатия этой иконки редактор полностью пересканирует указанный при создании проекта каталог и выявит все новые не переведенные строки в ваших скриптах, а также найдет все удаленные из скриптов строки. Обращаю ваше внимание, что если вы используете в своем проекте шаблонизатор Smarty, то вам необходимо очистить папки со скомпилированными шаблонами, так как редактор не может корректно обработать имена файлов этих шаблонов.
Таким образом, вы получаете мощный инструмент для автоматизированного перевода ваших приложений на разные языки, а также удобный инструмент для переводчика.
Теперь мы с вами переходим к финальной части нашего рассказа – а именно к тому, как же всетаки .mo файл заставляет наши скрипты говорить на разных языках.
Do you speak по-русски?
Наконец все нужные файлы созданы и переведены, и вы с чистым сердцем можете заставить ваше приложение бодро откликнуться на нужном вам языке. Давайте посмотрим, как это работает.
В конфигурационный файл или в самом начале вашего индексного файла необходимо добавить следующие строки.
// Задаем текущий язык проекта
putenv("LANG=ru_RU");
// Задаем текущую локаль (кодировку)
setlocale (LC_ALL,"Russian");
// Указываем имя домена
$domain = 'my_site';
// Задаем каталог домена, где содержатся переводы
bindtextdomain ($domain, "./locale");
// Выбираем домен для работы
textdomain ($domain);
// Если необходимо, принудительно указываем кодировку
// (эта строка не обязательна, она нужна,
// если вы хотите выводить текст в отличной
// от текущей локали кодировке).
bind_textdomain_codeset($domain, 'UTF-8');Пройдемся по порядку.
// Задать русский язык текущим
putenv ("LC_ALL=ru_RU");Эта строка включает нужную пользователю кодировку. В данном случае русскую. А вот таким образом включаем английскую:
// Задать английский язык текущим
putenv ("LC_ALL=en_US");Теперь нам необходимо настроить локаль, в которой работаем. Для русской локали это выглядит так:
// Задать русскую кодировку Windows-1251 (если у вас Windows)
// или KOI-8 (если у вас Linux)
setlocale (LC_ALL, "ru_RU");Для английской – так:
// Задать анлийскую кодировку Windows-1252 (если у вас Windows)
setlocale (LC_ALL, "en_US");Все сообщение теперь будут выводиться в кодировке, соответствующей выбранной вами локали. Если это вас по каким-то причинам не устраивает, можно указать кодировку принудительно. Вот такая команда включит принудительно Unicode (UTF-8).
bind_textdomain_codeset($domain, 'UTF-8');Переменная $domain в данном случае указывает домен (или имя файла .mo) нашего проекта. Все файлы .mo должны называться так: $domain.mo.
Далее указываем корневую папку, где у нас содержатся все переводы (.mo файлы для всех языков).
$domain = 'my_site';
bindtextdomain ($domain, "./locale");Как вы понимаете, доменов может быть несколько. Это необходимо, например, если ваше приложение состоит из нескольких самостоятельных частей. У каждой части моет быть свой языковой файл.
Теперь необходимо подключить (выбрать) заданный выше домен:
textdomain ($domain);Все – наше приложение “выучило” язык, заданный вами в настройках!
И вот уже привычное echo _(‘Hellow world’); будет сиять на вашем экране как “Привет мир” или на любом другом языке мира!
Итог
В рамках данного материала мы с вами подробно познакомились с замечательной технологией GNU GetText. Рассмотрели принципы функционирования и организации многоязычных приложений. Рассмотрели возможности оптимизации работы программистов и переводчиков, а также заложили основы профессионального использования в своих приложениях предлагаемых технологий.