Начало соревнованию было положено еще в прошлом году. Тогда мы знали, что HighLoad Cup — это именно тот чемпионат, которого не хватало в ряде проектов Mail.Ru Group. В первом пилотном соревновании участвовало 449 человек. Было много кода и много пота как у самих организаторов, так и участников (8789 различных решений). Были нюансы в технической реализации, но главное, что всем понравилось! Организаторы провели множество ночей в датацентре, несколько выходных — в офисе. Готовы к этому снова! В конце статьи вы найдете полезные материалы от нас и от участников, которые помогут вам разобраться в механике и найти какие-то best practice-решения.
На этот раз постарались подготовить для вас дельце посложнее. Кроме того, мы расширили аудиторию, теперь в соревновании могут принять участие и англоязычные пользователи. Присоединяйтесь к русскоязычному сообществу в Telegram. Там вы получите множество инсайтов по соревнованию ?
Итак, добро пожаловать на борт!
Механика
По сравнению с прошлым годом ничего концептуально в соревновании не изменилось.
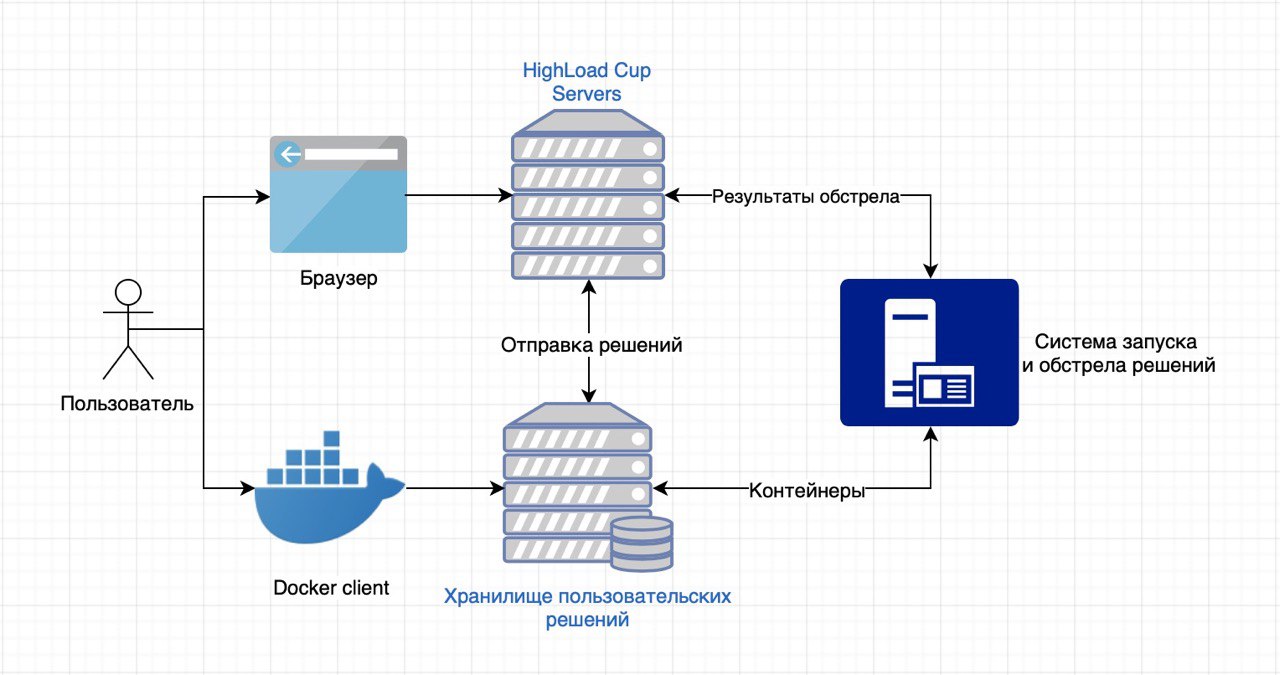
Участникам дается задача на создание небольшого web-сервиса, работающего с данными определенной структуры и реализующего API к этим данным. Контейнер (Docker) с реализованным сервисом загружается к нам на серверы, там мы его запускаем и начинаем обстреливать HTTP-запросами.
Решения отправляются нам с помощью локально установленного Docker-клиента в специальное хранилище (у каждого оно свое собственное). Затем отправленный нам сервис автоматически проверяется системой CodeHub-CodeRunner, разработанной сотрудниками Лаборатории Технопарка Mail.Ru Group.
Затем мы начинаем «молотить» контейнер на тестовой машине с процессором Intel Core i7. Решению будут выделены 4 ядра по 2,4 ГГц, 2 Гб оперативной памяти и 10 Гб на жёстком диске. Если коротко, то запускается «танк» с движком phantom, который ведет обстрел в несколько потоков с линейно растущим профилем нагрузки. Перед началом обстрела у пользовательского решения есть несколько минут (точное количество зависит от задачи), чтобы обработать данные из полученного JSON-файла. Корректная работа с этими данными — необходимое условие победы. Обстрела всего два, короткий и длинный.
По результатам таких обстрелов мы подсчитываем количество правильных и неправильных ответов, RPS и скорость ответа, и по определенной метрике формируем рейтинговую таблицу. Автор самого быстрого и отказоустойчивого сервиса станет победителем.
Используйте любые веб-технологии, которые сможете найти или придумать. Выберите свой собственный язык программирования и фреймворк. Это может быть C++, Java + Tomcat, Python + Django, Ruby + RoR, GoLang, JavaScript + NodeJs, Haskell, хоть Assembler или что-то еще, на ваше усмотрение. Для хранения данных: MySQL, PostgreSQL, Redis, MongoDB, кэши. Полная свобода!
В результате обстрела получаются логи и метрики, которые затем будут показаны участникам в виде графиков на странице решения. Отдельно отслеживаются:
- основные метрики;
- корректность ответа;
- быстрота ответа на запрос;
- количество ответов в секунду.
Рейтинг решения рассчитывается так: берем время всех верных ответов, которые успел дать API во время обстрела, прибавляем штрафное время за каждый неправильный ответ или запрос, ответ на который мы не смогли получить (штрафное время всегда равно общему таймауту запроса). Участник, суммарное время которого окажется меньше прочих, оказывается выше в лидерборде и имеет шанс стать победителем чемпионата.
Задача
Наша команда долго думала, какую задачу дать в этом году. Хотели что-то такое, что уравняет шансы большинства (чтобы не побеждали одни самописные велосипеды на C/C++).
Формулировка такая:
В альтернативной реальности человечество решило создать и запустить глобальную систему поиска «вторых половинок». Она призвана уменьшить количество одиноких людей в мире и способствовать созданию крепких семей.
Как в тестовых, так и в «боевых» данных для различных обстрелов имеются записи об одной сущности: Account. Она описывает всю известную информацию о пользователе — его имя, контакты, интересы, выявленные симпатии к другим пользователям. Гарантируется корректность предоставляемых данных в соответствии с указанными далее типами и ограничениями. Все данные были сгенерированы и придуманы нами по определенным законам.
В одной записи Account (Профиль) имеются следующие личные данные:
- id — уникальный внешний идентификатор пользователя. Устанавливается тестирующей системой и затем используется для проверки ответов сервера. Тип — 32-разрядное целое число.
- email — адрес электронной почты пользователя. Тип — unicode-строка длиной до 100 символов. Гарантируется уникальность.
- fname и sname — имя и фамилия соответственно. Тип — unicode-строки длиной до 50 символов. Поля опциональны и могут отсутствовать в конкретной записи.
- phone — номер мобильного телефона. Тип — unicode-строка длиной до 16 символов. Поле является опциональным, но для указанных значений гарантируется уникальность. Заполняется довольно редко.
- sex — unicode-строка, «m» означает мужской пол, а «f» — женский.
- birth — дата рождения, записанная как количество секунд от начала UNIX-эпохи по UTC (другими словами, это timestamp). Ограничено снизу 01.01.1950, сверху 01.01.2005.
- country — страна проживания. Тип — unicode-строка длиной до 50 символов. Поле опционально.
- city — город проживания. Тип — unicode-строка длиной до 50 символов. Поле опционально и указывается редко. Каждый город расположен в определённой стране.
Также в одной записи Account есть поля, специфичные для системы поиска «второй половинки»:
- joined — дата регистрации в системе. Тип — timestamp с ограничениями: снизу 01.01.2011, сверху 01.01.2018.
- status — текущий статус пользователя в системе. Тип — одна строка из следующих вариантов: «свободны», «заняты», «всё сложно». Не обращайте внимание на странные окончания ?
- interests — интересы пользователя в обычной жизни. Тип — массив unicode-строк, возможно, пустой. Строки не превышают по длине 100 символов.
- premium — начало и конец премиального периода в системе (когда пользователям очень хотелось найти «вторую половинку» и они оплачивали услугу). В JSON это поле представлено вложенным объектом с полями start и finish, где записаны timestamp-ы с нижней границей 01.01.2018.
- likes — массив известных симпатий пользователя, возможно, пустой. Все симпатии идут вразнобой и каждая представляет собой объект из следующих полей:
- id — идентификатор другого аккаунта, к которому пользователь питает симпатию. Аккаунт всегда можно найти в исходных данных по id. Обратите внимание, что в данных может быть несколько лайков с одним и тем же id.
- ts — время, то есть timestamp, когда симпатия была записана в систему.
Нужно реализовать API.
- Получение списка пользователей: /accounts/filter/
Этот метод API планируется использовать для поиска пользователей по заранее известным или желаемым полям. К примеру, кому-то захотелось посмотреть всех людей определенного возраста и пола, живущих в определённом городе.
- Разбиение пользователей по группам: /accounts/group/
Этот метод API планируется использовать для создания отчётов о работе системы. Поля, по которым производится группировка, переданы в GET-параметре keys через запятую. Они не так многочисленны, как в запросе на фильтрацию пользователей. Полей для группировки всего пять — sex, status, interests, country, city.
- Рекомендации по совместимости: /accоunts/id/recommend/
Этот запрос используется для поиска «второй половинки» по указанным пользовательским данным. В запросе передаётся id пользователя, для которого ищутся те, кто лучше всего подходят по статусу, возрасту и интересам. Решение должно проверять совместимость только с противоположным полом (мы не против секс-меньшинств и осуждаем дискриминацию, просто так получилось ? ). Если в GET-запросе передана страна или город с ключами country и city соответственно, то нужно искать только среди живущих в указанном месте.
- Подбор по похожим симпатиям: /accоunts/id/suggest/
Этот тип запросов похож на предыдущий тем, что он тоже про поиск «вторых половинок». Тоже пересылается id пользователя, для которого мы ищем вторую половинку, используется GET-параметр limit. Различия в реализации: мы ищем, кого лайкают пользователи того же пола с похожими «симпатиями» и предлагаем тех, кого они недавно лайкали сами. Если в запросе передан GET-параметр country или city, то искать «похожие симпатии» нужно только в определённой локации.
Рассказать всё в одной статье не представляется возможным. Подробные правила будут опубликованы в день старта (уже сегодня) на сайте чемпионата и в репозитории GitHub, но уже сейчас вы знаете, что вас ждёт.
Расписание
Да, мы знаем, что праздники (с наступающим), поэтому чемпионат будет очень длинным ?
- Бета-тестирование (результаты не учитываются): старт 13 декабря в 19:00, конец 21 декабря в 19:00.
- Отборочный раунд: с 21 декабря 19:00 до 31 января 19:00.
- Финальный раунд: до 5 февраля.
В течение бета-тестирования правила и условия задачи могут меняться (при наличии багов и по другим причинам).
Отборочный раунд — правила не меняются.
Финальный раунд проходит полностью автоматически, но перед ним финалисты (N пользователей, прошедших по результатам отборочного раунда и не менее 50 человек) выбирают решение, которое будет обстреляно в несколько волн. Итог формируется по лучшему результату за все волны.
Подарочки
Первое место — новенький MacBook Air.
Второе и третье место — Apple iPad.
Четвертое, пятое и шестое места — Samsung Gear S3.
Участник имеет право попросить взамен другой подарок эквивалентной стоимости. Все участники, прошедшие в финал, получат фирменные футболки нашего чемпионата.