Использовать микросервисную архитектуру или нет? Разбираемся с плюсами и минусами, внутренней коммуникацией, принципами и заблуждениями.
Виды архитектуры
Простейший и популярный вариант архитектуры – монолитная. Каждый начинал с неё, и здесь нет никакой изоляции и распределённости: один монолит обрабатывает все запросы.
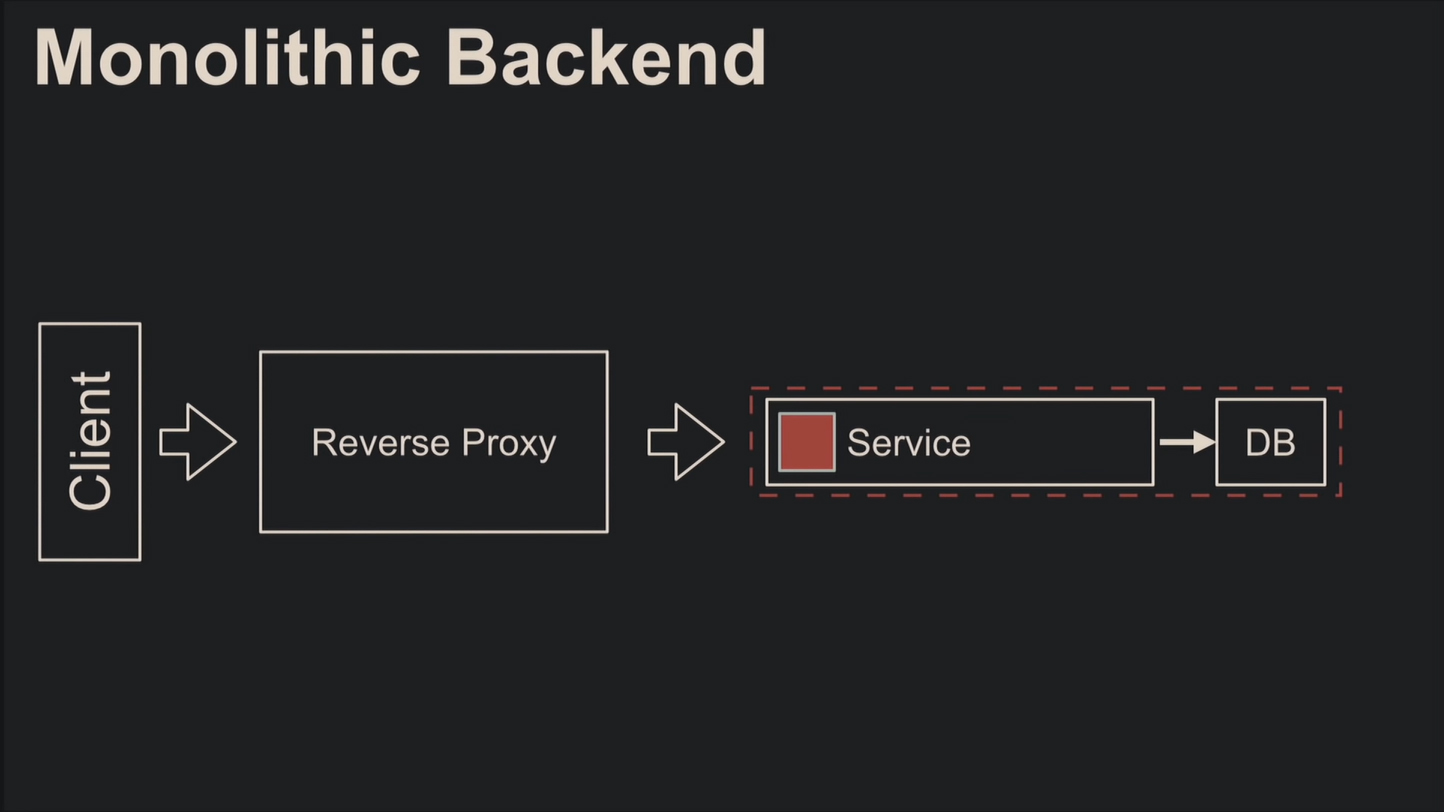
Отчего возникают следующие проблемы:
- отказоустойчивость;
- горизонтальное масштабирование;
- применение одной технологии или языка и невыгодность переписывать огромный монолит;
- сложность рефакторинга из-за хранения кода в одном месте и куча legacy;
- трудности работы в команде разработчиков;
- чтобы использовать повторно, придётся дробить.
Второй по популярности вид архитектуры – пара монолитов, микс из монолита и сервисов или даже микросервисов. То есть вы сохраняете монолит, а доработки выполняете с использованием современных технологий.
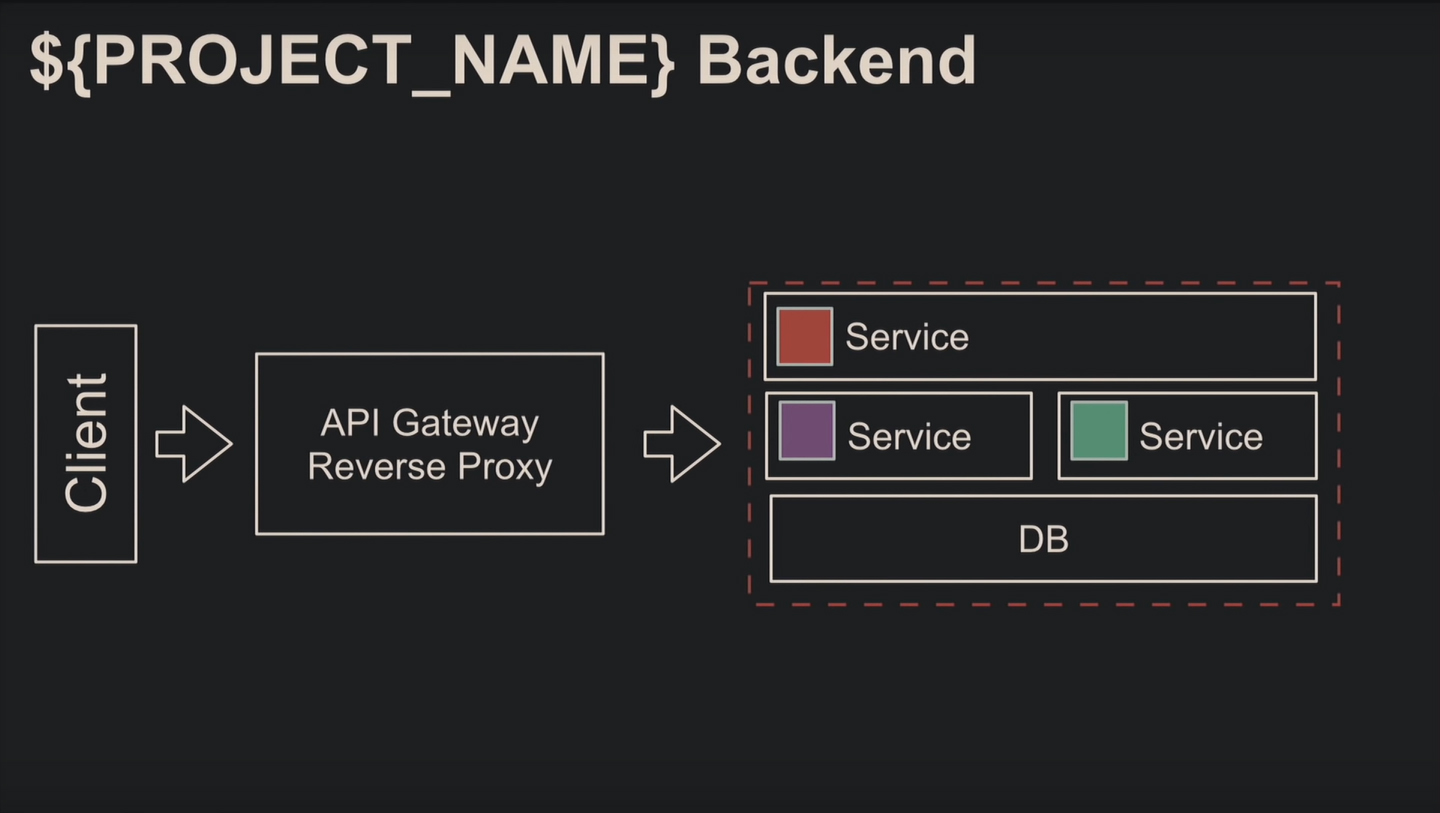
Это частично решает проблемы отказоустойчивости, масштабируемости и одного стека технологий.
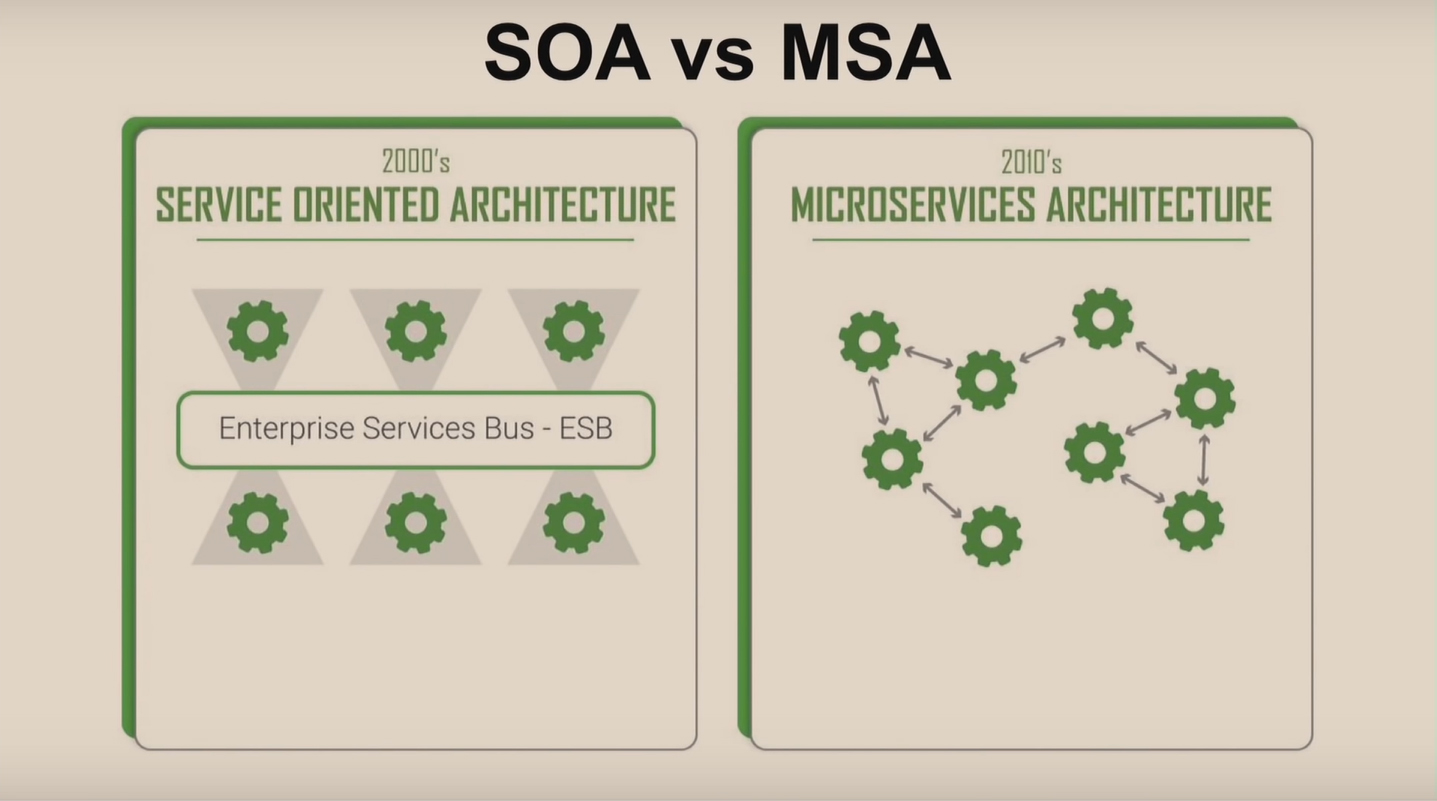
Микросервисная архитектура – не новая идея, а разновидность сервис-ориентированной архитектуры. Сервис-ориентированная архитектура предусматривает модульность разработки и слабую связанность компонентов, поэтому получаем изолированную и распределённую систему.
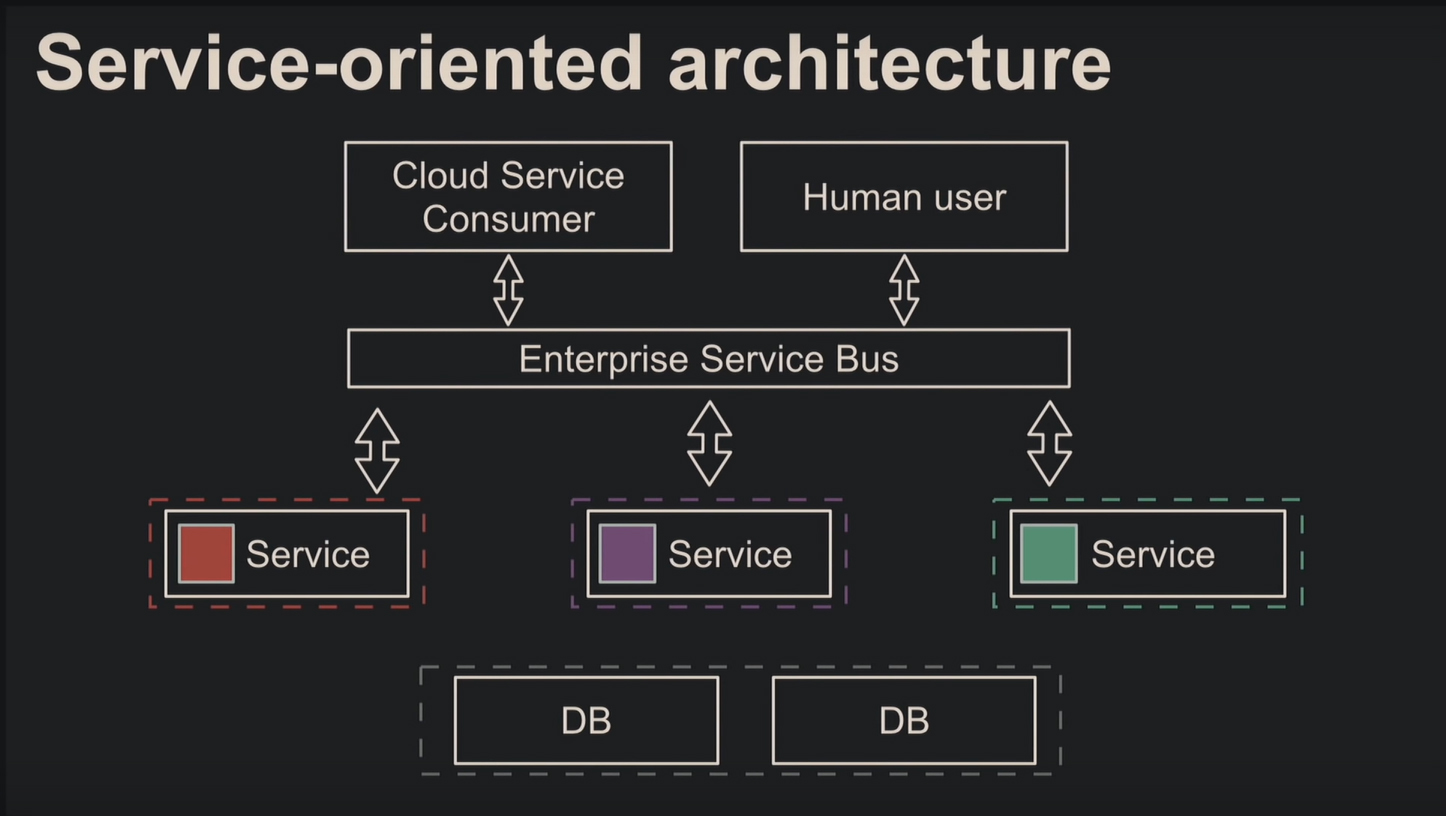
Главный минус – общая шина данных Enterprise Service Bus с огромными спецификациями и сложностями работы с абстракциями и фасадами.
Микросервисная архитектура
Микросервисная архитектура наследует от предшественницы изоляцию и распределённость. Здесь база данных не используется как шина данных, за исключением отдельных случаев в пользу производительности. По классической схеме компоненты изолируются и на уровне кода, и на уровне базы.
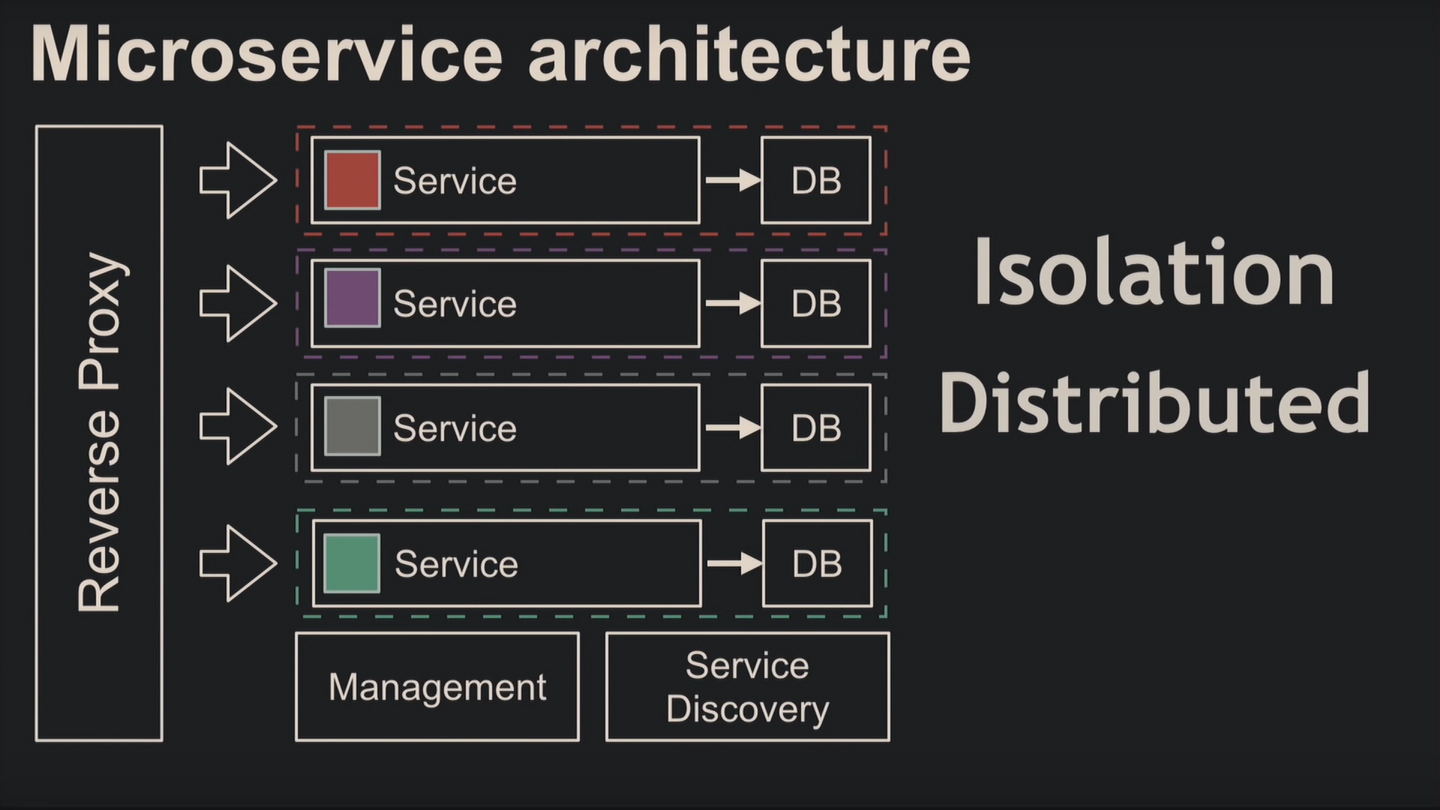
Для микросервисов применяют контейнеризацию с оркестрацией и другими плюшками.
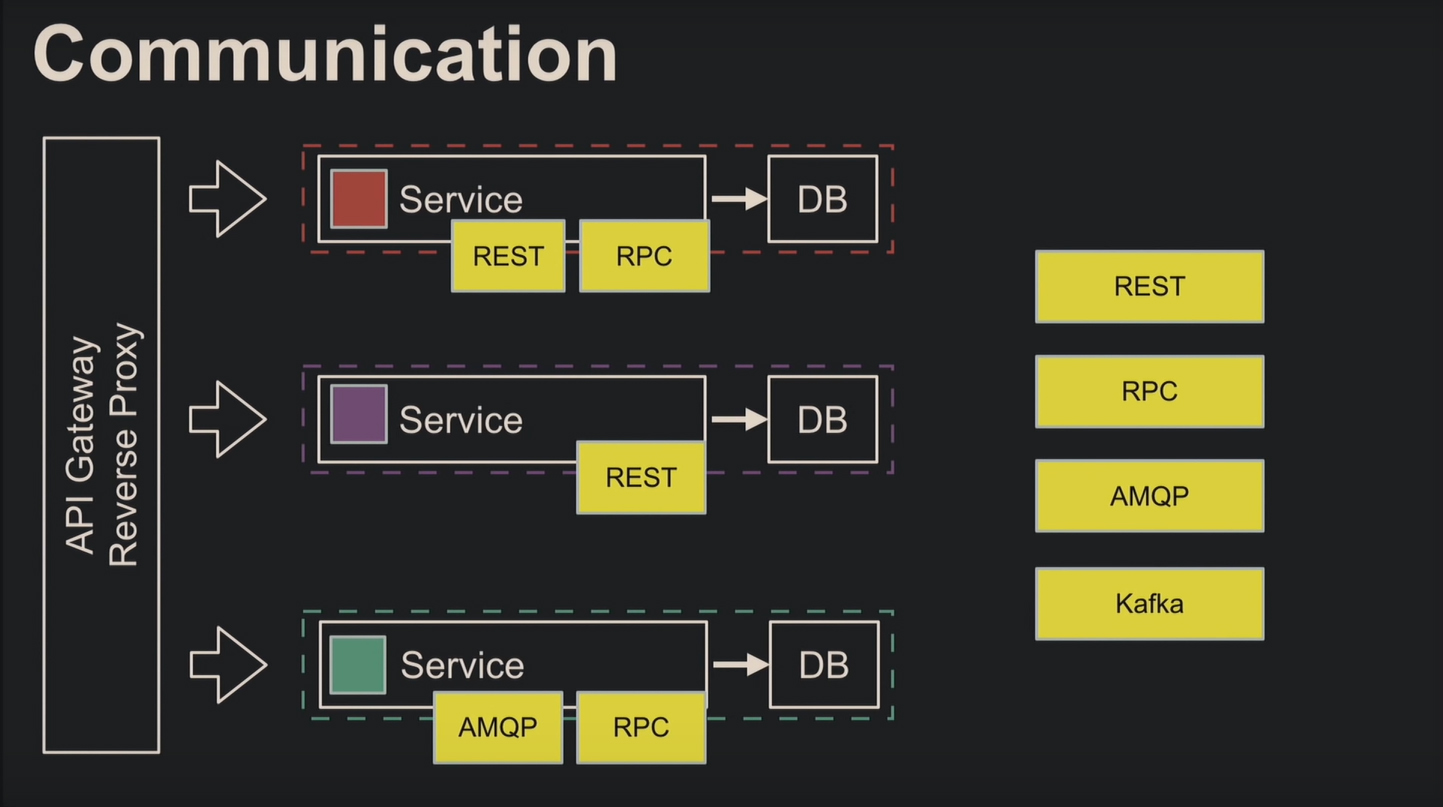
Следующее преимущество – протоколы обнаружения сервисов. Оцените наглядно разницу коммуникаций сервис-ориентированной и микросервисной архитектуры: у последней нет общей шины, и сервис обращается к любому другому напрямую:
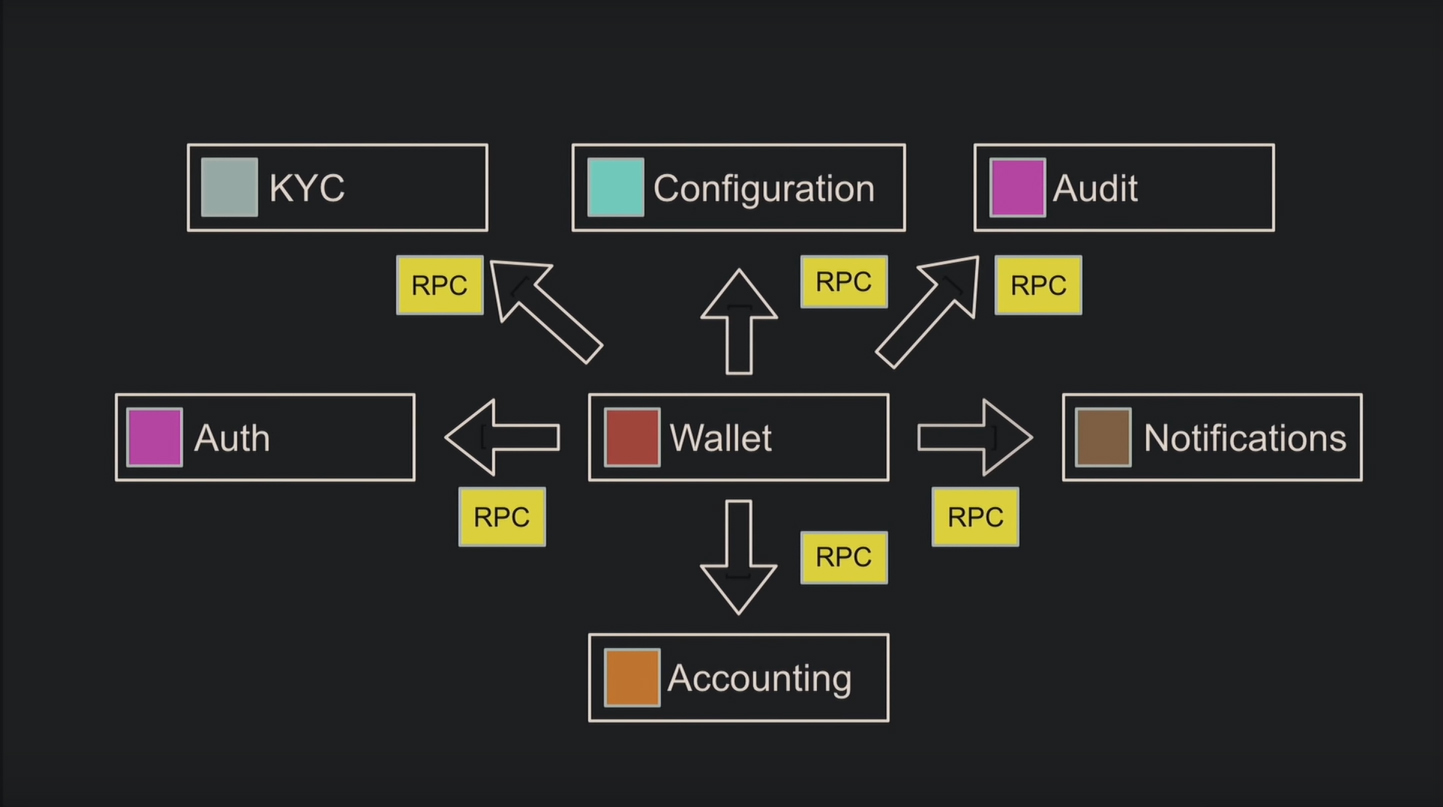
Выбор протоколов общения зависит от программиста. Например, вы используете REST для публичных запросов и RPC через AMQP для внутренних либо один общий протокол для всех.
Разделяют микросервисы с точки зрения либо бизнеса, либо программиста для переиспользования. Но мешают этому две вещи:
- внутренние связи – при тесном взаимодействии микросервисы объединяют;
- транзакции – у разных микросервисов базы данных изолированы, а нужна одна общая.
Рассмотрим пример разделения сервисов. Вначале поставили задачу прикрутить конфигурацию к авторизации, позже потребовалась аналогичная для кошелька. Само собой, напрашивается выделение конфигурации в отдельный микросервис. Для этого копируют код из предыдущей задачи, добавляют RPC для внутренних связей, абстракцию над клиентом для удобства и начинают использовать в других микросервисах.
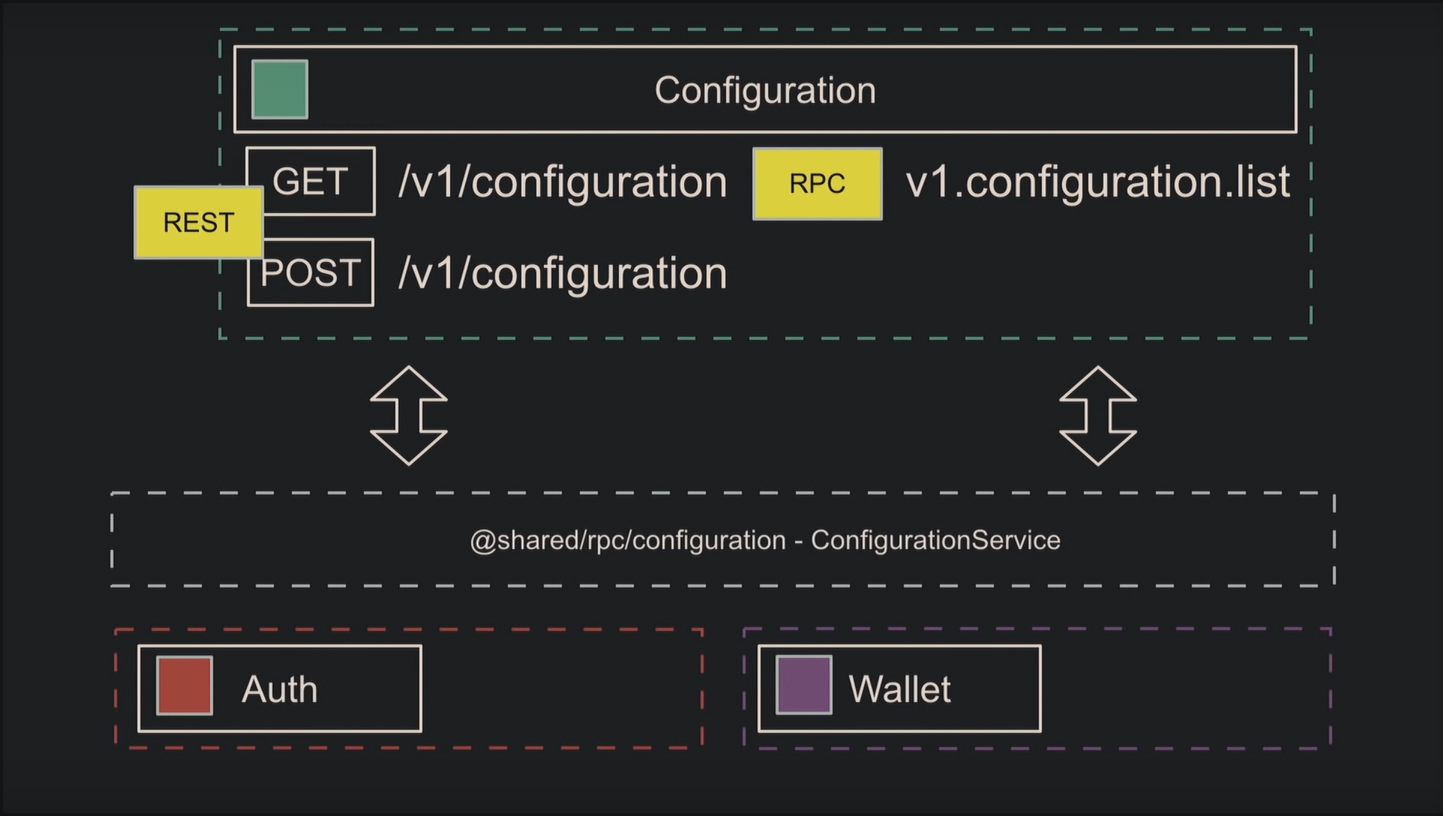
Достоинства и недостатки микросервисной архитектуры
Как в любой распределённой архитектуре, получим накладные расходы на коммуникацию.
Концепция непрерывной интеграции и доставки (CI/CD) и построение архитектуры (контейнеризация, оркестрация, мониторинг и другое) требует большого количества времени.
Что насчёт отказоустойчивости? Часто её определяют как «падение одного сервиса не отражается других». Представьте, падает Audit, а Wallet теоретически продолжает работать – похоже на отказоустойчивость:
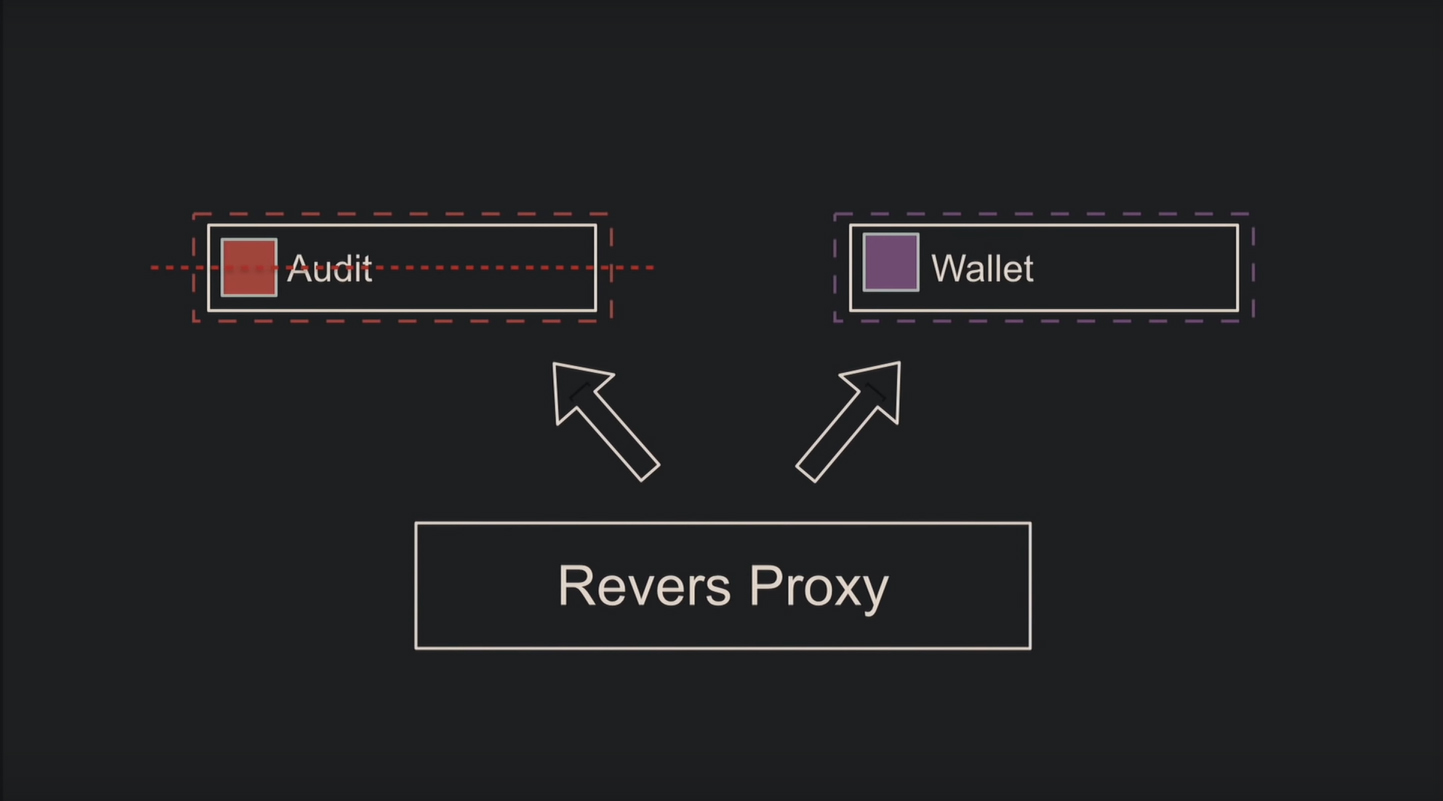
А как же запросы по RPC, которые Wallet продолжает слать? Необходимо программно предусмотреть ситуацию, когда Audit не отвечает, и грамотно настроить rollback, поскольку базы разные, и транзакционно это сделать не получится.
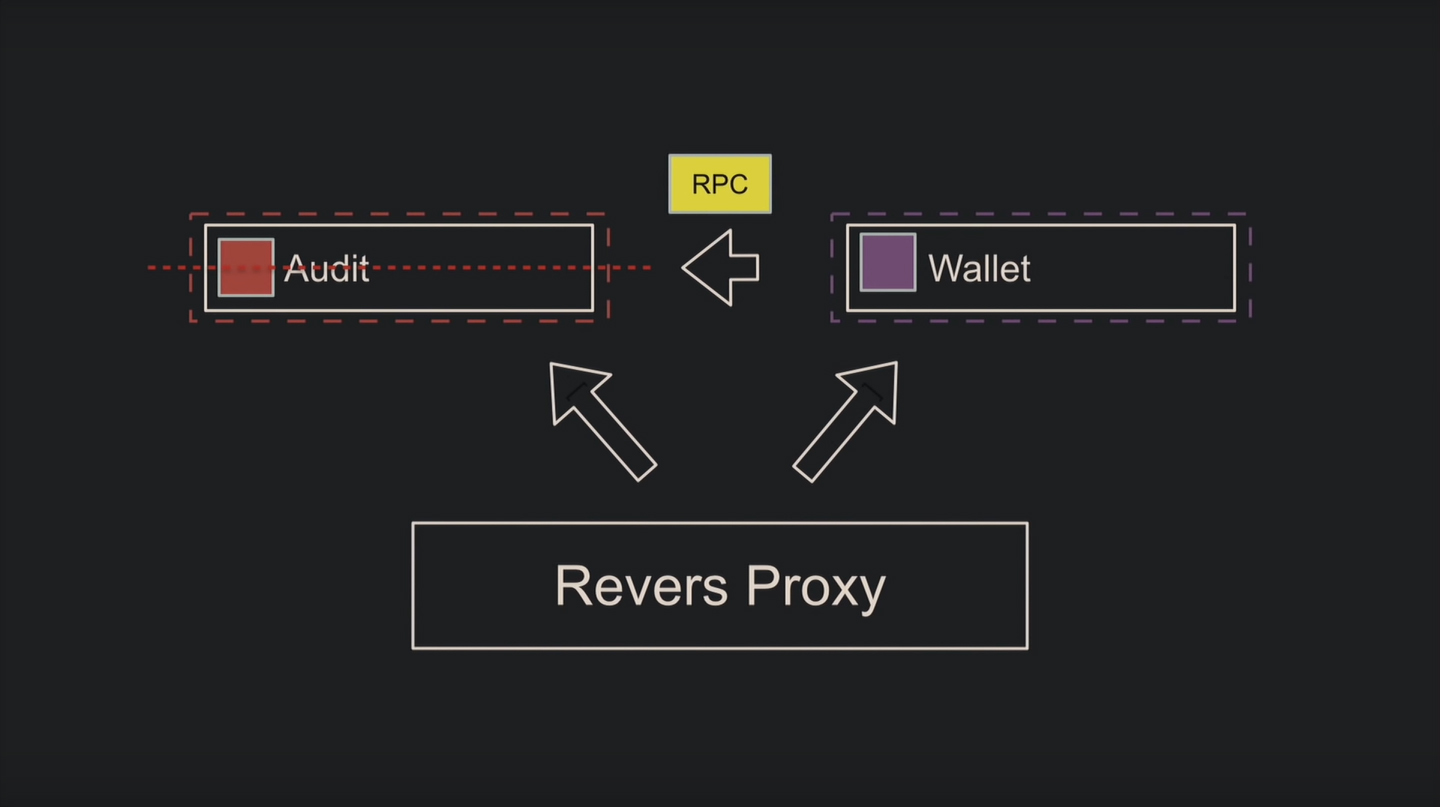
Или другая ситуация: падает микросервис авторизации, через который ходят другие. Чтобы продолжать обрабатывать запросы, добавляют код для неавторизованного пользователя. По существу, это мощный отказ.
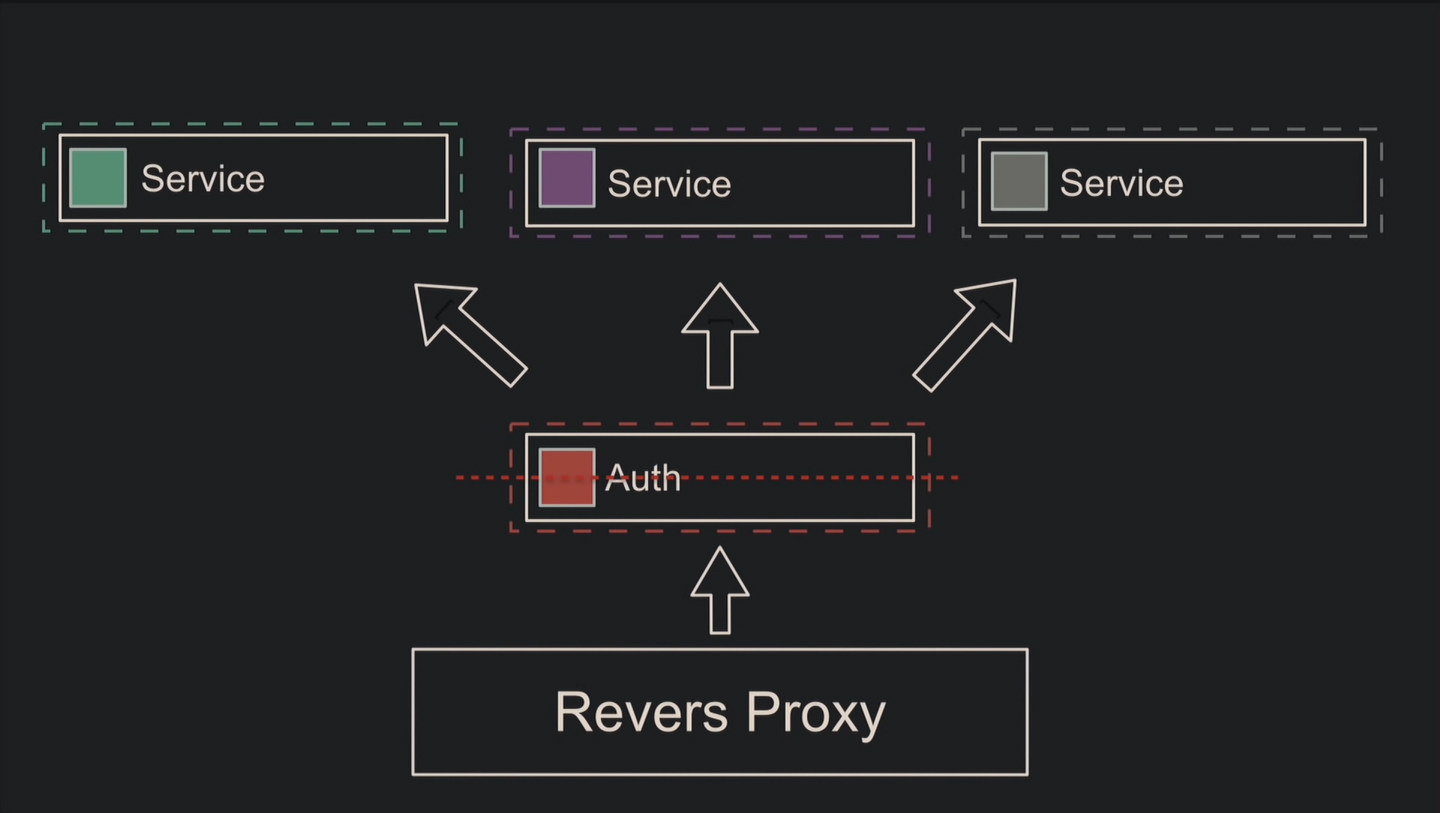
Масштабируемость у микросервисов достигается благодаря системам оркестрации, ведь остаётся достаточно серверных ресурсов в противоположность монолиту, который потреблял всю память и процессор.
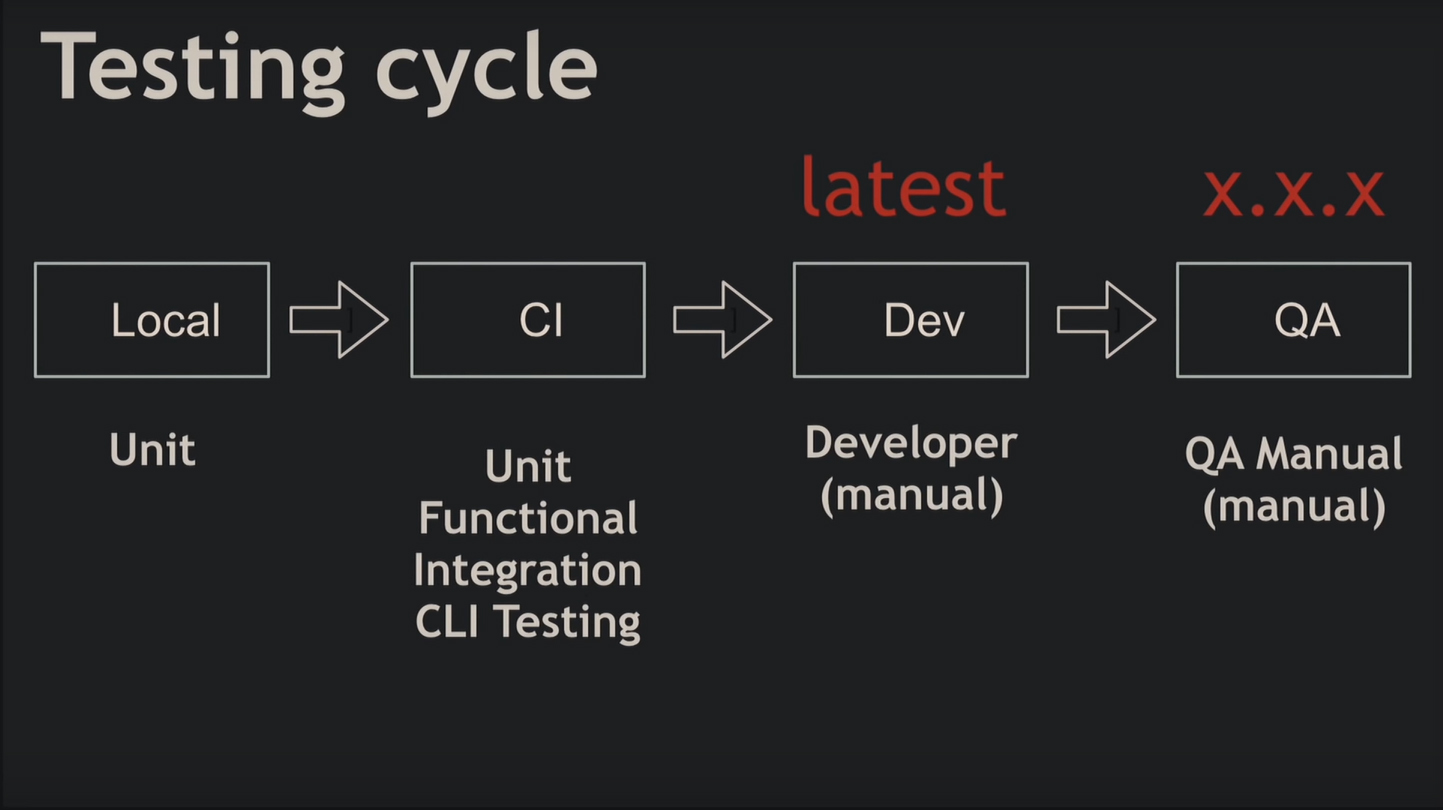
Стандартный процесс разработки – кодинг, тестирование и развёртывание – в микросервисной архитектуре выглядит иначе. Первые два этапа сливаются, поскольку микросервис взаимодействует с кучей других. Чтобы локально сделать хоть один запрос, придётся запустить все эти микросервисы, поэтому тестирование вручную не подходит для подобной задачи.
Представьте, вы тестируете перевод средств в банковской системе. Для этого вы создаёте двух пользователей, компанию, агента для пополнения счёта, делаете эмиссию в систему, чтобы пополнить хранилище агента деньгами, вносите средства на личный счёт отправителя и только потом делаете перевод получателю.
Будете выполнять столько запросов вручную? Добавьте ещё сложности взаимодействия микросервисов и получите ад.
Поэтому локально разработчик проводит юнит-тестирование, где вместо ответов микросервисов будут mock-объекты. Ещё понадобятся функциональные тесты, например, для отлавливания проблем коммуникации, а также интеграционные тесты. Они прогоняются вместе с юнит-тестами на этапе слияния рабочий копий в главную ветку разработки. И только потом программист проверяет функциональность руками. До развёртывания релизную версию тестирует QA.
Микросервисная архитектура делает компоненты независимыми при разработке и развёртывании, чего не было в монолите.
Микросервисы используются повторно и экономят средства в плане бизнеса.
Программист получает относительную свободу в выборе языка и технологий для разработки отдельных частей проекта.
Контроль зависимостей
Трудно сопроводить и поддерживать 50 проектов с 50 репозиториями, если вдруг обнаружится баг безопасности, который нужно срочно пофиксить во всех них. Поэтому используйте контроль зависимостей, общие библиотеки для микросервисов и семантическое версионирование. Причём не делайте одну раздутую библиотеку, а разбивайте её на кучу маленьких, чтобы избежать страха выпуска мажорной версии.

Инвертируйте зависимости: прописывайте версию драйвера в пакет, куда добавляете нужные микросервисы, чтобы потом не пришлось сломя голову перепроверять версии во всех проектах. Для внешних зависимостей лучше зафиксировать версии.
Базы данных
Поскольку базы данных в микросервисной архитектуре изолированные, вы используете разные их виды одновременно и получаете повышенный уровень безопасности, благодаря общению сервисов только через RPC. Но что делать, когда объединяемые данные в разных микросервисах?
Вот возможные решения проблемы:
- храните одно и то же значение в двух микросервисах, но появляются трудности с актуализацией данных;
- делайте RPC, правда, усложните работу с большими объёмами информации;
- выгрузите данные из всех баз для аналитики;
- сделайте миграцию данных, что тоже непросто и повлечёт написание RPC.
Представьте другой случай: при регистрации создаётся 3 сущности (пользователь, профиль и счёт), но на полпути что-то падает. Как откатить изменения, если данные распределяются по разным микросервисам? Думайте об этом на этапе проектирования.
Внутренняя коммуникация в микросервисной архитектуре
Для общения микросервисам нужен контракт: протокол и валидация данных. С последним справляется JSON Schema, но протокол также необходим. Требования при выборе способа коммуникации:
- строгость;
- общий протокол для сервера и клиента;
- генерация кода для любого языка;
- производительность.
В качестве протоколов используют Protocol Buffers, FlatBuffers, Apache Thrift. Сначала вы пишете предметно-ориентированный язык, отдаёте это программе-генератору кода и получаете сгенерированный клиент и сервер.
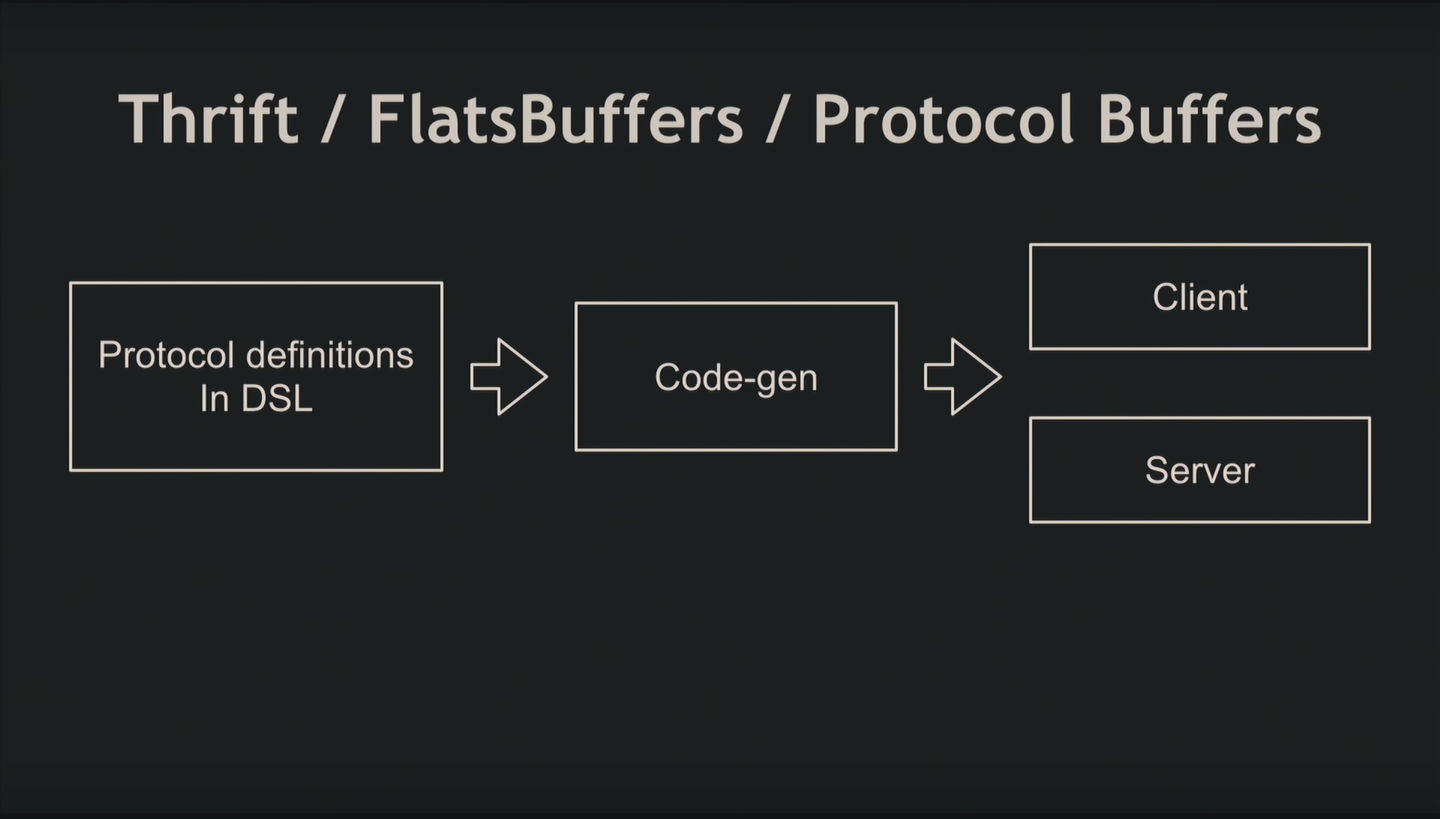
Организация работы в команде
Команды делят по технологиям и следят за их размерами (не более 7–8 человек). Как правило, задачи выдают сеньорам, рядом с которыми хватает разработчиков уровнем ниже.
К примеру, два сеньора из одной команды получили по два микросервиса. Важно, чтобы программисты взаимодействовали между собой не только в локальной группе по конкретной задаче, но и с другими. Тогда в области их знаний будет много общего:
- язык;
- организация и шаблонизация кода для каждого микросервиса;
- библиотеки;
- концепция непрерывной интеграции и доставки;
- протокол коммуникации;
- документация.
А что объединит разнородные по языкам команды? Останется только CI/CD, глобально стандартизованный прокол и подход к документированию.
Устройство микросервисов
Микросервисы состоят из трёх слоёв: небольших обработчиков, бизнес-логики и мапперов данных. Последовательность выполнения запроса выглядит так:
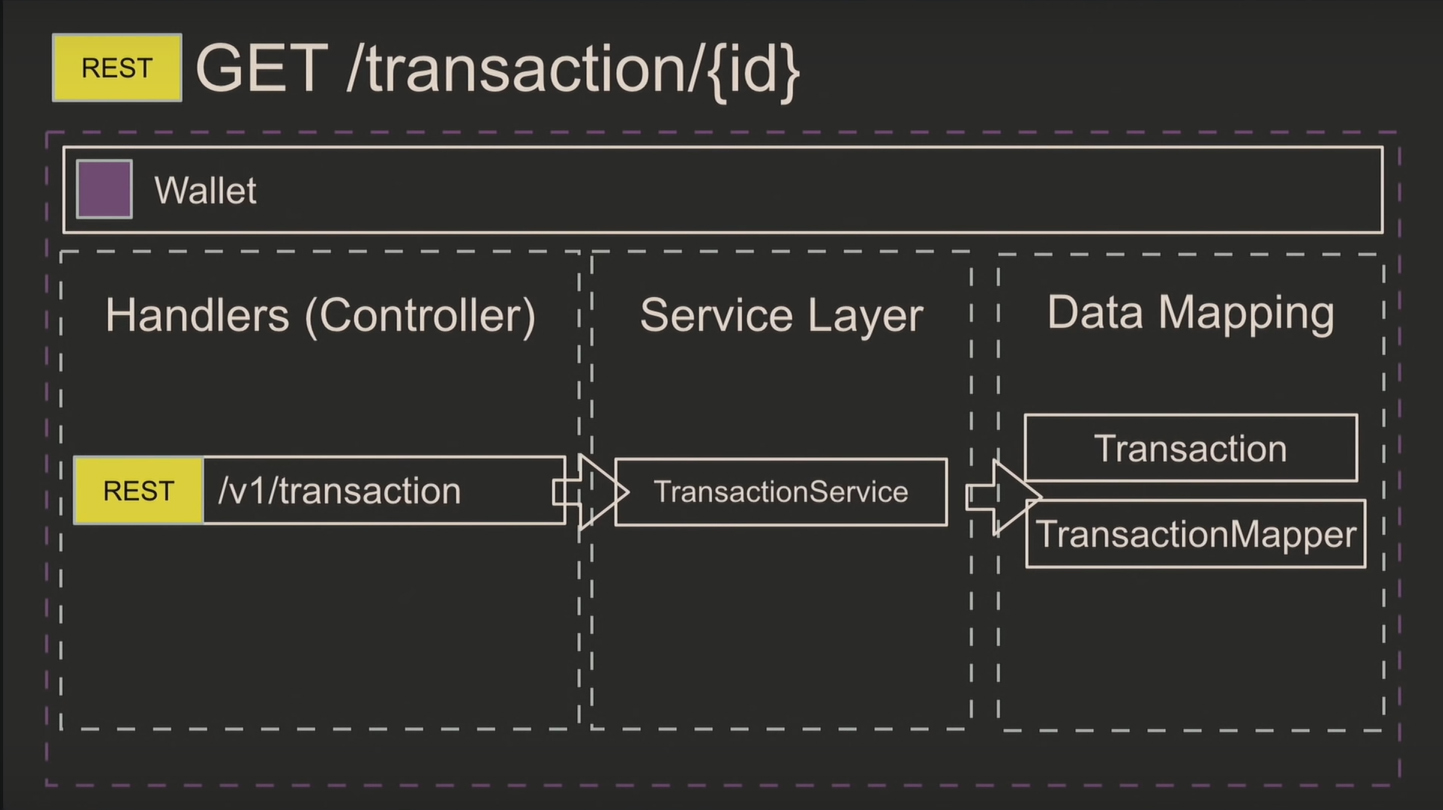
В сервисном слое сосредотачивается 99% всего кода. Поскольку в микросервисе несколько обработчиков, используйте Data Transfer Object (DTO), к которому вы будете приводить GET-запрос. Это облегчает обработку и валидацию.
Примеры кода
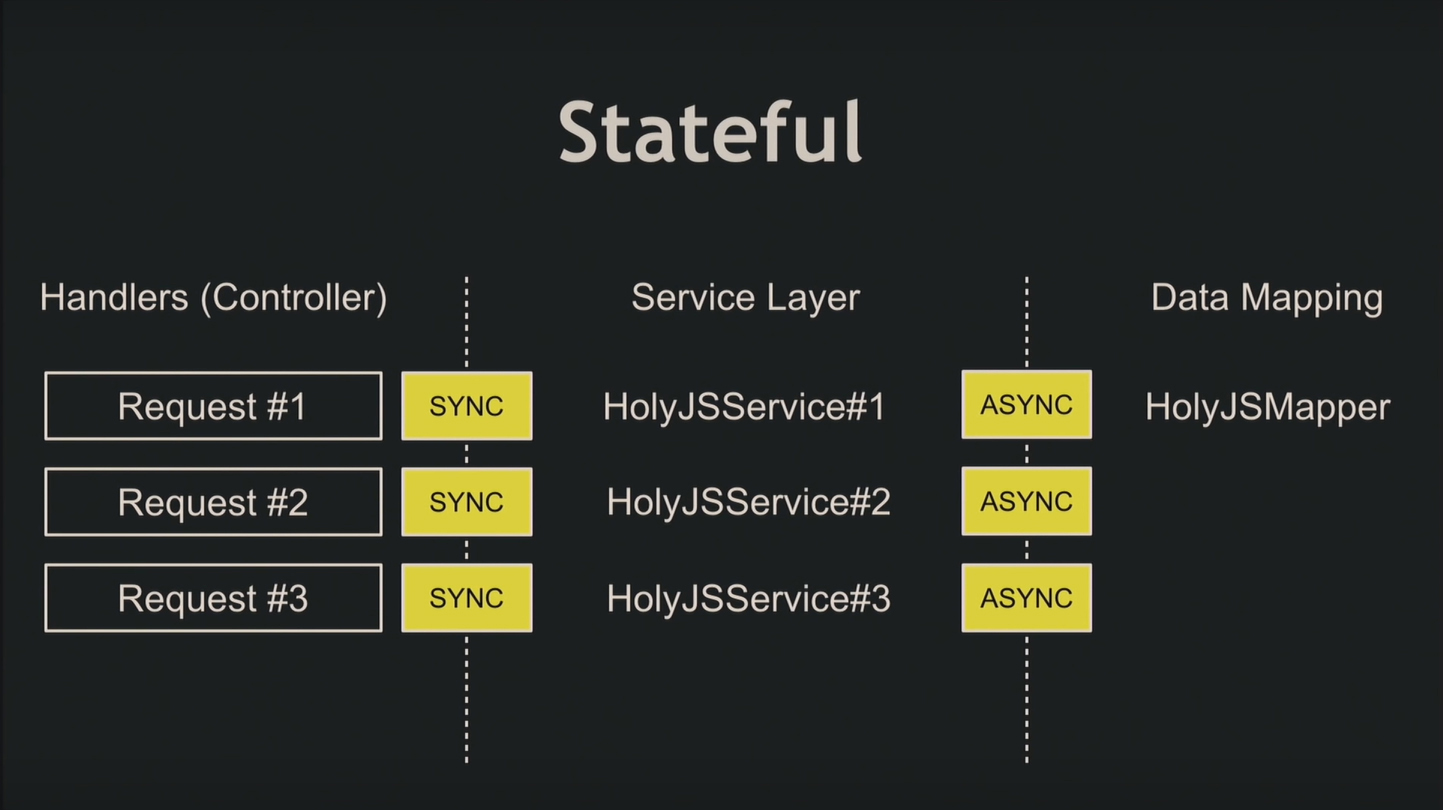
Не забывайте, что Node.js – асинхронный язык. Рассмотрим пример: приходит запрос, синхронно берёт HolyJSService, асинхронно работает с маппером, выполняющим запись в базу данных, и процесс повторяется для последующих запросов. Никакого порядка в этом не наблюдается, поэтому выделяют два архитектурных подхода:
- stateless – не хранить состояние;
- stateful – добавлять объекту класса поля, которые нужны для выполнения запроса.
Когда используете stateful, при получении запроса вы создаёте новый объект HolyjSService и заполняете необходимыми для выполнения данными. Дальше этот сервис асинхронно идёт в базу данных. Следующий запрос берёт новый экземпляр сервиса, и процесс повторяется.
В коде вы реализовываете абстрактный класс с кучей полей и сеттеров, наследуете от него новый сервис и наполняете методами.
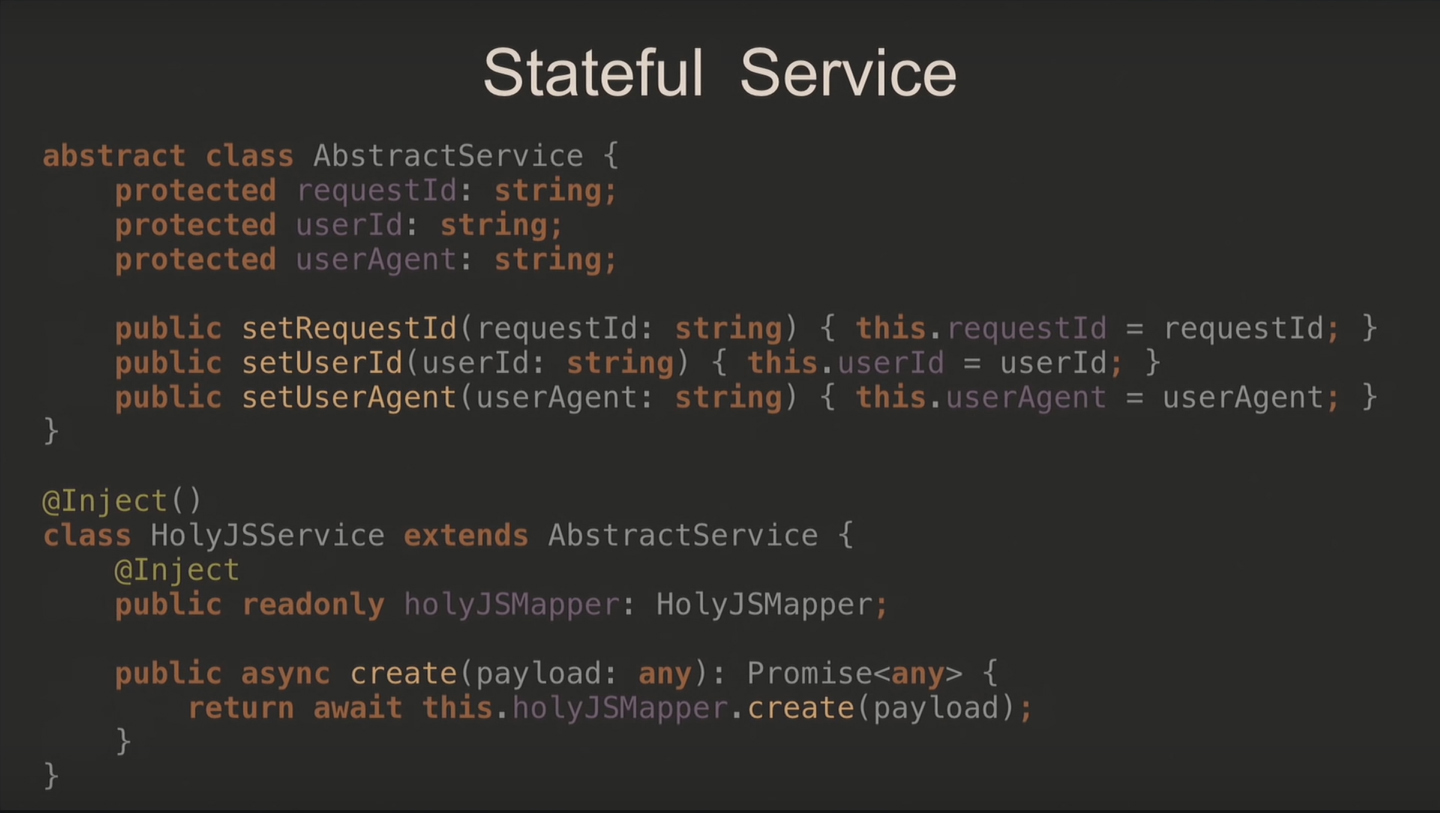
Дальше обработчику нужен контейнер DI для получения нового экземпляра, который он пробрасывает в функцию. После её запуска и выполнения всех сеттеров вызываем сервисы в методе create и возвращаем результат.
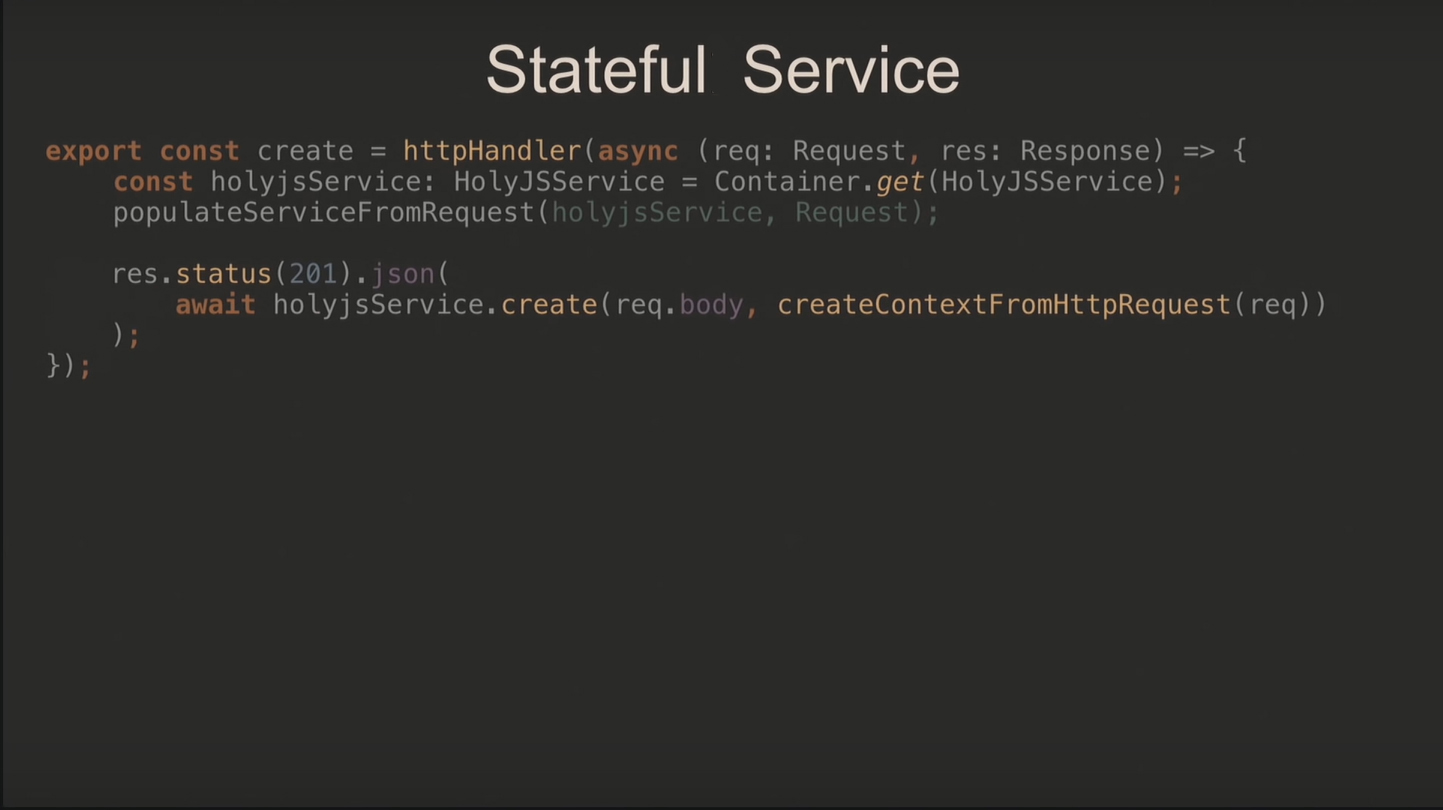
При stateless-подходе используется контекст, который создаётся для каждого запроса отдельно, и единственный экземпляр сервиса, поскольку выполнение запросов от него не зависит.
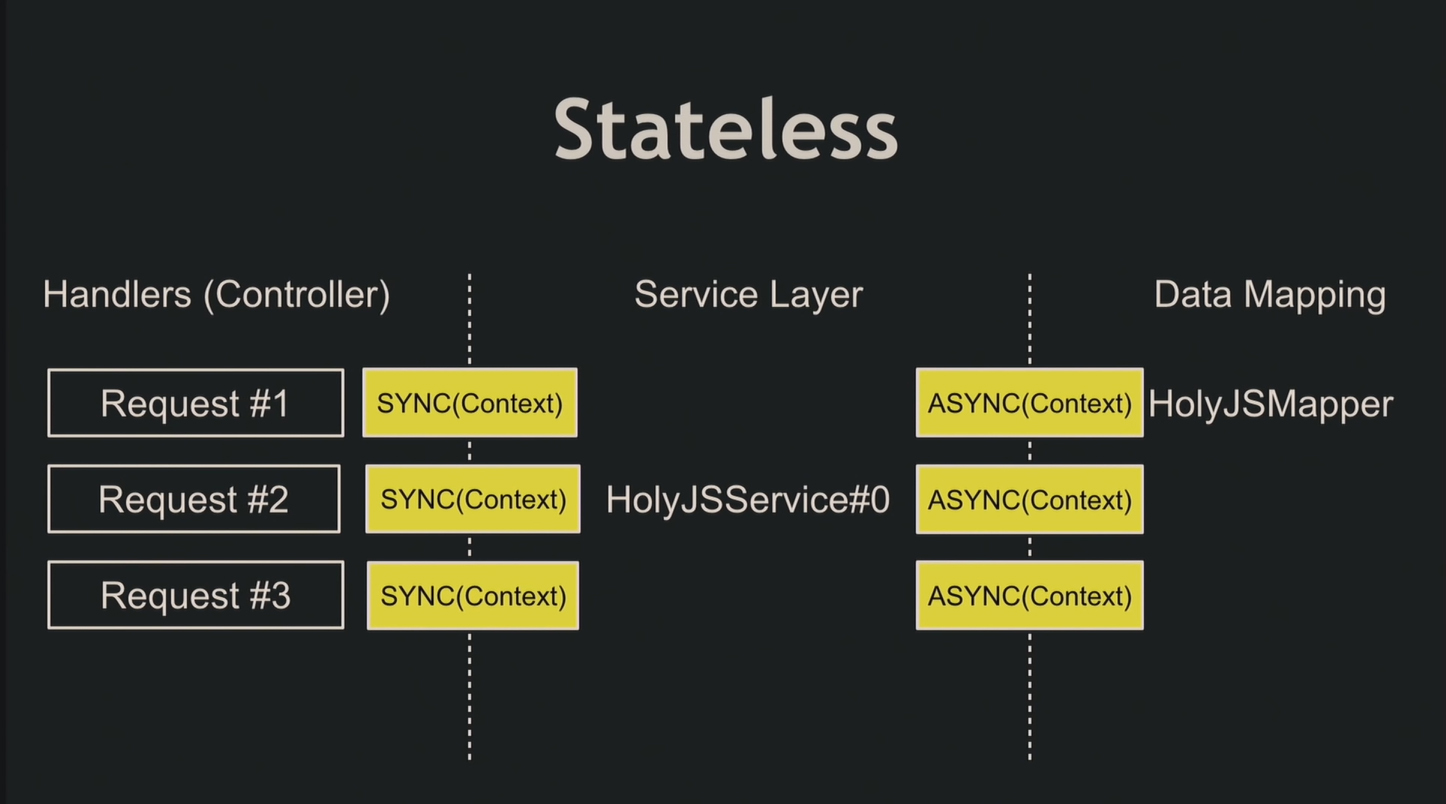
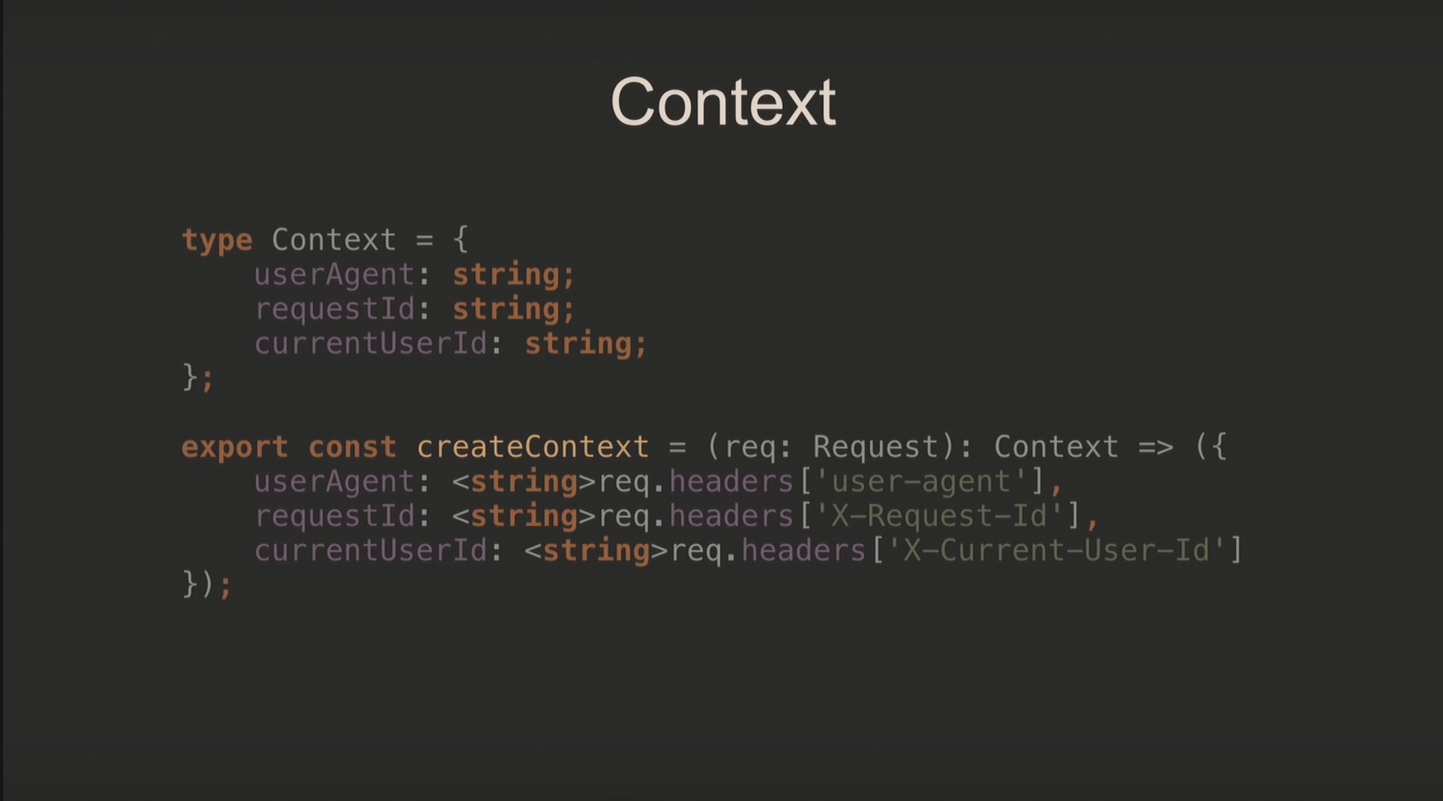
В контексте хранятся все необходимые поля и собственно метод для его создания:
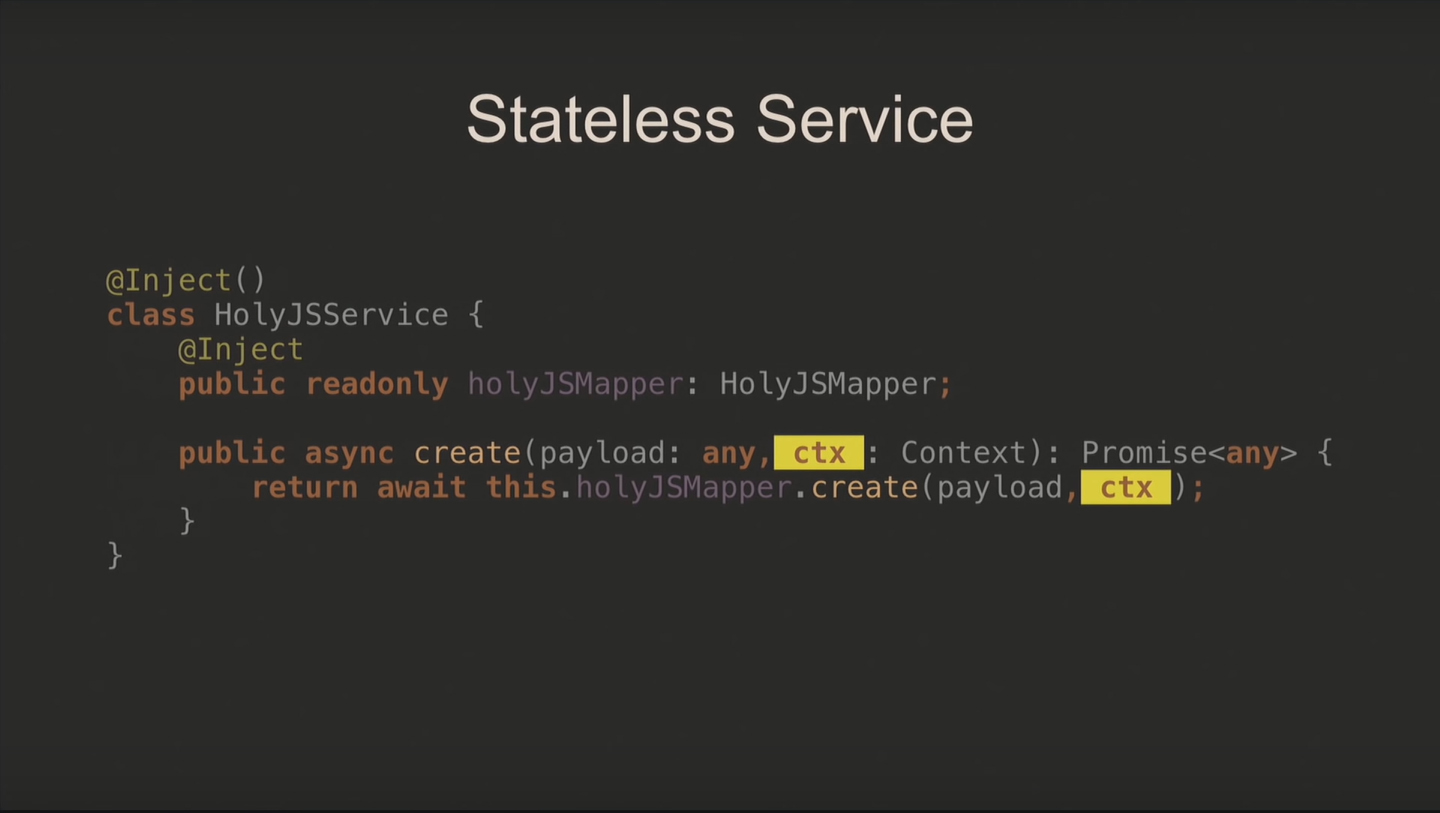
На уровне сервиса выглядит как дополнительный параметр:
Для обработчика добавляем контекст вторым параметром – его возвращает метод createContextFromHttpRequest:
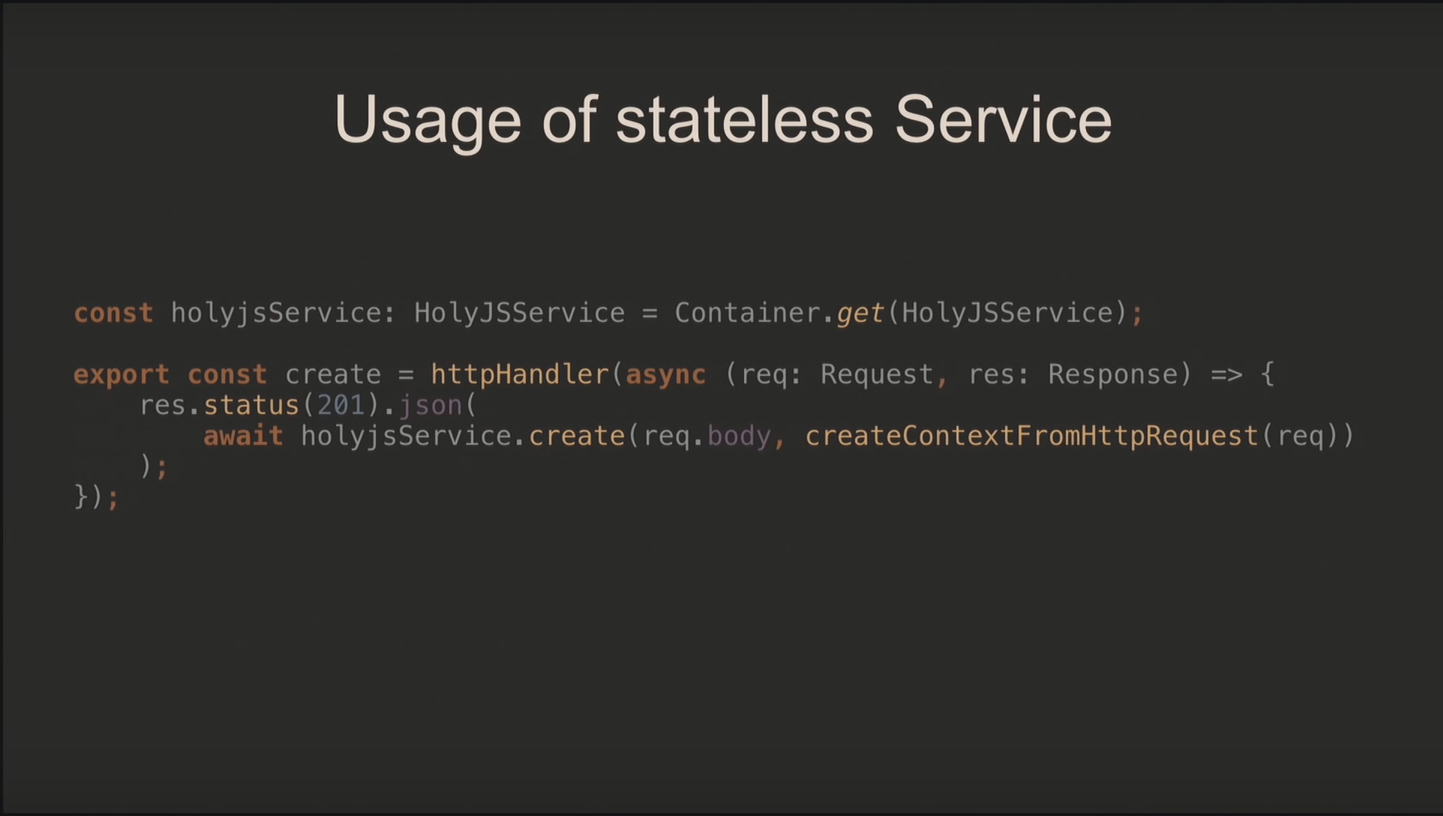
Сами по себе хэндлеры предельно простые:
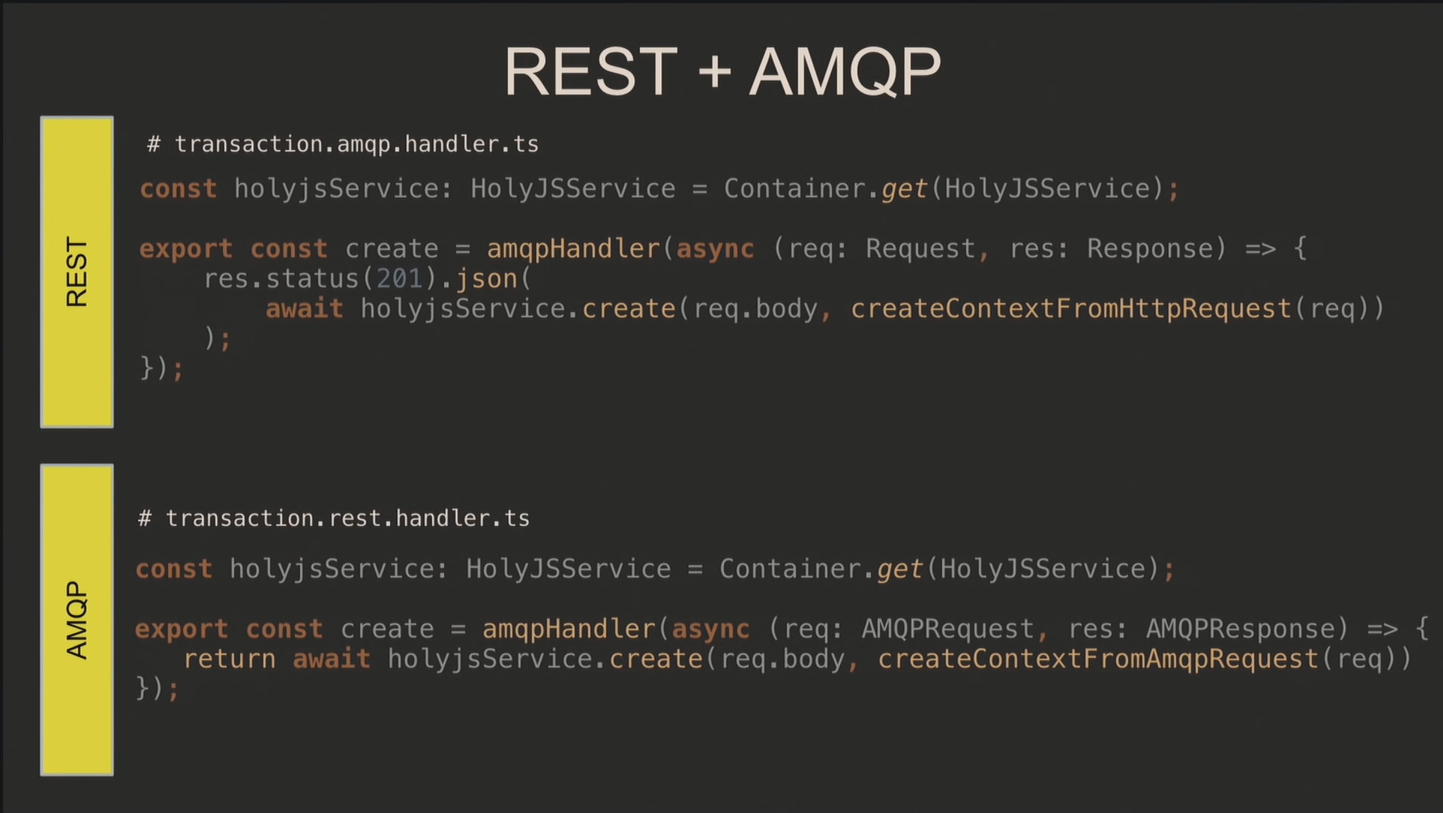
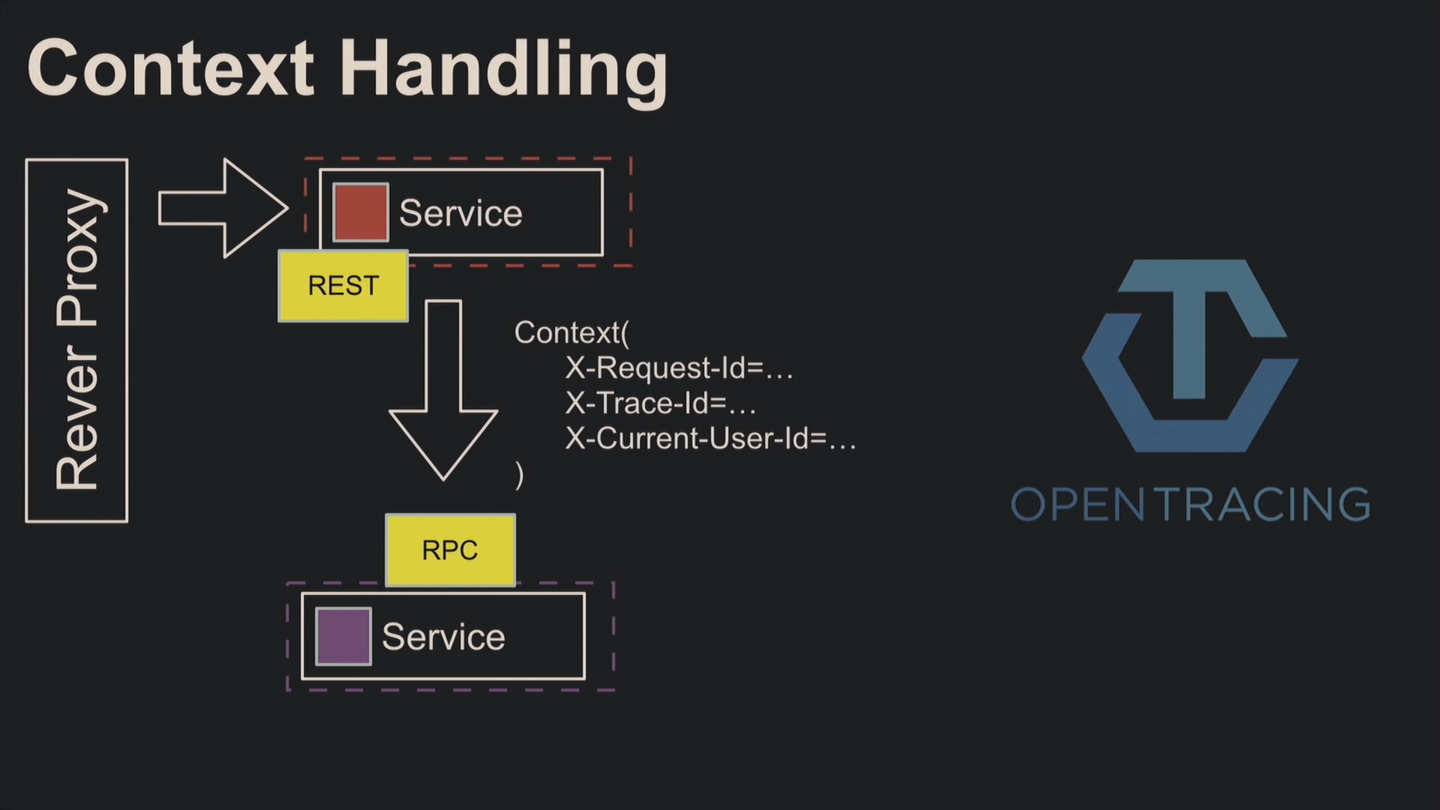
Поскольку для выполнения запросов часто нужны другие сервисы, контекст приходится прокидывать в них. Допустим, на первый микросервис поступил запрос. Присваивайте ему идентификатор X-Request-Id, с которым он пройдётся по всем микросервисам. Благодаря логированию вы легко отследите путь внешнего запроса. X-Trace-Id используется для обозначения единой бизнес-операции, состоящей из нескольких запросов.
Для создания идентификаторов используют OpenTracing.
Рассмотрим пример, когда не получается написать микросервис без сервиса. Вам дали задачу реализовать управление доступом на основе ролей (RBAC). Вы проектируете три сущности: роль, ресурс и правило. Пишете RPC, а из соображений производительности и удобства добавляете дополнительный сервис для работы с этим RPC, ролями, правилами и ресурсами.
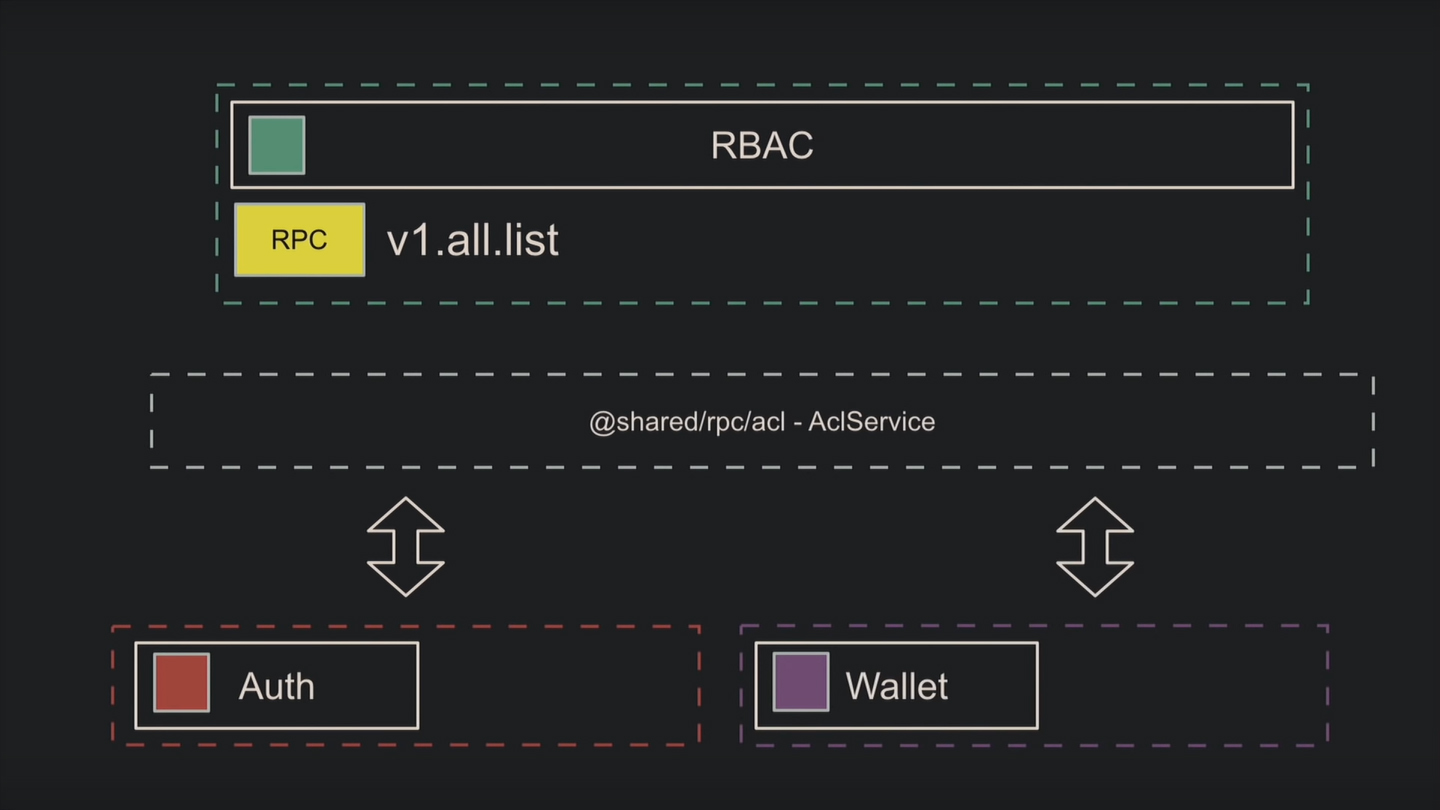
Теперь отдельные микросервисы используют созданный сервис и общий интерфейс.

Если команде, которая пишет на другом языке, также понадобился RBAC, придётся написать для них дополнительный RPC. Однако не получится создать RPC для добавления фильтров или условий к управлению доступом.
Заблуждения
1. Это легче
После прочитанного вы вряд ли посчитаете микросервисную архитектуру лёгким делом, но это распространённое заблуждение. Сложность создания микросервиса наглядно показывает график:
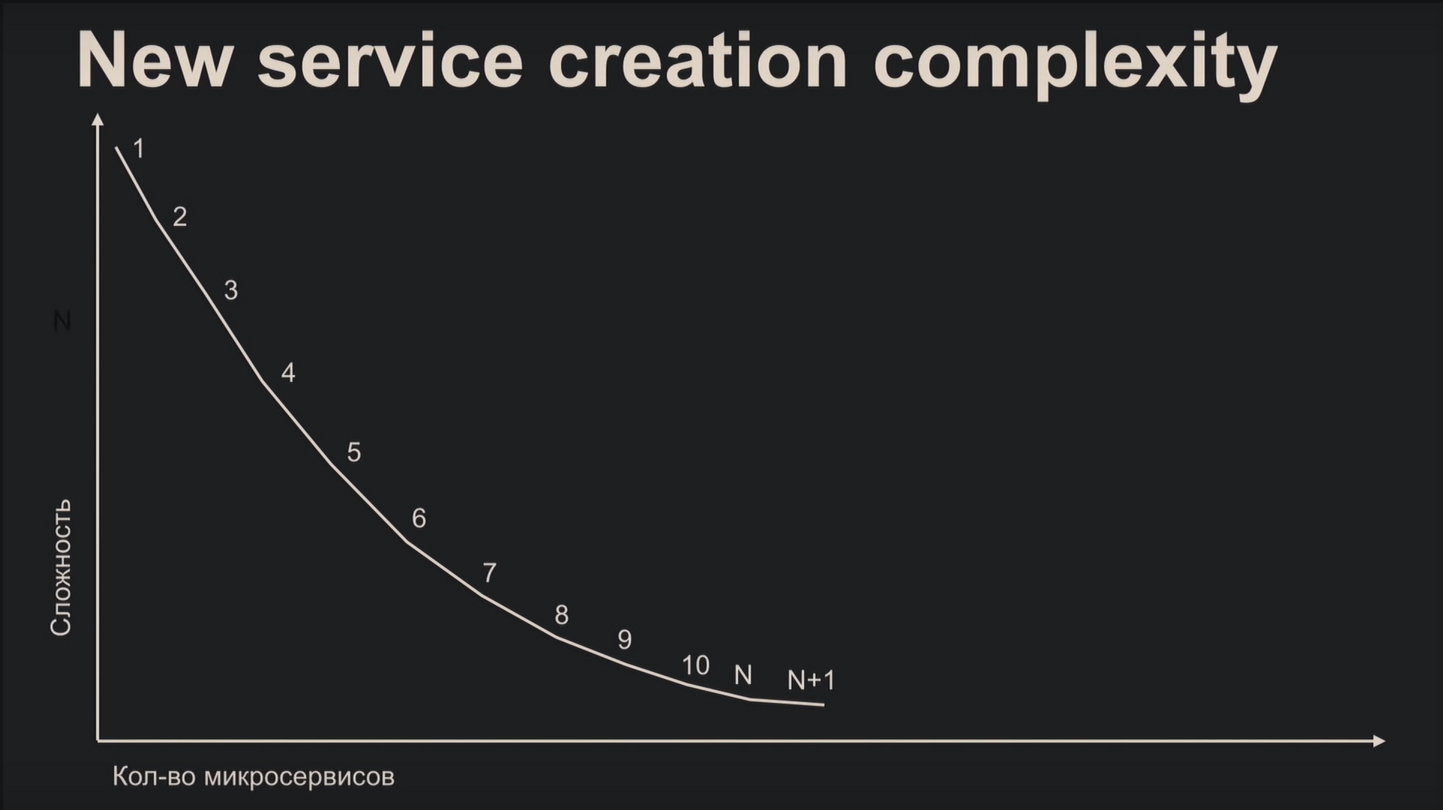
С самого начала вы медленно и печально разбираетесь с документацией, бесконечно подбираете протоколы и другие компоненты. К энному микросервису вы нарабатываете стандартные шаблоны, что в несколько раз облегчает процесс.
С точки зрения поддержки – наоборот, потому что увеличивается количество микросервисов. Новый разработчик вынужден будет часами сидеть за изучением диаграмм, чтобы понять глобальную картину и принцип работы системы.
2. Лучше производительность
Представьте, сколько придётся ждать отправителю комплексного запроса, пока он сходит в кучу разных микросервисов. Поэтому ради производительности переезжать на эту архитектуру не всегда целесообразно. В качестве альтернативы перепишите куски проекта на более эффективном языке, или добавьте профилирование к монолиту.
Заключение
Принимайте решение об использовании микросервисной архитектуры, только чётко осознав и взвесив все достоинства и недостатки. Вам будут нужны знания о создании распределённой архитектуры и возможность реализации необходимых структурных элементов со стороны бизнеса. Ведь без логирования, мониторинга, трассировки, непрерывной интеграции и оркестрации вы обрекаете себя на ад.