Несколько редко используемых, но вполне полезных функций MSSQL. Если вы никогда не слышали о функциях CHOOSE, ROW_NUMBER, RANK, DENSE_RANK, FIRST_VALUE, LAST_VALUE, LAG, LEAD, PERCENTILE_CONT и PERCENTILE_DISC, то ниже вы узнаете, какие полезные вещи можно сделать их помощью. Так же, я покажу несколько примеров использования выражений OVER и PARTITION BY в оконных функциях.
Подготовка
Создадим две таблицы Employees — информация о сотрудниках, Assessments — информация об изменениях зарплат сотрудников.
Employees
CREATE TABLE [dbo].[Employees]
(
[Id] [int] IDENTITY(1,1) NOT NULL,
[Name] [nvarchar](50) NOT NULL,
[Age] [int] NOT NULL,
[TeamName] [nvarchar](50) NOT NULL,
[Position] [nvarchar](50) NOT NULL,
[Department] [nvarchar](50) NOT NULL,
[Salary] [int] NOT NULL,
[Configuration] [int] NOT NULL,
CONSTRAINT [PK_Employees] PRIMARY KEY CLUSTERED ([Id] ASC)
)
Assesments
CREATE TABLE [dbo].[Assessments]
(
[Name] [nvarchar](50) NOT NULL,
[Year] [int] NOT NULL,
[Salary] [int] NOT NULL,
CONSTRAINT [PK_Assessments] PRIMARY KEY CLUSTERED ([Name] ASC, [Year] ASC)
)
Заполним эти таблицы тестовыми данными:
INSERT INTO [dbo].[Employees]
(Name, Age, TeamName, Position, Department, Salary, Configuration)
VALUES
('Smith',25,'World','QA','RnD',30000,1),
('Wesson',20,'World','QA','RnD',50000,2),
('Gray',23,'OLAP','QA','RnD',45000,3),
('Black',31,'Flamp','QA','Flamp',60000,1),
('White',33,'World','Dev','RnD',70000,2),
('Constantine',29,'OLAP','Dev','RnD',120000,1),
('Gurken',32,'World','Dev','RnD',110000,1),
('Dunky',26,'Flamp','Dev','Flamp',110000,3)
INSERT INTO dbo.Assessments
(Name, Year, Salary)
SELECT
e.Name,
2016,
e.Salary
FROM dbo.Employees e
UNION ALL
SELECT
e.Name,
2015,
(e.Salary - 1000 * CAST(RAND(CHECKSUM(NEWID()))* 20 AS int))
FROM dbo.Employees e
CHOOSE
В таблице Employees есть колонка Configuration, которая может принимать одно из трех значений (1, 2, 3) — конфигурация рабочего места сотрудника (обычный PC, мобильная конфигурация или макбук соответственно). И если для хранения достаточно числового значения, то для отображения необходимо расшифровать его в строку. В классическом варианте можно создать временную таблицу из трех значений и сделать JOIN из нашей таблицы сотрудников:
CREATE TABLE #Configuration (Id int, Value nvarchar(10))
INSERT INTO #Configuration
VALUES
(1, 'PC'), (2,'Mobile'), (3,'Mac')
SELECT
e.*,
c.[Value]
FROM dbo.Employees e
INNER JOIN #Configuration c ON e.Configuration = c.Id
В результате получим именно то, что хотели, правда немного многословно: нам пришлось создать дополнительную таблицу и сделать соединение. Более простой вариант — использовать CASE-WHEN:
SELECT
e.*,
(CASE e.Configuration
WHEN 1 THEN 'PC'
WHEN 2 THEN 'Mobile'
WHEN 3 THEN 'Mac'
END)
FROM dbo.Employees e
Но благодаря функции CHOOSE этот код можно еще сократить и сделать более читаемым:
SELECT
*,
CHOOSE(e.Configuration, 'PC', 'Mobile','Mac')
FROM dbo.Employees e
Первый аргумент функции — индекс, по которому надо взять значение из оставшегося списка. Если индекс указывает на не существующее значение, то функция привычно вернет NULL. Все три варианта дают одинаковый результат. Вариант с CHOOSE выглядит предпочтительным для «расшифровки» перечислений, состоящих из небольшого количества значений.
ROW_NUMBER, RANK, DENSE_RANK
Все три функции похожи, но наиболее часто используется функция ROW_NUMBER. С нее так же начинается обзор оконных функций, предполагается, что вы уже знакомы с этим понятием.Итак, ROW_NUMBER позволяет нам занумеровать уникальными последовательными значениями все строки выборки или в пределах какой-то группы.Например, давайте составим рейтинг сотрудников по убываю зарплаты в пределах всей компании и в пределах каждой должности:
SELECT
e.Name,
e.Salary,
ROW_NUMBER() OVER(ORDER BY e.Salary DESC) AS EmployeId,
e.Position,
ROW_NUMBER() OVER(PARTITION BY e.Position ORDER BY e.Salary DESC) AS PositionId
FROM dbo.Employees e
Результат:
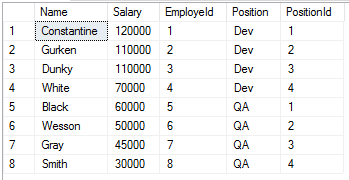
Итак, мы действительно получили рейтинг зарплат и даже с разбивкой по должности. Можно заметить, что некоторые сотрудники (Gurken и Dunky) получают одинаковую зарплату, но находятся на разных позициях рейтинга, что выглядит не логично. Для исправления этой ситуации есть функция RANK:
SELECT
e.Name,
e.Salary,
RANK() OVER(ORDER BY e.Salary DESC) AS EmployeId,
e.Position,
RANK() OVER(PARTITION BY e.Position ORDER BY e.Salary DESC) AS PositionId
FROM dbo.Employees e
Цель этой функции — дать относительный порядок строки в наборе.
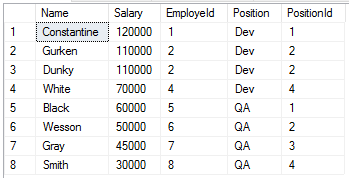
Как мы видим, теперь сотрудники с одинаковой зарплатой находятся на одинаковой позиции в рейтинге. При этом, следующий сотрудник (White) находится на четвертой позиции — эта функция учитывает пропуски. Если же нам не нужны пропуски, и следующий сотрудник должен стать третьим, то необходимо использовать функцию DENSE_RANK:
SELECT
e.Name,
e.Salary,
DENSE_RANK() OVER(ORDER BY e.Salary DESC) AS EmployeId,
e.Position,
DENSE_RANK() OVER(PARTITION BY e.Position ORDER BY e.Salary DESC) AS PositionId
FROM dbo.Employees e
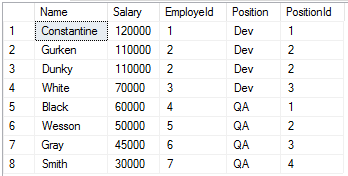
Теперь наш рейтинг составлен без пропусков, но с учетом одинаковых значений зарплаты.
FIRST_VALUE, LAST_VALUE
Вот нашей компании потребовалось провести интеграционное тестирование, а это значит, что нужно собрать по одному представителю QA из каждой команды. Пусть будет любой QA из команды, без каких-то условий. Тогда эту задачу можно решить таким способом:
SELECT
e.TeamName,
MAX(e.Name) AS QAName
FROM dbo.Employees e
WHERE e.Position = 'QA'
GROUP BY e.TeamName
Получим вот такой результат:
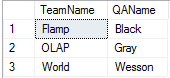
Вместо функции MAX можно взять MIN, что не сильно изменит ситуацию. Подумав, что тестирование — это дело ответственное, решили выбрать самого старого по возрасту тестировщика из каждой команды. Это можно сделать таким способом:
SELECT
e.TeamName,
(
SELECT TOP 1
e2.Name
FROM dbo.Employees e2
WHERE e2.TeamName = e.TeamName AND e2.Position = 'QA'
ORDER BY e2.Age DESC
) AS QAName
FROM dbo.Employees e
GROUP BY e.TeamName
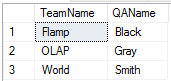
Как мы видим, Smith старше, чем Wesson, поэтому и попал в нашу итоговую выборку. Но появился один подзапрос, который кажется лишним. Как нам поможет решить эту проблему функция FIRST_VALUE? Эта функция возвращает первую строку сортированного набора. А значит, можем из всех наших сотрудников оставить только QA, поделить по командам, отсортировать по убыванию возраста и выбрать первого:
SELECT
e.TeamName,
FIRST_VALUE(e.Name) OVER (PARTITION BY e.TeamName ORDER BY e.Age DESC) AS QAName
FROM [dbo].[Employees] AS e
WHERE e.Position = 'QA'
В результате получаем:
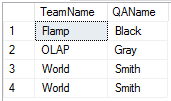
Почему получили две одинаковые строки (World, Smith)? На первый взгляд это кажется не логичным. Но если посмотреть на запрос без функции FIRST_VALUE, то мы увидим, что выбрали только всех QA (по условию WHERE), а их у нас как раз таки 4, и для каждого выбрали команду и самого старого QA в команде. Сделали немного задом наперед. Для нужного результата нам нужно использовать DISTINCT. Согласен, не самое подходящее использование функции, но все же. Функция LAST_VALUE работает аналогично, но возвращает последний результат набора.
NTILE
В связи с реформами в компании, сотрудников из трех существующих команд необходимо распределить по четырем новым командам. Не вопрос! Для этого есть функция NTILE, которая в качестве параметра принимает количество групп, на которые необходимо разделить исходный набор. Каждая строка получит номер группы, к которой она принадлежит:
SELECT
e.Name,
e.Position,
e.TeamName,
NTILE(4) OVER(ORDER BY e.Id) AS NewTeamId
FROM dbo.Employees e
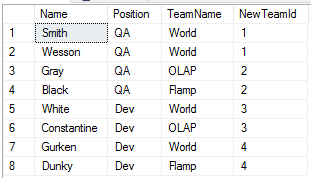
Каждый сотрудник получил NewTeamId — номер новой команды, в которую попадает сотрудник. Только вот в командах 1 и 2 собрались одни QA, а в командах 3 и 4 — только разработчики. Давайте распределим сначала сотрудников по их должности, для этого добавим выражение PARTITION BY:
SELECT
e.Name,
e.Position,
e.TeamName,
NTILE(4) OVER(PARTITION BY e.Position ORDER BY e.Id) AS NewTeamId
FROM dbo.Employees e
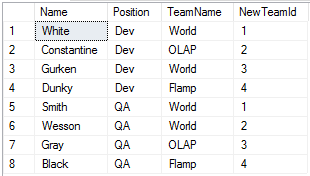
Теперь мы сначала распределили всех разработчиков по командам, а потом всех QA и получили, что в каждой команде есть разработчик и тестировщик, что как минимум лучше, чем прошлый вариант. Если учесть человеческий момент, и собрать в новых командах людей, которые работали в старых командах вместе, то необходимо изменить способ упорядочивания для функции NTILE:
SELECT
e.Name,
e.Position,
e.TeamName,
NTILE(4) OVER(PARTITION BY e.Position ORDER BY e.TeamName) AS NewTeamId
FROM dbo.Employees e
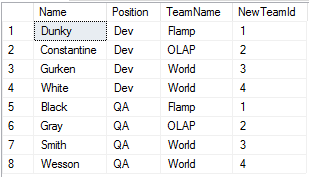
Теперь видим, что в новых командах работают знакомые люди.
LAG, LEAD
Недавно прошла аттестация и сотрудникам повысили зарплату. В таблице Assessments есть информация о зарплатах сотрудников по каждому году, руководству для анализа необходимо узнать сумму, на которую каждому сотруднику сделали повышение. Обычно это решается соединением таблицы на саму себя с использованием смещения, в нашем случае — по году:
SELECT
a.Name,
a.[Year],
a.Salary,
a2.Salary AS Salary2015,
a.Salary - a2.Salary AS Plus
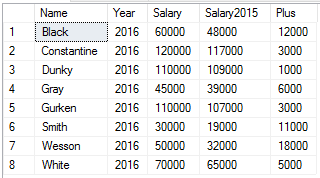
FROM dbo.Assessments a
INNER JOIN dbo.Assessments a2 ON a.Name = a2.Name AND a.Year = a2.Year + 1
Ожидаемый результат:
Меняя выражение Year + 1 мы можем посмотреть повышение за последние 1, 2 и т.д. лет. При этом, если мы хотим одним запросом узнать повышение за год и за 5 лет, то нам придется сделать 2 соединения соответственно.Функция LAG позволяет получить значение предыдущей строки, LEAD — следующей. При этом, как параметр можно указать, на сколько строк нужно «вернуться» назад или вперед:
SELECT
a.Name,
a.[Year],
a.Salary,
LAG(a.Salary, 1, NULL) OVER (PARTITION BY a.Name ORDER BY a.[Year]) AS Salary2015,
a.Salary - LAG(a.Salary, 1, 0) OVER (PARTITION BY a.Name ORDER BY a.[Year]) AS Plus
FROM dbo.Assessments a
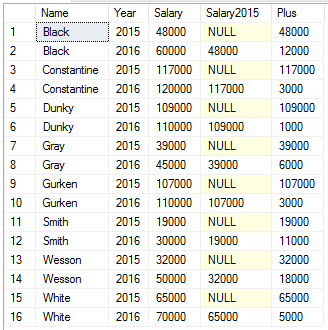
И так, мы указали в функции LAG, что нужно «вернуться» на 1 строку назад в отсортированном наборе. Мы разделили наш набор по сотрудникам и отсортировали по году. Естественно, для первой строки не будет предыдущего набора (а для последней — следующего), поэтому третий параметр функции как раз определяет это отсутствующее значение.Мы получили необходимый результат и еще строки за 2015 год. Мы не можем их отфильтровать в этом же запросе, т.к. это повлияет на результат выполнения функции LAG (для строк только из 2016 года нет предыдущего значения года, очевидно), поэтому обернем это еще в один запрос и отфильтруем:
SELECT
*
FROM
(
SELECT
a.Name,
a.[Year],
a.Salary,
LAG(a.Salary, 1, NULL) OVER (PARTITION BY a.Name ORDER BY a.[Year]) AS Salary2015,
a.Salary - LAG(a.Salary, 1, 0) OVER (PARTITION BY a.Name ORDER BY a.[Year]) AS Plus
FROM dbo.Assessments a
) AS t
WHERE t.[Year] = 2016
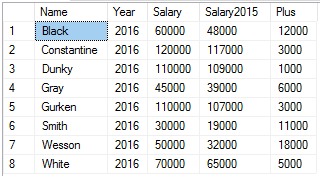
И мы получили аналогичный результат. Здесь преимущество функции LAG над соединением в том, что мы можем легко сравнивать текущее значение со значением 1, 2, 3 или 5 лет назад просто поменяв одно значение параметра, при этом, можем все это вычислить одним запросом, который будет исполнен за один проход по таблице без соединений. Функция LEAD работает аналогично, но выбирает следующие строки.
PERCENTILE_CONT, PERCENTILE_DISC
Напоследок, пара аналитических функций для подсчета процентилей и медиан в частности.Процентиль довольно часто используется для анализа каких-либо параметров, поэтому логично, что эти функции присутствуют в MSSQL.Давайте посчитаем медиану зарплат в нашей компании (напомню, что медиана — такое число, что ровно половина выборки имеет значение меньше этого набора, а другая половина — больше):
SELECT
e.Name,
e.Salary,
PERCENTILE_CONT(0.5) WITHIN GROUP (ORDER BY e.Salary) OVER () AS Median,
e.Position,
PERCENTILE_CONT(0.5) WITHIN GROUP (ORDER BY e.Salary) OVER (PARTITION BY e.Position) AS MedianInPosition,
e.Department,
PERCENTILE_CONT(0.5) WITHIN GROUP (ORDER BY e.Salary) OVER (PARTITION BY e.Department) AS MedianInDepartment,
e.TeamName,
PERCENTILE_CONT(0.5) WITHIN GROUP (ORDER BY e.Salary) OVER (PARTITION BY e.TeamName) AS MedianInTeam
FROM dbo.Employees e
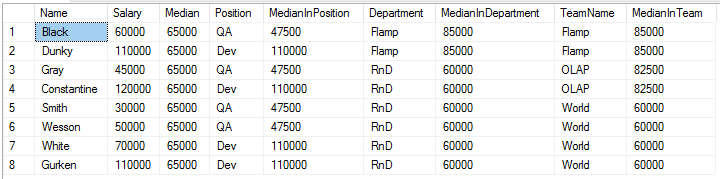
Итак, одним запросом мы узнали, что наш мистер Black получает зарплату на 5000 меньше медианы по компании, но на 12500 больше чем медиана среди QA! Делая различные разделения в выражении OVER мы можем получить показатели по определенному подмножеству, или оставить это выражение пустым, что бы получить результаты по всему набору.В чем отличия функций PERCENTILE_CONT и PERCENTILE_DISC? PERCENTILE_CONT возвращает результат из непрерывного множества значений. Заметьте, что значение медианы 65000 не является чей-либо зарплатой в компании — это статистическое значение. Если же мы хотим использовать как медиану (или процентиль, в общем случае) значение из нашего набора, то необходимо использовать функцию PERCENTILE_DISC:
SELECT
e.Name,
e.Salary,
PERCENTILE_DISC(0.5) WITHIN GROUP (ORDER BY e.Salary) OVER () AS Median,
e.Position,
PERCENTILE_DISC(0.5) WITHIN GROUP (ORDER BY e.Salary) OVER (PARTITION BY e.Position) AS MedianInPosition,
e.Department,
PERCENTILE_DISC(0.5) WITHIN GROUP (ORDER BY e.Salary) OVER (PARTITION BY e.Department) AS MedianInDepartment,
e.TeamName,
PERCENTILE_DISC(0.5) WITHIN GROUP (ORDER BY e.Salary) OVER (PARTITION BY e.TeamName) AS MedianInTeam
FROM dbo.Employees e
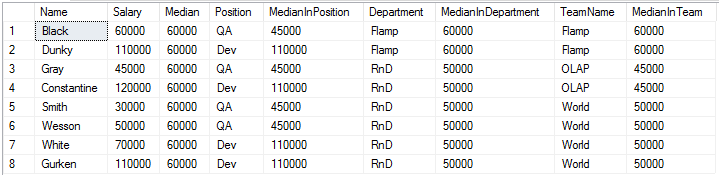
Теперь в качестве результата используется одно из значений исходного набора.