Итак, с Elasticsearch, гибридом гугла и NoSQL базы данных, мы разобрались, самое время перейти к следующей букве ELK стэка от Elastic — Logstash.
Что такое Logstash
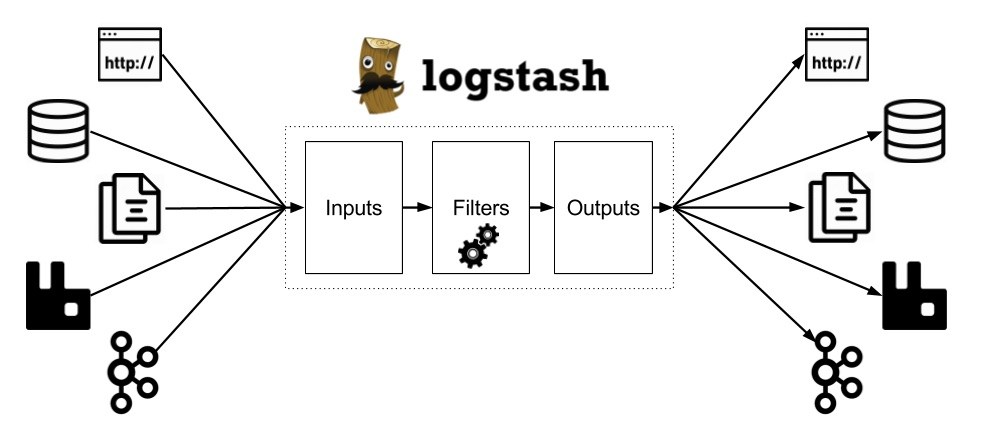
Logstash — это конвейер обработки данных, который получает сырые данные (например, логи) из одного или нескольких источников, обрабатывает их и улучшает фильтрами, а затем отправляет результат одному или нескольким получателям. Elastic рекомендует в качестве получателя использовать Elasticsearch, но на самом деле можно использовать всё, что душе угодно: STDOUT, WebSocket, обычные сокеты, очереди сообщений — выбор огромный.
Установка
Если на хосте установлена Java, то можно просто скачать архив, распаковать его и запустить bin/logstash -f logstash.conf. Для запуска, правда, понадобится файл конфигурации, но для простейших примеров сойдёт что-нибудь вроде input {STDIN {}} output {STDOUT {}}.
Да, любителям контейнеров можно не утруждать себя скачкой архивов и использовать заводской Docker образ:
|
1
|
docker run —it logstash —e ‘input { stdin { } } output { stdout { } }’
|
Конфигурация, кодеки и «Hello World!»
Итак, архив скачан, что дальше? Как я упомянул выше, для запуска Logstash нужен файл конфигурации. Например, такой:
|
1
2
3
4
5
6
7
|
input {
stdin { }
}
output {
stdout { }
}
|
С ним Logstash будет брать данные из консоли, делать свою магию по-умолчанию, и выдавать результат назад в консоль.
Hello world
Я нашёл у себя на хосте немного логов от Apache2, так что почему бы не скормить их Logstash и не посмотреть, что из этого получится?
|
1
2
3
4
5
|
$ bin/logstash —e ‘input { stdin { } } output { stdout {} }’
#….
#05:38:59.948 [Api Webserver] INFO logstash.agent — Successfully started Logstash API endpoint {:port=>9600}
$ 172.17.0.1 — — [11/Feb/2017:04:41:22 +0000] «GET / HTTP/1.1» 200 3525 «-« «Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36»
#2017-02-13T05:39:12.684Z 269a27a16415 172.17.0.1 — — [11/Feb/2017:04:41:22 +0000] «GET / HTTP/1.1» 200 3525 «-» «Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36»
|
А получится много скучного текста. Logstash запустился, ему на вход вошла строка (4) с логом от Apache2, и она тут же пошла на выход с двумя новыми полями: временной меткой 2017-02-13T05:39:12.684Z и именем хоста 269a27a16415.
Кодеки
Но мы можем сделать вывод более читабельным. Logstash разрешает подключать ко вводу и выводу различные кодеки, которые форматируют поток текста, но не меняют его значение: добавляют отступы, архивируют, переводят в JSON, и т. п. В нашем случае мы можем использовать rubydebug для того, чтобы он отформатировал результат и показал, как именно Logstash «видит» данные, с которыми работает.
Конфигурация изменится совсем чуть-чуть, но результат станет намного человечнее:
|
1
2
3
4
5
6
|
...
output {
stdout {
codec => rubydebug
}
}
|
|
1
2
3
4
5
6
7
8
9
|
$ bin/logstash —e ‘input { stdin { } } output { stdout {codec => rubydebug} }’
#….
$ 172.17.0.1 — — [11/Feb/2017:04:41:22 +0000] «GET / HTTP/1.1» 200 3525 «-« «Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36»
# {
# «@timestamp» => 2017-02-12T05:24:21.270Z,
# «@version» => «1»,
# «host» => «31190306c1eb»,
# «message» => «172.17.0.1 — — [11/Feb/2017:04:41:22 +0000] \»GET / HTTP/1.1\» 200 3525 \»-\» \»Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36\»»
#}
|
Выводим результаты в Elasticsearch
Прежде чем двинуться дальше, стоит попробовать кое-что еще. В начале поста я сказал, что получателей данных может быть больше одного, и вообще мы можем писать результаты прямо в Elasticsearch. Это как раз тот случай, когда можно одним телодвижением подтвердить оба пункта.
Так уж оказалось, что в соседнем с Logstash контейнером у меня обосновался чистый Elasticsearch с айпишкой 172.19.0.2 и портом 9200. Чтобы подключить их друг к другу, нужно добавить всего пару строк в конфигурацию Logstash:
|
1
2
3
4
5
6
7
8
9
|
...
output {
stdout {
codec => rubydebug
}
elasticsearch {
hosts => [«172.19.0.2:9200»]
}
}
|
Теперь, если перезапустить Logstash и снова скормить ему Apache2 логов, в Elasticsearch появится кое что относительно интересное:
|
1
2
|
$ curl 172.19.0.1:9200/_cat/indices
#yellow open logstash-2017.02.12 rgQub7hsS0qq-FBj3HA2Rg 5 1 5 0 20.1kb 20.1kb
|
Во-первых, там появился новый индекс — logstash-2017.02.12. Во-вторых, запустив по этому индексу поиск, мы получим те же данные, что Logstash писал в STDOUT:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
$ curl 172.19.0.2:9200/logstash—2017.02.12/_search?pretty
#{
#…
# «hits» : [
# {
# «_index» : «logstash-2017.02.12»,
# «_type» : «logs»,
#…
# «_source» : {
# «@timestamp» : «2017-02-12T05:24:21.272Z»,
# «@version» : «1»,
# «host» : «31190306c1eb»,
# «message» : «172.17.0.1 — — [11/Feb/2017:04:41:22 +0000] \»GET /icons/ubuntu-logo.png HTTP/1.1\» 200 3623 \»https:://localhost/\» \»Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36\»»
#…
#}
|
Обрабатываем данные фильтрами
Пока Logstash справлялся с переправкой логов из точки А в точку Б, но не делал ничего для того, чтобы это данные стали хоть немного полезнее. Пришло время перемен. Кроме INPUT и OUTPUT в конфигурацию можно добавить FILTER, и вот там-то основная магия и начнётся.
Фильтры есть практически для всего: для агрегации метрик, маскировки чувствительных данных (вроде имён и номеров кредитных карт), добавления и удаления полей, нахождения IP по доменному имени, нахождения адреса по IP (держитесь, комментаторы!), и т.п. Но для нас хорошо бы начать с разбора строки Apache2 лога на её компоненты: IP, путь, user agent, и так далее. Фильтр, который занимается подобной работой, называется grok.
Grok
Grok — это основной инструмент для придания формы и структуры сполшному массиву текста. Работает это так: из предустановленных паттернов (IP, Number, Word, …) мы собираем строку-шаблон, которая по структуре повторяет ту, которую мы собираемся парсить. Например, если бы мои логи выглядели так:
|
1
2
|
0 127.0.0.1 /default.html
1 172.1.0.9 /
|
То я бы использовал такой шаблон для их разбора:
|
1
|
%{NUMBER:sequence} %{IP:client} ${URIPATHPARAM:target}
|
После обработки фильтром в логах появились бы новые поля: sequence, client и target. Те самые, которые указали в шаблоне.
Кроме элементарных паттернов вроде Number есть более сложные, которые описывают известные форматы логов целиком. Например, COMBINEDAPACHELOG описывает строку лога от Apache2. Вот её-то и можно попробовать в действии.
Новая конфигурация:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
input {
stdin {}
}
filter {
grok {
match => {
«message» => «%{COMBINEDAPACHELOG}»
}
}
}
output {
stdout {
codec => rubydebug
}
elasticsearch {
hosts => [«172.19.0.2:9200»]
}
}
|
И реакция Logstash на неё:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
{
«request» => «/»,
«agent» => «\»Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36\»»,
«auth» => «-«,
«ident» => «-«,
«verb» => «GET»,
«message» => «172.17.0.1 — — [11/Feb/2017:04:41:22 +0000] \»GET / HTTP/1.1\» 200 3525 \»-\» \»Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36\»»,
«referrer» => «\»-\»»,
«@timestamp» => 2017—02—12T05:41:18.687Z,
«response» => «200»,
«bytes» => «3525»,
«clientip» => «172.17.0.1»,
«@version» => «1»,
«host» => «31190306c1eb»,
«https:version» => «1.1»,
«timestamp» => «11/Feb/2017:04:41:22 +0000»
}
|
Сработало!
Дополнительные настройки GROK
Но обработку можно сделать еще лучше. В середине распаршеного лога затесалось поле message, которое дублирует всё, что мы только что распарсили. Хорошо бы его убрать. А в grok как раз есть дополнитальные настройки, одна из которых называется remove_field — как раз то, что нам нужно:
|
1
2
3
4
5
6
7
8
9
10
|
...
filter {
grok {
match => {
«message» => «%{COMBINEDAPACHELOG}»
}
remove_field => [ «message» ]
}
}
...
|
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
{
«request» => «/icons/ubuntu-logo.png»,
«agent» => «\»Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36\»»,
«auth» => «-«,
«ident» => «-«,
«verb» => «GET»,
«referrer» => «\»https:://localhost/\»»,
«@timestamp» => 2017—02—12T05:42:55.999Z,
«response» => «200»,
«bytes» => «3623»,
«clientip» => «172.17.0.1»,
«@version» => «1»,
«host» => «31190306c1eb»,
«https:version» => «1.1»,
«timestamp» => «11/Feb/2017:04:41:22 +0000»
}
|
Теперь результат просто прекрасен. Но мы можем сделать его ещё лучше.
geoip фильтр
Как следует из названия, geoip конвертирует IP адрес в координаты на карте и сопутствующий уличный адрес. Я заменил докеровскую айпишку одного из логов на свою внешнюю, включил geoip, и пропустил лог через Logstash еще раз:
|
1
2
3
4
5
6
7
8
9
10
|
...
filter {
grok {
...
}
geoip {
source => «clientip»
}
}
...
|
Ну разве это не прекрасно? Разве что телефона там моего нет:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
{
«request» => «/»,
«agent» => «\»Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/602.4.8 (KHTML, like Gecko) Version/10.0.3 Safari/602.4.8\»»,
«geoip» => {
«timezone» => «America/Toronto»,
«latitude» => 43.4464,
«continent_code» => «NA»,
«city_name» => «Oakville»,
«country_code2» => «CA»,
«country_name» => «Canada»,
«country_code3» => «CA»,
«region_name» => «Ontario»,
«location» => [
[0] —79.7593,
[1] 43.4464
],
«postal_code» => «L6M»,
«longitude» => —79.7593,
«region_code» => «ON»
},
«auth» => «-«,
«ident» => «-«,
...
|
geoip взял clientip поле, которое создал grok, и потом добавил несколько собственных полей. Мне даже не пришлось что-то выкачивать из ваших интернетов, чтобы это заработало.
А теперь, когда обработанные данные стекаются в Elasticsearch, мы можем использовать его поиск на полную катушку и начать задавать вопросы. Были ли посетители из Oakville?
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
$curl —s 172.19.0.2:9200/logstash—2017.02.12/_search?q=oakville | json_pp
#{
# …
# «hits» : [
# {
# «_id» : «AVow3zOW6fU5oFCNC7kH»,
# «_score» : 1.5404451,
# «_type» : «logs»,
# «_index» : «logstash-2017.02.12»,
# «_source» : {
# «geoip» : {
# …
# «city_name» : «Oakville»,
# },
# «response» : «200»,
# «@timestamp» : «2017-02-12T05:50:18.333Z»,
# «agent» : «\»Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/602.4.8 (KHTML, like Gecko) Version/10.0.3 Safari/602.4.8\»»,
# «request» : «/»,
#…
# }
# }
# ],
#…
|
Конечно были. А сколько HTTP ошибок было вчера? Пытался ли кто-нибудь зайти в админку блога без спроса? Сколько раз? Где он живёт?
Можно задавать много, много вопросов.
Итог
Logstash принадлежит к классу инструментов, которые не создают особого впечатления своим описанием, но немного влюбляют в себя после того, как с ними поиграешься. Стоит немного покомбинировать входы, выходы и фильтры, как становится дико интересно, что же ещё можно выцедить из своих данных.
Да, Logstash прекрасно работает с Elasticsearch, но и источниками и получателями данных может быть огромный набор сервисов, начиная с очередей сообщений и заканчивая TCP сокетами.
Но в этой картине вселенского счастья пропущен один элемент — пользовательский интерфейс. Что ни говори, анализировать логи из командной строки — не самое продуктивное занятие. Чтобы это исправить, в следующий раз мы посмотрим в сторону последнего компонента ELK стека — Kibana.