Эта статья — расширенная версия моего выступления на NginxConf 2017 6 сентября 2017 года. Являясь SRE в команде Dropbox Traffic, я отвечаю за нашу сеть Edge: ее надежность, производительность и эффективность. Dropbox edge network представляет собой прокси-уровень на основе nginx, предназначенный для обработки как транзакций с метаданными, чувствительными к задержкам, так и высокопроизводительных передач данных. Система, которая обрабатывает десятки гигабит в секунду при одновременной обработке десятков тысяч латентно-чувствительных транзакций, оптимизация эффективности/производительности по всему стеку прокси, от драйверов и прерываний, через TCP/IP и ядро, до библиотеки и приложения настройка уровня.
Disclaimer
В этой статье мы обсудим множество способов настройки веб-серверов и прокси-серверов. Пожалуйста, не принимайте на веру всё, что здесь написано. Ради научного метода применяйте их один за другим, измеряйте их эффект и решайте, действительно ли они полезны в вашей среде.
Это не статья о производительности Linux, хотя я и предоставлю множество ссылок на инструменты bcc, eBPF и perf. Это далеко не полный справочник по использованию инструментов профилирования производительности. Если вы хотите узнать о них больше, можете прочитать блог Брендана Грегга.
Статья также не является обзором производительности браузеров. Объясняя связанную с задержкой оптимизацию, я буду касаться производительности на стороне клиента,, но только слегка. Если вы хотите узнать больше, то должны прочитать «High Performance Browser Networking» от Ильи Григорика.
И наконец, это не подборка лучших практик настройки TLS. Хотя я буду упоминать библиотеки TLS и их настройки несколько раз, вы и ваша команда безопасности должны оценивать эффективность и последствия для безопасности каждого из них. Вы можете использовать Qualys SSL Test, чтобы проверить свою конечную точку на основе текущего набора лучших практи., А если хотите узнать больше о TLS в целом, подумайте о подписке на Feisty Duck Bulletproof TLS.
Структура статьи
Мы обсудим оптимизацию эффективности и производительности различных уровней системы, начиная с самых низких уровней, таких как аппаратные средства и драйверы. Эти настройки могут применяться практически для любого сервера с высокой нагрузкой. Затем мы перейдем к ядру linux и его стеку TCP/IP: это рычаги, которые вы хотите использовать в любом из ваших TCP-тяжелых приложений. Наконец, мы обсудим настройки библиотеки и приложений, которые в основном применимы к веб-серверам в целом и nginx в частности.
Аппаратные средства
CPU
Для хорошей асимметричной производительности RSA/EC вы ищете процессоры с поддержкой AVX2 (avx2 в /proc/cpuinfo) и желательно с большим числом арифметических аппаратных средств (bmi и adx). Для симметричных случаев вы должны искать AES-NI для шифров AES и AVX512 для ChaCha + Poly. Intel сравнивает производительностьразличных аппаратных поколений с OpenSSL 1.0.2, что иллюстрирует эффективность этих аппаратных разгрузок.
Для случаев, чувствительных к задержкам, таких как маршрутизация, NUMA выигрывает за счёт уменьшения узлов и отключается HT. Высокопроизводительные задачи улучшают работу с большим количеством ядер и получают выгоду от использования Hyper-Threading (если только они не связаны с кешем). Как правило, это не будет сильно беспокоить NUMA.
В частности, если вы идете по пути Intel, то ищете по крайней мере Haswell/Broadwell и в идеале процессоры Skylake. Если вы собираетесь работать с AMD, обратите внимание: впечатляющую производительность демонстрирует EPYC.
NIC
Здесь вы ищете не менее 10G, желательно даже 25G. Если отите выжать больше, чем через один сервер TLS, описанная здесь настройка будет недостаточной, и может потребоваться направить TLS на уровень ядра (например, FreeBSD, Linux).
На стороне программного обеспечения вы должны искать драйверы с открытым исходным кодом с активными списками рассылки и сообществами пользователей. Это будет очень важно, если (но скорее всего, когда) вы будете отлаживать проблемы, связанные с драйвером.
Memory
Эмпирическое правило здесь заключается в том, что для чувствительных к задержкам задач требуется более быстрая память, а для задач с пропускной способностью требуется больший объем памяти.
Hard Drive
Зависит от ваших требований к буферизации/кешированию. Но если вы собираетесь буферизовать или кешировать много данных, то должны перейти на твердотельные накопители. Некоторые могут использовать специализированную файловую систему для твердотельных накопителей (обычно лог-структурированную), но такие системы не всегда лучше, чем обычные ext4/xfs.
Во всяком случае будьте осторожны, чтобы не испортить накопитель, забыв включить TRIM или обновить прошивку.
Операционные системы: Низкий уровень
Прошивка
Вы должны сохранять прошивку в актуальном состоянии, чтобы избежать болезненных и длительных сеансов устранения неполадок. Постарайтесь следить за прошивками микропроцессора CPU, материнской платы, сетевых адаптеров и твердотельных накопителей. Это не означает, что вы всегда должны запускать последнии версии. Главное правило состоит в том, чтобы запустить вторую версию до последней прошивки, если только она не имеет критических ошибок, исправленных в последней версии, и не слишком сильно отстает.
Драйверы
Правила обновления здесь почти такие же, как и для прошивки. Попытайтесь использовать наиболее свежий драйвер. Одно из предостережений здесь состоит в том, чтобы попытаться отделить обновления ядра от обновлений драйверов, если это возможно. Например, вы можете упаковать свои драйверы с помощью DKMS или предварительно скомпилировать драйверы для всех используемых версий ядра. Таким образом, когда вы обновляете ядро и что-то не работает должным образом, будет ещё один способ устранения неполадок.
CPU
Ваши лучшие друзья здесь — репозиторий с ядром и инструменты, которые поставляются вместе с ним. В Ubuntu/Debian вы можете установить пакет linux-tools с набором утилит, но теперь мы используем только cpupower, turbostat и x86_energy_perf_policy. Чтобы проверить оптимизацию, связанную с ЦП, вы можете провести стресс-тесты программного обеспечения с помощью любимого инструмента для создания нагрузки (например, Yandex.Tank.) Вот последняя презентация с NginxConf от разработчиков о лучших методах загрузки nginx: «NGINX Тестирование производительности”.
cpupower
Использовать этот инструмент проще, чем /proc/. Чтобы просмотреть информацию о процессоре, нужно запустить:
$ cpupower frequency-info
...
driver: intel_pstate
...
available cpufreq governors: performance powersave
...
The governor "performance" may decide which speed to use
...
boost state support:
Supported: yes
Active: yesУбедитесь, что Turbo Boost включен. А для процессоров Intel убедитесь, что вы работаете с intel_pstate, а не с acpi-cpufreq или даже pcc-cpufreq. Если вы все еще используете acpi-cpufreq, следует обновить ядро. Если это невозможно, убедитесь, что используете регулятор производительности. При работе с intel_pstate даже регулятор poweraves должен работать хорошо, но нужно проверить его самостоятельно.
Чтобы узнать, что на самом деле происходит с процессором, вы можете использовать turbostat для непосредственного просмотра MSR процессора и получения информации о мощности, частоте и состоянии ожидания:
# turbostat --debug -P
... Avg_MHz Busy% ... CPU%c1 CPU%c3 CPU%c6 ... Pkg%pc2 Pkg%pc3 Pkg%pc6 …Здесь вы можете увидеть фактическую частоту процессора (да, /proc/cpuinfo лжет вам) и состояния простоя ядра/пакета.
Если даже с драйвером intel_pstate процессор проводит больше времени за простоем, чем вы думаете, можно:
- Установить регулятор на
performance. - Установить
x86_energy_perf_policy.
Для очень важных критических задач можно:
- Использовать интерфейс
/dev/cpu_dma_latency. - Для трафика UDP используйте busy-polling.
Больше об управлении питанием процессоров в целом и P-состояниях можно узнать из презентации Intel OpenSource Technology Center «Балансировка мощности и производительности в ядре Linux» от LinuxCon Europe 2015.
CPU Affinity
Дополнительно уменьшить время ожидания можно, применяя аффинность к процессору для каждого потока/процесса. Например, nginx имеет директиву worker_cpu_affinity, которая может автоматически привязывать процесс каждого веб-сервера к его собственному ядру. Это должно устранить миграцию процессора, уменьшить промахи в кеше и ошибки страниц и немного увеличить количество инструкций за цикл. Все это проверяется с помощью perf stat.
К сожалению, включение аффинности также может отрицательно повлиять на производительность за счет увеличения времени, затрачиваемого процессом на ожидание свободного процессора. Это можно контролировать, запустив runqlat на одном из воркеров nginx:
usecs : count distribution
0 -> 1 : 819 | |
2 -> 3 : 58888 |****************************** |
4 -> 7 : 77984 |****************************************|
8 -> 15 : 10529 |***** |
16 -> 31 : 4853 |** |
...
4096 -> 8191 : 34 | |
8192 -> 16383 : 39 | |
16384 -> 32767 : 17 | |Если вы видите многомиллисекундные задержки, значит, на серверах, вероятно, слишком много других процессов, кроме самого nginx, а аффинность будет увеличивать латентность, а не уменьшать ее.
Память
Все mm/tunings, как правило, очень специфичны для работы. Есть всего несколько рекомендаций:
- Установите THP для
madviseи включите их только тогда, когда уверены в их полезности, иначе в стремлении повысить 20-процентную латентность вы можете добиться замедления на порядок. - Если вы используете только один узел NUMA, то должны установить
vm.zone_reclaim_modeравным 0. ## NUMA.
Современные процессоры на самом деле представляют собой несколько отдельных процессорных матриц, соединенных очень быстрым межсоединением и разделяющих различные ресурсы, начиная с кеша L1 на ядрах HT через кеш L3 внутри пакета до каналов памяти и PCIe в сокетах. Это в основном то, чем является NUMA: несколько блоков выполнения и хранения с быстрым соединением.
Для всестороннего обзора NUMA и его последствий вы можете обратиться к «NUMA Deep Dive Series» от Фрэнка Деннемана.
Чтобы правильно использовать NUMA, нужно обрабатывать каждый numa-узел как отдельный сервер, для чего следует сначала проверить топологию, которую можно выполнить с помощью numactl --hardware:
$ numactl --hardware
available: 4 nodes (0-3)
node 0 cpus: 0 1 2 3 16 17 18 19
node 0 size: 32149 MB
node 1 cpus: 4 5 6 7 20 21 22 23
node 1 size: 32213 MB
node 2 cpus: 8 9 10 11 24 25 26 27
node 2 size: 0 MB
node 3 cpus: 12 13 14 15 28 29 30 31
node 3 size: 0 MB
node distances:
node 0 1 2 3
0: 10 16 16 16
1: 16 10 16 16
2: 16 16 10 16
3: 16 16 16 10На что обратить внимание:
- количество узлов;
- объем памяти для каждого узла;
- количество процессоров для каждого узла;
- расстояние между узлами.
Это плохой пример, поскольку в нём 4 узла, а также узлы без привязки к памяти. Невозможно рассматривать каждый узел здесь как отдельный сервер, не жертвуя половиной ядер в системе.
Мы можем проверить это с помощью numastat:
$ numastat -n -c
Node 0 Node 1 Node 2 Node 3 Total
-------- -------- ------ ------ --------
Numa_Hit 26833500 11885723 0 0 38719223
Numa_Miss 18672 8561876 0 0 8580548
Numa_Foreign 8561876 18672 0 0 8580548
Interleave_Hit 392066 553771 0 0 945836
Local_Node 8222745 11507968 0 0 19730712
Other_Node 18629427 8939632 0 0 27569060Вы также можете запросить numastat для вывода статистики использования памяти для каждого узла в формате /proc/meminfo:
$ numastat -m -c
Node 0 Node 1 Node 2 Node 3 Total
------ ------ ------ ------ -----
MemTotal 32150 32214 0 0 64363
MemFree 462 5793 0 0 6255
MemUsed 31688 26421 0 0 58109
Active 16021 8588 0 0 24608
Inactive 13436 16121 0 0 29557
Active(anon) 1193 970 0 0 2163
Inactive(anon) 121 108 0 0 229
Active(file) 14828 7618 0 0 22446
Inactive(file) 13315 16013 0 0 29327
...
FilePages 28498 23957 0 0 52454
Mapped 131 130 0 0 261
AnonPages 962 757 0 0 1718
Shmem 355 323 0 0 678
KernelStack 10 5 0 0 16Теперь рассмотрим пример более простой топологии.
$ numactl --hardware
available: 2 nodes (0-1)
node 0 cpus: 0 1 2 3 4 5 6 7 16 17 18 19 20 21 22 23
node 0 size: 46967 MB
node 1 cpus: 8 9 10 11 12 13 14 15 24 25 26 27 28 29 30 31
node 1 size: 48355 MBПоскольку узлы в основном симметричны, мы можем привязать экземпляр приложения к каждому узлу NUMA с помощью numactl --cpunodebind = X --membind = X, а затем выставить его на другом порте. Таким образом вы можете получить лучшую пропускную способность, используя оба узла и лучшую задержку и при этом сохраняя память.
Вы можете проверить эффективность размещения NUMA за счет латентности операций с памятью, например, с использованием функциональности bcc для измерения латентности операции с большой памятью (например, memmove).
Наблюдать эффективность на стороне ядра можно, используя perf stat и рассматривая соответствующие события памяти и планировщика:
# perf stat -e sched:sched_stick_numa,sched:sched_move_numa,sched:sched_swap_numa,migrate:mm_migrate_pages,minor-faults -p PID
...
1 sched:sched_stick_numa
3 sched:sched_move_numa
41 sched:sched_swap_numa
5,239 migrate:mm_migrate_pages
50,161 minor-faultsПоследний бит NUMA-связанных оптимизаций для рабочих нагрузок, основанных на сети, исходит из того факта, что сетевая карта является устройством PCIe и каждое устройство привязано к своему NUMA-узлу. Поэтому некоторые процессоры будут иметь более низкую задержку при взаимодействии с сетью. Мы обсудим оптимизацию, которая может быть применена, после обсуждения NIC → CPU Affinity. Теперь же давайте переключимся на PCI-Express.
PCIe
Обычно не нужно слишком углубляться в поиск неисправностей PCIe, если нет какой-либо аппаратной неисправности. Поэтому не стоит зря тратить усилия, просто сосредоточьтесь на «ширине канала», «скорости соединения» и, возможно, оповещениях RxErr/BadTLP для устройств PCIe. Это должно сэкономить время поиска неисправностей из-за сбоев в работе аппаратного обеспечения или отказа PCIe. Вы можете использовать lspci для этого:
# lspci -s 0a:00.0 -vvv
...
LnkCap: Port #0, Speed 8GT/s, Width x8, ASPM L1, Exit Latency L0s <2us, L1 <16us
LnkSta: Speed 8GT/s, Width x8, TrErr- Train- SlotClk+ DLActive- BWMgmt- ABWMgmt-
...
Capabilities: [100 v2] Advanced Error Reporting
UESta: DLP- SDES- TLP- FCP- CmpltTO- CmpltAbrt- ...
UEMsk: DLP- SDES- TLP- FCP- CmpltTO- CmpltAbrt- ...
UESvrt: DLP+ SDES+ TLP- FCP+ CmpltTO- CmpltAbrt- ...
CESta: RxErr- BadTLP- BadDLLP- Rollover- Timeout- NonFatalErr-
CEMsk: RxErr- BadTLP- BadDLLP- Rollover- Timeout- NonFatalErr+PCIe может стать узким местом, например, если у вас есть несколько высокоскоростных устройств, конкурирующих за пропускную способность (когда вы объединяете быструю сеть с быстрым хранилищем). Поэтому может потребоваться физически разделить устройства PCIe через процессоры, чтобы получить максимальную пропускную способность.

Также см. статью «Общие сведения о конфигурации PCIe для максимальной производительности» на веб-сайте Mellanox. Статья немного углубляется в конфигурацию PCIe, что может быть полезно на более высоких скоростях, если наблюдается потеря пакетов между картой и ОС.
Intel предполагает, что иногда управление питанием PCIe (ASPM) может привести к более высоким задержкам и, следовательно, к более высокой потере пакетов. Вы можете отключить его, добавив pcie_aspm=off в ядро cmdline.
NIC
Прежде чем мы начнем, стоит упомянуть, что у Intel и Mellanox есть собственные руководства по настройке производительности, и независимо от того, какого производителя вы выбрали, полезно прочитать оба. Также драйверы обычно поставляются с README и набором полезных утилит.
Следующее место для проверки рекомендаций — руководство операционной системы, например. Red Hat Enterprise Linux Network Performance Tuning Guide, в котором объясняется большинство упомянутых ниже оптимизаций, и даже больше.
Cloudflare также разместил хорошую статью о настройке части сетевого стека в своем блоге.
При оптимизации NIC ethtool станет вашим лучшим другом.
Небольшая заметка здесь: если вы используете новое ядро (и вам действительно нужно!), то должны столкнуться с некоторыми частями пользовательского пространства. Например, для сетевых операций, вероятно, нужны более новые версии: ethtool, iproute2 и, возможно, iptables/nftables.
Ценное понимание того, что происходит с вашей сетевой картой, можно получить через ethtool -S:
$ ethtool -S eth0 | egrep 'miss|over|drop|lost|fifo'
rx_dropped: 0
tx_dropped: 0
port.rx_dropped: 0
port.tx_dropped_link_down: 0
port.rx_oversize: 0
port.arq_overflows: 0Проконсультируйтесь с производителем вашего сетевого адаптера, чтобы получить подробное описание характеристик. Например, у Mellanox есть для этого специальная страница wiki.
С точки зрения ядра вы будете смотреть на /proc/interrupts, /proc/softirqs и /proc/net/softnet_stat. Здесь есть два полезных инструментальных средства: hardirqs и softirqs. Ваша цель в оптимизации сети – настраивать систему до тех пор, пока не достигнете минимального использования ЦП при отсутствии потери пакетов.
Прерывание близости
Тюнинг здесь обычно начинается с распространения прерываний между процессорами. Как конкретно вы должны это делать, зависит от рабочей нагрузки.
- Для максимальной пропускной способности можно распространять прерывания по всем NUMA-узлам в системе.
- Чтобы свести к минимуму задержку, можно ограничить прерывания одним узлом NUMA. Для этого может потребоваться уменьшить количество очередей, чтобы они вписывались в один узел (обычно это означает сокращение их числа вдвое с помощью
ethtool -L).
Поставщики обычно предоставляют сценарии этого, например. Intel имеет set_irq_affinity.
Размер кольцевых буферов
Сетевые карты должны обмениваться информацией с ядром. Обычно обмен производится текущим/максимальным размером кольца, просматриваемым с помощью ethtool -g:
$ ethtool -g eth0
Ring parameters for eth0:
Pre-set maximums:
RX: 4096
TX: 4096
Current hardware settings:
RX: 4096
TX: 4096Вы можете настроить эти значения в заранее заданных максимумах с помощью -G. Как правило, здесь больше — лучше (особенно если вы используете коалесценцию прерываний), так как это даст вам больше защиты от всплесков, поэтому уменьшит количество отброшенных пакетов из-за отсутствия буферного пространства/пропущенных прерываний. Но есть пара предостережений:
- В старых ядрах или драйверах без поддержки BQL высокие значения могут относиться к более высокому буферному слою на стороне tx.
- Большие буферы также увеличивают давление в кеше, поэтому, если вы столкнулись с такой проблемой, попробуйте снизить размер буфера.
Коалесценция
Коалесценция прерываний позволяет задерживать уведомление ядра о новых событиях путем объединения нескольких событий в одно прерывание. Текущую настройку можно просмотреть с помощью ethtool -c:
$ ethtool -c eth0
Coalesce parameters for eth0:
...
rx-usecs: 50
tx-usecs: 50Вы можете либо взаимодействовать со статическими ограничениями, жестко ограничивая максимальное количество прерываний в секунду на ядро, либо зависеть от аппаратного обеспечения, чтобы автоматически регулировать скорость прерывания на основе пропускной способности.
Включение коалесценции (с -C) приведет к увеличению задержки и, возможно, к потере пакетов, поэтому вы можно не включать коалесценцию для сохранения чувствительности к задержкам. С другой стороны, полное отключение может привести к прерыванию троттлинга и, следовательно, к ограничению производительности.
Разгрузки
Современные сетевые карты относительно умны и могут либо разгружать большую часть работы аппаратным средствам, либо эмулировать эту разгрузку в самих драйверах.
Все возможные разгрузки можно получить с помощью ethtool -k:
$ ethtool -k eth0
Features for eth0:
...
tcp-segmentation-offload: on
generic-segmentation-offload: on
generic-receive-offload: on
large-receive-offload: off [fixed]На выходе все неперестраиваемые разгрузки помечены суффиксом [fixed].
О разгрузках можно сказать многое, но вот некоторые эмпирические правила:
- не включайте LRO, лучше используйте GRO;
- будьте осторожны с TSO, поскольку он сильно зависит от качества ваших драйверов/прошивки;
- не включайте TSO/GSO в старых ядрах, так как это может привести к избыточной сетевой буферизации.
Управление пакетами
Все современные сетевые адаптеры оптимизированы для многоядерного оборудования, поэтому они внутренне разделяют пакеты на виртуальные очереди, обычно по одной на процессор. Когда разделение производится на оборудовании, это называется RSS. Когда ОС отвечает за загрузку пакетов по процессорам, он называется RPS (с его TX-аналогом, называемым XPS). Когда ОС также пытается быть умной и управлять потоками к процессорам, которые в настоящее время обрабатывают этот сокет, он называется RFS. Когда это делает оборудование, оно называется ускоренным RFS (для краткости — aRFS для краткости.
Вот несколько лучших практик из нашего производства:
- Если вы используете новое оборудование 25G +, у него, вероятно, будет достаточно очередей и огромная косвенная таблица, чтобы иметь возможность выполнять RSS по всем ядрам. Некоторые более старые сетевые адаптеры имеют ограничения только на использование первых 16 процессоров.
- Вы можете попробовать включить RPS, если:
1) у вас больше процессоров, чем аппаратных очередей, и вы хотите пожертвовать латентностью для пропускной способности;
2) вы используете внутреннее туннелирование (например, GRE / IPinIP), поэтому NIC не может использовать RSS. - Не включайте RPS, если ваш процессор довольно старый и не имеет x2APIC.
- Как правило, привязка каждого процессора к собственной очереди TX через XPS — хорошая идея.
- Эффективность RFS сильно зависит от вашей рабочей нагрузки и от того, применяете ли вы к ней CPU.
Операционные системы: сетевой стек
Существует множество книг, видеороликов и руководств по настройке сетевого стека Linux. И, к сожалению, тонны вариантов настройки sysctl.con, которые идут с ними. Несмотря на то что последние версии ядра не требуют такой же настройки, как и 10 лет назад, и большинство новых функций TCP/IP включены и хорошо настроены по умолчанию, люди по-прежнему копируют свои старые sysctls.conf, которые использовали для настройки ядер 2.6.18/2.6.32.
Чтобы проверить эффективность сетевых оптимизаций, необходимы:
- общесистемные показатели TCP (соберите их через
/proc/net/snmpи/proc/net/netstat); - совокупные показатели для каждого соединения, полученные либо из
ss -n -extended-info, либо из вызоваgetsockopt(TCP_INFO)/getsockopt(TCP_CC_INFO)внутривеб-сервера; - tcptrace (1) из выборочных потоков TCP;
- анализ показателей RUM из приложения/браузера.
Для источников информации об оптимизации сети я чаще выбираю конференции CDN-folks, поскольку они обычно знают, что делают. Например, Fastly on LinuxCon Australia. Прослушивание того, что разработчики ядра Linux говорят о сети, также довольно полезно. Например, переговоры netdevconf и NETCONF transcripts.
Стоит подчеркнуть хорошее глубокое погружение в сетевой стек Linux в PackageCloud, тем более что они акцентируют внимание на мониторинге, а не на слепой настройке:
- Monitoring and Tuning the Linux Networking Stack: Receiving Data
- Monitoring and Tuning the Linux Networking Stack: Sending Data
Прежде чем начать, позвольте мне сказать еще раз: обновите ядро! Есть тонны новых улучшений сетевого стека, и я даже не говорю о IW10. Я говорю о новых крутых штуках, например: TSO autosizing, FQ, pacing, TLP и RACK, но об этом позже. В качестве бонуса при обновлении до нового ядра вы получите множество улучшений масштабируемости, например: removed routing cache, lockless listen sockets, SO_REUSEPORT и многие другие.
Обзор
Из недавних сетевых публикаций Linux выделяется «Making Linux TCP Fast». Ему удается консолидировать многолетние улучшения ядра Linux на 4 страницах, разбив стек TCP на стороне отправителя Linux на функциональные части:
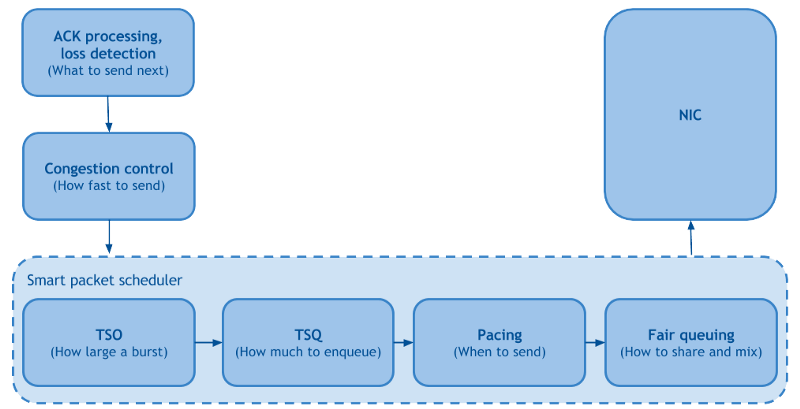
Fair Queueing и Pacing
Fair Queueing отвечает за улучшение справедливости и сокращение блокировки строк между потоками TCP, что положительно влияет на скорость сброса пакетов. Pacing планирует пакеты со скоростью, установленной посредством контроля перегрузки, равномерно распределяя по времени, что еще больше снижает потери пакетов и увеличивает пропускную способность.
В качестве побочного примечания: Fair Queueing и Pacing доступны в Linux через fq qdisc. Некоторые могут знать, что это требование для BBR (но не более того), но оба они могут использоваться с CUBIC, что приводит к снижению потерь пакетов на 15-20% и, следовательно, к повышению пропускной способности на основе потерь.
TSO autosizing и TSQ
Оба они отвечают за ограничение буферизации внутри стека TCP и, следовательно, уменьшают задержку, не жертвуя пропускной способностью.
Контроль перегрузок
CC-алгоритмы являются огромной темой сами по себе, и в последние годы вокруг них было много активности. Некоторые из этих действий были кодифицированы как tcp_cdg (CAIA), tcp_nv(Facebook) и tcp_bbr (Google). Мы не будем слишком подробно обсуждать их внутреннюю работу, просто скажем, что все они больше полагаются на задержку, чем падение пакетов для индикатора перегрузки.
BBR, возможно, является наиболее хорошо документированным, проверенным и практичным из всех новых элементов контроля перегрузки. Основная идея состоит в том, чтобы создать модель сетевого пути на основе скорости доставки пакетов, а затем выполнить контуры управления, чтобы максимизировать пропускную способность при минимизации rtt. Это именно то, что мы ищем в нашем стеке прокси.
Предварительные данные из экспериментов BBR на наших пограничных PoP показывают увеличение скорости загрузки файлов:
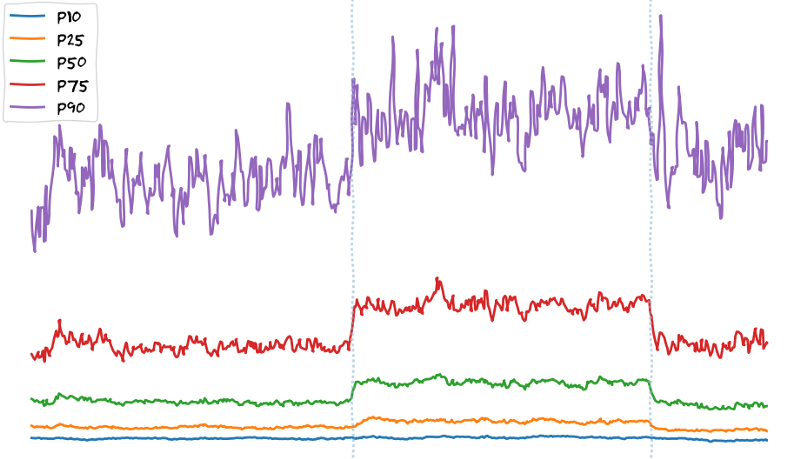
6-часовой эксперимент TCP BBR в Токио PoP: ось x — время, ось y — скорость загрузки клиента
Здесь хочу подчеркнуть, что мы наблюдаем увеличение скорости по всем процентилям. Это не относится к изменениям бэкэнда. Обычно они используют только пользователей p90+ (которые имеют самую быструю интернет-связь), так как мы считаем, что все остальные уже ограничены полосой пропускания. Настройка на сетевом уровне, такая как изменение контроля перегрузки или включение FQ/pacing, показывает, что пользователи не ограничиваются пропускной способностью, но, если можно так выразиться, они «ограничены TCP».
Если вы хотите узнать больше о BBR, у APNIC есть хороший обзор BBRна начальном уровне (и его сравнение с контрольными системами перегрузок на основе потерь). Для получения более подробной информации о BBR вы, вероятно, захотите прочитать архивы списков рассылки bbr-dev(там есть тонна полезных ссылок, прикрепленных вверху). Для людей, заинтересованных в контроле перегрузки в целом, может быть интересно следить за деятельностью исследовательской группы Internet Congestion Control.
Обработка ACK и обнаружение потерь
Но достаточно о контроле над перегрузкой, давайте поговорим об обнаружении потерь. Здесь снова поможет последнее ядро. Новые эвристики, такие как TLP и RACK, постоянно добавляются в TCP, в то время как старые вещи, такие как FACK и ER, удаляются. После добавления они включены по умолчанию, поэтому вам не нужно настраивать системные настройки после обновления.
Распределение приоритетов в пользовательских пространствах и HOL
API-интерфейсы сокетов пользовательского пространства обеспечивают неявную буферизацию и не могут повторно упорядочивать куски после их отправки, поэтому в мультиплексированных сценариях (например, HTTP/2) это может привести к блокировке HOL и инверсии приоритетов h2. Параметр сокета TCP_NOTSENT_LOWAT (и соответствующий net.ipv4.tcp_notsent_lowat sysctl) был разработан для решения этой проблемы путем установки порога, при котором сокет считает себя доступным для записи (т.е. Epoll будет лгать вашему приложению). Это может решить проблемы с приоритетом HTTP/2, но это также может потенциально отрицательно повлиять на пропускную способность.
Sysctl
Начнем с параметров, которые не нужно трогать:
net.ipv4.tcp_tw_recycle=1– не используйте: он уже был сломан для пользователей за NAT, но если вы обновите свое ядро, оно будет сломан для всех.net.ipv4.tcp_timestamps=0– не отключайте, если не знаете всех побочных эффектов и. Например, один из неочевидных побочных эффектов заключается в том, что вы потеряете параметры масштабирования окна и SACK в синхронизациях.
Что касается параметров, которые вы должны использовать:
net.ipv4.tcp_slow_start_after_idle=0– основная проблема с slowstart после простоя заключается в том, что «idle» определяется как один RTO, который слишком мал.net.ipv4.tcp_mtu_probing=1– полезно, если между вами и вашими клиентами есть черные дыры (скорее всего, есть).net.ipv4.tcp_rmem,net.ipv4.tcp_wmem– должен быть настроен на соответствие BDP; просто не забывайте, что больше не всегда лучше.echo 2> /sys/module/tcp_cubic/parameters/hystart_detect– если вы используете fq + куб, это может помочь с tcp_cubic, выходящим из медленного старта слишком рано.
Также стоит отметить, что есть проект RFC (хотя и не очень активный) от Daniel Stenberg — автора curl. Проект назван TCP Tuning для HTTP. Он пытается объединить в одном месте все системные настройки, которые могут быть полезны для HTTP.
Уровень приложения: средний уровень
Инструменты
Точно так же, как с ядром, очень важно иметь актуальное пользовательское пространство. Вы должны начать с обновления инструментов, например, можете собрать более новые версии perf, bcc и т. д.
Когда у вас есть новый инструмент, вы готовы правильно настроить систему и наблюдать за ее поведением. В рамках этой части сообщения мы будем в основном полагаться на профилирование on-cpu с perf top, плагинами на процессорах и гистограммами adhoc из bccfuncatency.
Системные библиотеки
Также стоит обновить системные библиотеки, например glibc, поскольку в противном случае вы можете упускать из виду недавние оптимизации в низкоуровневых функциях от -lc, -lm, -lrt и т. д.
Zlib
Обычно за сжатие отвечает веб-сервер. В зависимости от того, сколько данных идет через этот прокси-сервер, иногда вы можете видеть символы zlib в верхнем верхнем углу, например:
# perf top
...
8.88% nginx [.] longest_match
8.29% nginx [.] deflate_slow
1.90% nginx [.] compress_blockЕсть способы оптимизировать это на самых низких уровнях: Intel, Cloudflare, а также автономный проект zlib-ng имеют свои форки zlib, которые обеспечивают лучшую производительность за счет использования новых наборов инструкций.
Malloc
До сих пор при обсуждении оптимизации мы в основном ориентировались на процессоры, но давайте сменим тему и обсудим оптимизацию, связанную с памятью. Если вы используете много Lua с FFI или тяжелыми сторонними модулями, которые осуществляют собственное управление памятью, вы можете наблюдать увеличение использования памяти из-за фрагментации. Попробовать решить эту проблему можно, переключившись на jemalloc или tcmalloc.
Использование пользовательского malloc также имеет следующие преимущества:
- Разделение двоичного файла nginx из среды, в результате чего обновление версии glibc и миграция ОС будут меньше влиять на нее.
- Лучшие интроспекция, профилирование и статистика.
PCRE
Если вы используете множество сложных регулярных выражений в конфигурациях nginx или сильно полагаетесь на Lua, то можете увидеть символы, связанные с pcre, в perf top. Оптимизировать это можно, скомпилировав PCRE с JIT, а также включив его в nginx через pcre_jit on;.
Проверить результат оптимизации можно, посмотрев на флейм графики или используя funclatency:
# funclatency /srv/nginx-bazel/sbin/nginx:ngx_http_regex_exec -u
...
usecs : count distribution
0 -> 1 : 1159 |********** |
2 -> 3 : 4468 |****************************************|
4 -> 7 : 622 |***** |
8 -> 15 : 610 |***** |
16 -> 31 : 209 |* |
32 -> 63 : 91 | |Уровень приложения: высокий уровень
Чтобы проанализировать эффективность ваших оптимизаций на этом уровне, нужно будет собирать данные RUM. В браузерах вы можете использовать API-интерфейсы навигационного тайминга и API-интерфейсы ресурса. Вашими основными показателями являются TTFB и TTV/TTI. Наличие этих данных в легко читаемых форматах значительно упростит итерацию.
Сжатие
Сжатие в nginx начинается с файла mime.types, который определяет соответствие по умолчанию между расширением файла и типом ответа MIME. Затем нужно определить, какие типы вы хотите передать в компрессор, например, gzip_types. Если вы хотите получить полный список, можете использовать mime-db для автоматического создания mime.types и добавления тех, у кого есть .compressible == true для gzip_types.
При включении gzip будьте осторожны с двумя аспектами:
- Увеличение использования памяти. Это можно решить, ограничив
gzip_buffers. - Увеличение TTFB из-за буферизации. Это можно решить, используя [
gzip_no_buffer].
В качестве побочного примечания: сжатие HTTP не ограничивается исключительно gzip: nginx имеет сторонний модуль ngx_brotli, который может улучшить коэффициент сжатия на 30% по сравнению с gzip.
Что касается самих настроек сжатия, давайте обсудим два отдельных варианта использования: статические и динамические данные.
- Для статических данных вы можете архивировать максимальные коэффициенты сжатия, предварительно сжимая статические файлы в рамках процесса сборки.
- Для динамических данных необходимо тщательно сбалансировать полный кругооборот: время для сжатия данных + время для его передачи + время для распаковки на клиенте. Поэтому установка максимально возможного уровня сжатия может быть неразумной не только с точки зрения использования ЦП, но и с TTFB.
Буферизация
Буферизация внутри прокси-сервера может значительно повлиять на производительность веб-сервера, особенно в отношении задержки. Модуль прокси-сервера nginx имеет различные буферизирующие опции, которые настраиваются для каждого местоположения, каждый из которых полезен для своей цели. Вы можете отдельно управлять буферизацией в обоих направлениях через proxy_request_buffering и proxy_buffering. Если буферизация включена, верхний предел потребления памяти устанавливается client_body_buffer_size и proxy_buffers, после включения этих пороговых значений запрос/ответ буферизуется на диск. Для ответов это можно отключить, установив proxy_max_temp_file_size в 0.
Наиболее распространенными подходами к буферизации являются:
- Буферный запрос/ответ до некоторого порогового значения в памяти, а затем переполнение на диске. Если буферизация запроса включена, вы только отправляете запрос на бэкэнд после его полного получения и с буферизацией ответа, вы можете мгновенно освободить backend-поток, когда он будет готов дать ответ. Такой подход имеет преимущества улучшенной пропускной способности и защиты бэкэнда за счет увеличения задержки и использования памяти/io (хотя, если вы используете твердотельные накопители, можете не сильно беспокоиться об этом).
- Нет буферизации. Буферизация не может быть хорошим выбором для чувствительных к задержкам маршрутов, особенно тех, которые используют потоковое вещание. Для них вы можете отключить его, но теперь вашему бэкэнду необходимо иметь дело с медленными клиентами.
- Буферизация ответов, управляемая приложением через заголовок X-Accel-Buffering.
Какой бы путь вы ни выбрали, не забудьте проверить его влияние как на TTFB, так и на TTLB. Кроме того, как упоминалось ранее, буферизация может влиять на использование IO, следите за этим.
TLS
Теперь поговорим о высокоуровневых аспектах улучшений TLS и латентности, которые могут быть выполнены путем правильной настройки nginx. Большинство оптимизаций, о которых я расскажу, описаны в High Performance Browser Networking’s Optimizing for TLS и Making HTTPS Fast(er) на nginx.conf 2014. Тюнинг, упомянутый в этой части, повлияет как на производительность, так и на безопасность вашего веб-сервера. Если не уверены, обратитесь к руководству Mozilla’s Server Side TLS Guide или вашей группе безопасности.
Чтобы проверить результаты оптимизации, можете использовать:
Возобновление сессии
Администраторы баз данных любят говорить: «самый быстрый запрос — это тот, который вы никогда не делаете». То же самое касается TLS: вы можете уменьшить задержку одним RTT, если кешируете результат рукопожатия. Это можно сделать двумя способами:
- Во-первых, вы можете попросить клиента сохранить все параметры сеанса (подписанным и зашифрованным способом) и отправить его вам в течение следующего рукопожатия (аналогично файлу cookie). На стороне nginx это настраивается с помощью директивы
ssl_session_tickets. Операция не требует использования памяти на стороне сервера, но имеет ряд недостатков:
вам нужна инфраструктура для создания, поворота и распространения случайных ключей шифрования/подписи для сеансов TLS. Просто помните, что вы действительно не должны:
1) использовать контроль источника для хранения ключей тикета;
2) генерировать эти ключи из другого нефемерного материала, например, даты или сертификата.
PFS не будет использоваться для каждого сеанса, но на основе ключа для каждого тикета. Поэтому, если злоумышленник завладеет ключом тикета, он может потенциально дешифровать любой захваченный трафик на время прохождения тикета.
Ваше шифрование будет ограничено размером ключа тикета. Не имеет смысла использовать AES256, если вы используете 128-битный ключ билета. Nginx поддерживает 128-битные и 256-битные ключи тикета TLS.
Не все клиенты поддерживают ключи тикета (все современные браузеры поддерживают их). - Во-вторых, вы можете сохранить параметры сеанса TLS на сервере и предоставить клиенту только ссылку (идентификатор). Это делается с помощью директивы
ssl_session_cache.ssl_session_cacheимеет преимущество сохранения PFS между сеансами и значительно ограничивает поверхность атаки.
Хотя ключи тикетов имеют недостатки:
1) Они потребляют ~ 256 байт памяти за сеанс на сервере, что означает, что вы не можете хранить много слишком долго.
2) Они не могут быть легко разделены между серверами. Поэтому вам либо нужен loadbalancer, который отправит одного и того же клиента на тот же сервер, чтобы сохранить локальность кеша, либо нужно написать распределенное хранилище сеансов TLS поверх чего-то вродеngx_http_lua_module.
В качестве побочного примечания: если вы идете по пути использования подхода к сеансу, то стоит использовать 3 ключа вместо одного, например:
ssl_session_tickets on;
ssl_session_timeout 1h;
ssl_session_ticket_key /run/nginx-ephemeral/nginx_session_ticket_curr;
ssl_session_ticket_key /run/nginx-ephemeral/nginx_session_ticket_prev;
ssl_session_ticket_key /run/nginx-ephemeral/nginx_session_ticket_next;Вы всегда будете шифровать текущим ключом, но принимаете сеансы, зашифрованные как с помощью следующих, так и с помощью предыдущих ключей.
OCSP Stapling
Вы должны сшивать ваши ответы OCSP, так как в противном случае:
- Рукопожатие TLS может занять больше времени, потому что клиенту необходимо будет связаться с центром сертификации, чтобы получить статус OCSP.
- При сбое выборки OCSP может произойти ухудшение доступности.
- Вы можете нарушить конфиденциальность пользователей, так как их браузер свяжется со сторонней службой, указав, что они хотят подключиться к вашему сайту.
Чтобы сшивать ответ OCSP, вы можете периодически извлекать его из центра сертификации, распространять результат на свои веб-серверы и использовать с помощью директивы ssl_stapling_file:
ssl_stapling_file /var/cache/nginx/ocsp/www.der;Размер записи TLS
TLS разбивает данные на куски, называемые записями, которые вы не можете проверить и расшифровать, пока не получите его полностью. Вы можете измерить эту задержку как разницу между TTFB от сетевого стека и точек зрения приложения.
По умолчанию nginx использует 16 тыс. кусков, которые даже не вписываются в окно перегрузки IW10, поэтому требуется дополнительное обратное перемещение. nginx «из коробки» обеспечивает способ установки размеров записей с помощью директивы ssl_buffer_size:
- Чтобы оптимизировать nginx под низкую задержку, вы должны установить
ssl_buffer_sizeна что-то маленькое, например, 4k. Уменьшение его дальнейшего использования будет более дорогостоящим с точки зрения использования ЦП. - Чтобы оптимизировать высокую пропускную способность, вы должны оставить ее на уровне 16k.
Есть две проблемы со статической настройкой:
- Вам потребуется ручная настройка.
- Вы можете установить только
ssl_buffer_sizeна основе конфигурации per-nginx или на сервер. Поэтому, если у вас есть сервер со смешанными рабочими нагрузками с задержкой/пропускной способностью, вам придется скомпрометировать его.
Существует альтернативный подход: динамическая настройка размера записи. Для nginx есть от Cloudflare, который добавляет поддержку динамических размеров записей. Первоначальная настройка может быть проблематичной, но как только вы закончите, TLS работает очень хорошо.
Open file cache
Поскольку вызовы open(2) по сути являются блокирующими, а веб-серверы обычно открывают/считывают/закрывают файлы, может оказаться полезным иметь кеш открытых файлов. Вы можете определить, сколько выгоды можно получить, посмотрев на задержку функции ngx_open_cached_file:
# funclatency /srv/nginx-bazel/sbin/nginx:ngx_open_cached_file -u
usecs : count distribution
0 -> 1 : 10219 |****************************************|
2 -> 3 : 21 | |
4 -> 7 : 3 | |
8 -> 15 : 1 | |Если вы видите слишком много открытых вызовов или что некоторые занимают слишком много времени, вы можете посмотреть, как включить open_file_cache:
open_file_cache max=10000;
open_file_cache_min_uses 2;
open_file_cache_errors on;После включения open_file_cache вы обнаружите все промахи кеша, посмотрев на opensnoop и решив, нужно ли настраивать ограничения кеша:
# opensnoop -n nginx
PID COMM FD ERR PATH
69435 nginx 311 0 /srv/site/assets/serviceworker.js
69086 nginx 158 0 /srv/site/error/404.html
...Завершение
Все оптимизации, описанные в этой статье, являются локальными для одного веб-сервера. Некоторые улучшают масштабируемость и производительность. Другие релевантны, если вы хотите обслуживать запросы с минимальной задержкой или быстрее доставлять байты клиенту. Но, по нашему опыту, огромная часть видимой для пользователя производительности исходит из более высокоуровневых оптимизаций, которые влияют на поведение сети Dropbox Edge в целом, таких как технология входа/выхода трафика и интеллектуальная балансировка внутренней нагрузки. Эти проблемы находятся на грани знаний, и промышленность только начала к этому приближаться.