Проект OpenNMT (Open Source Neural Machine Translation) представляет из себя нейросеть, которую, в том числе, можно натренировать переводить тексты с одного человеческого языка на другой, например, с английского на русский или наоборот. Для этого её нужно натренировать на датесэте представляющим из себя параллельный корпус текстов на двух языках. Т.е. нужно 2 файла, в каждом из которых будут находиться одни и те же предложения, но на разных языках. Чем более дословный перевод в исходных данных — тем выше точность перевода нейросети.
Сразу скажу, что сделать универсальный переводчик текста с языка на язык будет крайне трудно, т.к. это потребует сотен или даже тысяч миллионов пар предложений с высоким качеством перевода и недели времени на тренировку модели. К тому же найти такой датасэт в открытых источниках будет не реально. А создавать его самому — крайне затратно. Однако, для перевода книги или текстов определённой тематики хватит пары десятков тысяч фраз и пары часов на тренировку модели.Помимо текста, данная нейроночка умеет конвертировать в текст изображения, звук, а также изображение и звук одновременно, т.е. видео. На данный момент проект OpenNMT имеет аж 3 реализации:
- OpenNMT на базе фреймворка Torch — https://github.com/OpenNMT/OpenNMT
- OpenNMT-tf на базе фреймворка TensorFlow — https://github.com/OpenNMT/OpenNMT-tf
- OpenNMT-py на базе фреймворка PyTorch — https://github.com/OpenNMT/OpenNMT-py
Однако, OpenNMT на базе Torch более не поддерживается. А между OpenNMT-tf и OpenNMT-py существуют различия в возможностях. Ознакомиться с полным списком возможностей каждой реализации OpenNMT можно на странице http://opennmt.net/features/.
Итак, для перевода текста в текст можно воспользоваться OpenNMT-py. Для быстрого старта можно воспользоваться готовым Docker-образом: nmtwizard/opennmt-py. На всякий случай предупрежу, что тренировка нейросети — задача ресурсоёмкая, и производить её на CPU крайне не эффективно. Разница в производительности между процессором i7-9700K и видеокартой RTX 2070 (8 GB GDDR6) около 20 крат в пользу GPU! Проверял без разгона. При этом стоимость процессора и видеокарты примерно одинаковы. Если у вас есть более-менее шустрая видеокарта, стоит её использовать.
Кстати, эта нейронная сеть по большей части выжирает оперативную память, при потреблении 8 ГБ видеопамяти нагрузка на сам видеочип не более 10-15%. Поэтому если вы хотите покупать видеокарту специально под тренировку данной нейросети — стоит отдать предпочтение модели с большим объёмом фреймбуфера на борту. Из бюджетных рекомендую присмотреться к моделям на базе чипа GTX 1070 Ti с 8 ГБ видеопамяти типа GDDR5 или GTX 1080 Ti с 11 ГБ GDDR5X, но они уже выходят из продажи, а с рук брать рискованно, либо на базе чипандрия RTX 2080 Ti с 11 ГБ GDDR6.
Подробнее о выборе видеочипов для тренировки нейросетей можно почитать и посмотреть графики по ссылке https://timdettmers.com/2019/04/03/which-gpu-for-deep-learning/.
Однако, есть нюанс. В Docker for Windows нет возможности прокинуть GPU в контейнер, поэтому пользователям Windows лучше установить Python и OpenNMT без Docker.
Вкратце расскажу что делать обладателям мощной видеокарты и отсутствием Linux.
- Ставим Python с https://www.python.org/. Версия 3.7 вполне подойдёт.
- Затем нужно установить PyTorch, но нельзя просто так взять и установить PyTorch в Windows.
По крайней мере через pip у меня этого не получилось. - Сначала нужно установить Anaconda. https://docs.anaconda.com/anaconda/install/
- Затем заходим на сайт https://pytorch.org/ и видим такую инструкцию:
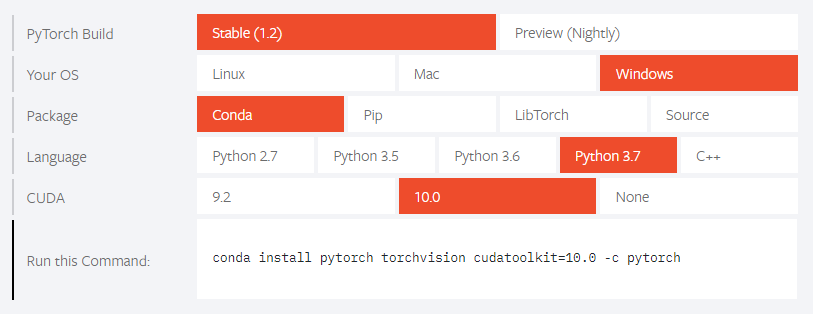
conda install pytorch torchvision cudatoolkit=10.0 -c pytorch
- Установка заняла минут 10-15, после чего можно приступать к установке OpenNMT.
При PyTorch установке через pip я получил такую ошибку:
pip3 install torch===1.2.0 torchvision===0.4.0 -f https://download.pytorch.org/whl/torch_stable.html
Looking in links: https://download.pytorch.org/whl/torch_stable.html Collecting torch===1.2.0 ERROR: Could not find a version that satisfies the requirement torch===1.2.0 (from versions: 0.1.2, 0.1.2.post1, 0.1.2.post2) ERROR: No matching distribution found for torch===1.2.0
Больше инструкций с подробной установкой PyTorch:
- https://medium.com/@bryant.kou/how-to-install-pytorch-on-windows-step-by-step-cc4d004adb2a
- https://www.superdatascience.com/blogs/pytorch-windows-installation-walkthrough
- https://neurohive.io/ru/tutorial/glubokoe-obuchenie-s-pytorch/
- https://msdn.microsoft.com/en-us/magazine/mt848704.aspx
Установка OpenNMT
Для установки OpenNMT-py нудно склонировать репозиторий https://github.com/OpenNMT/OpenNMT-py. Затем перейти в директорию OpenNMT-py и выполнить:
pip3 install -r requirements.txt python setup.py install
Нейросеть готова к тренировке! Из коробки в репозитории присутствует директория data содержащая небольшой датасэт состоящий из англо-немецкого параллельного корпуса из 10 000 предложений для тренировки (src-train.txt и tgt-train.txt), 3 000 предложений для валидации тренировки (src-val.txt и tgt-val.txt) и 2 737 предложений для демонстрации работы перевода (src-test.txt). Пример фраз:
It is not acceptable that , with the help of the national bureaucracies , Parliament 's legislative prerogative should be made null and void by means of implementing provisions whose content , purpose and extent are not laid down in advance .
Es geht nicht an , dass über Ausführungsbestimmungen , deren Inhalt , Zweck und Ausmaß vorher nicht bestimmt ist , zusammen mit den nationalen Bürokratien das Gesetzgebungsrecht des Europäischen Parlaments ausgehebelt wird .
Обратите внимание на специфическое форматирование — знаки препинания отделены от слов пробелом с двух сторон! Зачем это нужно — я пока не понял. Но это сильно влияет на результат тренировки модели и результата перевода. Поэтому не стоит этим пренебрегать при подготовке собственного датасэта.
Также в директории data содержится директория morph с файлами странного содержания. Зачем они нужны я тоже пока не понял.
Обратите внимание, что этот датасэт говно и ничего хорошего на нём натренировать нельзя.
Тренировка OpenNMT
Для начала нужно произвести препроцессинг датасэта:
python preprocess.py -train_src data/src-train.txt -train_tgt data/tgt-train.txt -valid_src data/src-val.txt -valid_tgt data/tgt-val.txt -save_data data/demo
[2019-09-08 22:34:35,828 INFO] Extracting features... [2019-09-08 22:34:35,829 INFO] * number of source features: 0. [2019-09-08 22:34:35,829 INFO] * number of target features: 0. [2019-09-08 22:34:35,829 INFO] Building `Fields` object... [2019-09-08 22:34:35,830 INFO] Building & saving training data... [2019-09-08 22:34:35,830 INFO] Reading source and target files: data/src-train.txt data/tgt-train.txt. [2019-09-08 22:34:35,833 INFO] Building shard 0. [2019-09-08 22:34:36,031 INFO] * saving 0th train data shard to data/demo.train.0.pt. [2019-09-08 22:34:36,383 INFO] * tgt vocab size: 35820. [2019-09-08 22:34:36,410 INFO] * src vocab size: 24997. [2019-09-08 22:34:36,541 INFO] Building & saving validation data... [2019-09-08 22:34:36,541 INFO] Reading source and target files: data/src-val.txt data/tgt-val.txt. [2019-09-08 22:34:36,546 INFO] Building shard 0. [2019-09-08 22:34:36,575 INFO] * saving 0th valid data shard to data/demo.valid.0.pt.
По времени это занимает несколько секунд. В результате чего в директории data, указанной через аргумент -save_data появляются три новых файла: demo.train.0.pt, demo.valid.0.pt и demo.vocab.pt.
Теперь можно тренировать:
python train.py -data data/demo -save_model demo-model
Так как авторы этой нейросеточки полные кретины и уебаны, ни в коем случае нельзя запускать тренировку командой из руководства Quickstart на демо-датасэте, т.к. это бесполезная трата времени! Датасэт — говно и ничего хорошего на нём натренировать нельзя. Поэтому нужно немного скорректировать команду. Если вы тренируете на обычном CPU, то нет смысла ставить более 1 000 шагов тренировки, а для обладателей GPU можно немного увеличить до 10 000 — 30 000. Делается это с помощью опции —train_steps.
python train.py -data data/demo -save_model demo-model --train_steps 1000
[2019-09-08 22:37:51,649 INFO] * src vocab size = 24997 [2019-09-08 22:37:51,649 INFO] * tgt vocab size = 35820 [2019-09-08 22:37:51,650 INFO] Building model... [2019-09-08 22:37:52,132 INFO] NMTModel( (encoder): RNNEncoder( (embeddings): Embeddings( (make_embedding): Sequential( (emb_luts): Elementwise( (0): Embedding(24997, 500, padding_idx=1) ) ) ) (rnn): LSTM(500, 500, num_layers=2, dropout=0.3) ) (decoder): InputFeedRNNDecoder( (embeddings): Embeddings( (make_embedding): Sequential( (emb_luts): Elementwise( (0): Embedding(35820, 500, padding_idx=1) ) ) ) (dropout): Dropout(p=0.3, inplace=False) (rnn): StackedLSTM( (dropout): Dropout(p=0.3, inplace=False) (layers): ModuleList( (0): LSTMCell(1000, 500) (1): LSTMCell(500, 500) ) ) (attn): GlobalAttention( (linear_in): Linear(in_features=500, out_features=500, bias=False) (linear_out): Linear(in_features=1000, out_features=500, bias=False) ) ) (generator): Sequential( (0): Linear(in_features=500, out_features=35820, bias=True) (1): Cast() (2): LogSoftmax() ) ) [2019-09-08 22:37:52,133 INFO] encoder: 16506500 [2019-09-08 22:37:52,135 INFO] decoder: 41613820 [2019-09-08 22:37:52,135 INFO] * number of parameters: 58120320 [2019-09-08 22:37:52,136 INFO] Starting training on CPU, could be very slow [2019-09-08 22:37:52,136 INFO] Start training loop and validate every 10000 steps... [2019-09-08 22:37:52,136 INFO] Loading dataset from data\demo.train.0.pt [2019-09-08 22:37:52,218 INFO] number of examples: 10000 [2019-09-15 14:44:06,831 INFO] Step 50/ 1000; acc: 4.05; ppl: 151630.43; xent: 11.93; lr: 1.00000; 622/634 tok/s; 105 sec
Так, подождите! Такими темпами ждать завершения тренировки придётся более 30 минут! И в логах написано: Starting training on CPU, could be very slow. Так дело не пойдёт! Ах да, у меня же есть видеокарта. Но как же заставить нейросеть тренироваться на видеокарте? Таак, смотрим доку http://opennmt.net/OpenNMT-py/options/train.html и перезапускаем тренировку с такими параметрами:
python train.py -data data/demo -save_model demo-model --train_steps 1000 --world_size 1 --gpu_ranks 0
Такие параметры я ставлю т.к. у меня всего 1 видеокарта и я хочу тренировать на первой из них с индексом 0. Теперь дело пошло быстрее. Пока идёт тренировка, рассмотрим подробнее лог, который выдаётся во время тренировки.
Важно! В момент тренировки нейросети видеокарта не должна использоваться какими-либо ещё процессами. В противном случае могут возникнуть ошибки запуска тренировки:
RuntimeError: cuDNN error: CUDNN_STATUS_EXECUTION_FAILED
RuntimeError: cublas runtime error : library not initialized at ..\aten\src\THC\THCGeneral.cpp:216
RuntimeError: CUDA out of memory. Tried to allocate 2.00 MiB (GPU 0; 8.00 GiB total capacity; 386.71 MiB already allocated; 5.55 GiB free; 35.29 MiB cached)
Во-первых, нужно обратить внимание на структуру NMTModel. Она описывает алгоритмы по которым будет тренироваться модель. По-умолчанию энкодер и дэкодер будет простая RNN (рекуррентная нейронная сеть) (LSTM или GRU). Подробнее можно посмотреть по ссылке: http://opennmt.net/OpenNMT/training/models/. Подробнее эту структуру рассматривать пока не будем, т.к. я ещё не успел с ней разобраться.
Изменить энкодер и дэкодер можно с помощью опций —encoder_type и —decoder_type, которые могут принимать значения rnn, brnn, mean, transformer, cnn и rnn, transformer, cnn соответственно. Также можно изменить тип датасэта для тренировки через опцию —model_type, выбрав один из доступных вариантов: text, img, audio, vec.
Что означает encoder: 16506500 и decoder: 41613820 мне тоже пока не понятно. Следующая строка * number of parameters: 58120320 — тоже не совсем понял.
Смотрим дальше: Start training loop and validate every 10000 steps…
По-умолчанию, валидация хода тренировки будет происходить каждые 10 000 шагов. Что конкретно подразумевается под шагом тренировки — я так и не понял.
Строка Loading dataset from data\demo.train.0.pt — собственно датасэт прошедший препроцессинг и количество предложений в нём — number of examples: 10000.
Далее идёт лог тренировки модели. По-умолчанию, лог со сводным прогрессом тренировки отображается каждые 50 шагов тренировки. Собственно, выводится количество пройденных и оставшихся шагов — Step 50/100000. Затем идёт значение accuracy (дословно — точность), сокращённо acc. Что конкретно подразумевается под этим — я так и не понял, но чем больше значение ≠ тем лучше.
Например, acc: 3.89 — говорит о том, что качество перевода будет очень низким. Каким максимально может быть это значение — я также не понял, на собственных датасэтах у меня получалось доводить его до 50-55, что давало точный перевод фраз длиной 5-8 слов и приблизительный перевод с ошибкой не более чем в половину слов для более длинных предложений. В датасэте идущим из коробки это значение легко достигает значения 80+.
Следующее значение — ppl (perplexity) или дословно растерянность. Также мне не удалось понять что конкретно это значит. На первых шагах тренировки этот параметр имеет пугающий значения вроде 80 108, но по мере тренировки стремительно уменьшается, что свидетельствует об улучшении качества перевода. Мне удавалось тренировать модель на собственных датасэтах до значений в диапазоне 9-14, но какого то значительного вклада этого параметра в качество перевода я не заметил. В датасэте идущим из коробки это значение легко достигает значения 2.
Следующий параметр — xent. Что это такое я тоже не понял. Даже не смог найти расшифровку этого параметра. Его значения достаточно стабильны. Колеблятся около 1.00 и в редких случаях, при использовании не очень хороших датасэтов превышают 10.00. На что влияет — тоже не понял.
Далее следует параметр lr. Что это и как расшифровывается — не понял. В моём случае всегда равен 1.00000 и не изменяется во время тренировки.
Затем следует скорость обработки данных в tok/s. Что это? При тренировки на CPU в среднем значения 635/605, а на GPU — 8004/8043.
Ну и на конец отображается количество секунд прошедших с начала тренировки. 122 sec — в случае с CPU и 10 sec для GPU.
Итак, по прошествии 10 000 шагов наступает этап валидации. В логах это будет выглядеть так:
[2019-09-08 23:20:37,228 INFO] Loading dataset from data\demo.valid.0.pt [2019-09-08 23:20:37,247 INFO] number of examples: 3000 [2019-09-08 23:20:48,184 INFO] Validation perplexity: 10300.5 [2019-09-08 23:20:55,585 INFO] Validation accuracy: 16.2028
Здесь выводится имя валидационного препроцессиного файла датасэта и количество строк в нём. После валидации выводится её результат в параметрах perplexity и accuracy.
[2019-09-08 23:20:55,745 INFO] Saving checkpoint demo-model_step_1000.pt
Также есть параметр —save_checkpoint_steps, который по-умолчанию равен 5 000. Он устанавливает количество шагов, по прошествии которых будет сохраняться промежуточное состояние модели. С помощью этих промежуточных состояний также можно выполнять переводы текста.
Собственно, тренировка завершилась. Рассмотрим интересные моменты.
Во-первых, на шаге 17250 тренировка достигла своего пика качества, а далее начала деградировать. Т.е. 80% времени обучения тренировка шла в холостую и качество нейросети только ухудшались. Пиковые параметры были такие: acc: 84.27; ppl: 1.82; xent: 0.60. И это спустя всего 53 минуты тренировки!
По-умолчанию OpenNMT делает чекпоинт натренированной модели каждые 5 000 шагов. Т.е. при тренировки в 100 000 шагов будет создано 20 моделей с разным уровнем натренированности. Каждая модель для демо-набора занимает на диске по 230 Мб! Частотой создания чекпоинтов можно управлять с помощью опции —save_checkpoint_steps.
Также во время тренировки можно побаловаться и другими параметрами, например:
--rnn_size 200 --word_vec_size 100В моём случае это ускоряет процесс тренировки примерно в 2 раза!
Параметр —word_vec_size отвечает за переопределение сразу двух параметров: -src_word_vec_size и -tgt_word_vec_size, которые по умолчанию равны значению 500.
Опция —rnn_size отвечает за размер скрытых состояний, что бы это ни значило. И также переопределяет одновременно сразу два параметра: —enc_rnn_size и —dec_rnn_size, которые по-умолчанию также равны 500.
Что ж, пора посмотреть нейросеть в деле! Ебашим!
python translate.py --model demo-model_step_10000.pt --src data\src-test.txt --output test.txt --replace_unk --verboseПроцесс перевода достаточно не быстрый, но его результат не может не радовать!
[2019-09-12 23:58:00,081 INFO] Translating shard 0.
SENT 1: ['Orlando', 'Bloom', 'and', 'Miranda', 'Kerr', 'still', 'love', 'each', 'other']
PRED 1: N├дchste M├йtro-Station: Strasbourg (L4 , pinke Linie; Club .
PRED SCORE: -6.5907
SENT 2: ['Actors', 'Orlando', 'Bloom', 'and', 'Model', 'Miranda', 'Kerr', 'want', 'to', 'go', 'their', 'separate', 'ways', '.']
PRED 2: Scrollen Sie Grundst├╝ck und kurvenreiche Strecken , die juengeren Bruder Natale .
PRED SCORE: -10.0936
SENT 3: ['However', ',', 'in', 'an', 'interview', ',', 'Bloom', 'has', 'said', 'that', 'he', 'and', 'Kerr', 'still', 'love', 'each', 'other', '.']
PRED 3: Jedoch hat er sich jedoch sagen , dass er bei seinem vereinbarten Ma├Я der Erhaltung der Systemkonsistenz ausgeht .
PRED SCORE: -13.6115
SENT 4: ['Miranda', 'Kerr', 'and', 'Orlando', 'Bloom', 'are', 'parents', 'to', 'two-year-old', 'Flynn', '.']
PRED 4: Scrollen Sie ein reboot an , um den ├Дrger zu ersparen und die reiche Kultur .
PRED SCORE: -17.1618
SENT 5: ['Actor', 'Orlando', 'Bloom', 'announced', 'his', 'separation', 'from', 'his', 'wife', ',', 'supermodel', 'Miranda', 'Kerr', '.']
PRED 5: Chaos Sie den Friedenspalast und seine Umgebung zur├╝ck .http://opennmt.net/