Хорошо известно, что NGINX используется как асинхронное, событийно-ориентированное решение для обработки соединений. Это означает, что вместо создания выделенного процесса или потока для каждого запроса (наподобие серверов в традиционной архитектуре) он обрабатывает множество соединений и запросов в одном процессе воркера. Чтобы этого достичь, NGINX работает с сокетами в неблокирующем режиме и использует эффективные методы — такие как epoll и kqueue.
Поскольку полноценных процессов мало (обычно один на каждое ядро центрального процессора) и их число является постоянным, количество потребления памяти невысоко и ресурсы процессора не расходуются на переключения. Преимущества такого подхода хорошо известны на примере самого NGINX. Он прекрасно справляется с обработкой миллионов одновременных запросов и отлично масштабируется.
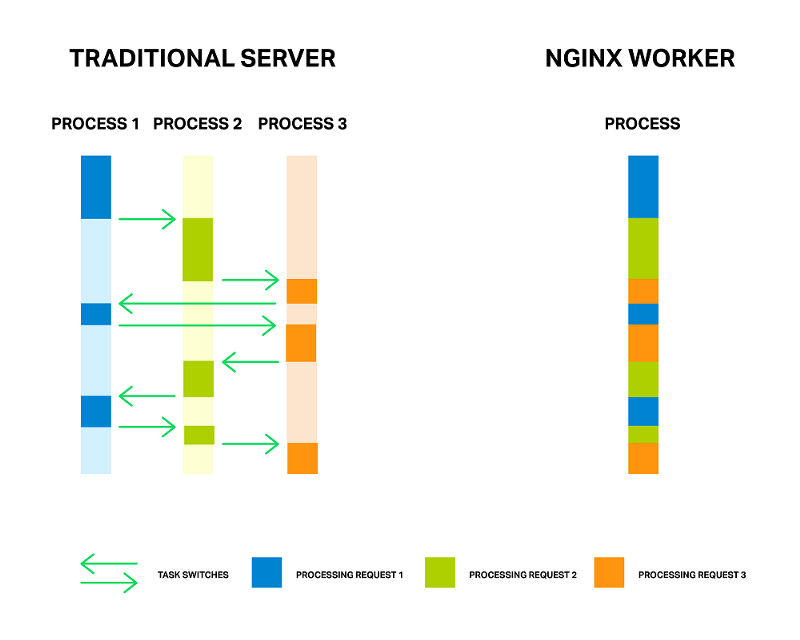
Каждый процесс потребляет дополнительную память, и каждый коммутатор между ними потребляет циклы процессора и L-кеши.
Тем не менее, при событийно-ориентированном подходе все еще возникают проблемы. Мне нравится думать о проблемах как о «врагах». Имя главного врага — блокирование. К несчастью, многие сторонние модули используют блокирующие вызовы, и пользователи (иногда даже разработчики модулей) не знают об этих недостатках. Блокирование операций может разрушить производительность NGINX, поэтому его стоит избегать любой ценой.
Даже в текущем официальном коде NGINX невозможно избежать блокировки операций в каждом случае, и для решения этой проблемы в версиях NGNX 1.7.11 и NGINX Plus Release 7 был реализован новый механизм — «пулы потоков». Что это такое и как это использовать, мы рассмотрим позже. Теперь давайте встретимся лицом к лицу с нашим врагом.
Проблема
Несколько слов о том, как работает NGINX, для лучшего понимания проблемы.
В общих чертах NGINX — обработчик событий, контроллер, который получает от ядра информацию о происходящих в соединениях событиях,, а затем дает операционной системе команды, что делать. Фактически NGINX выполняет всю тяжелую работу — организует операционную систему, а она выполняет рутинную работу по чтению и отправке байтов. Поэтому для NGINX очень важно быстро и своевременно реагировать.
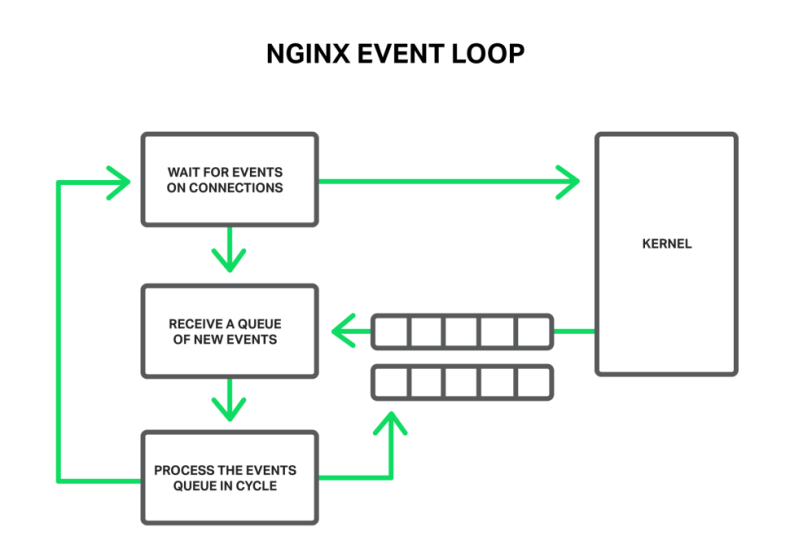
Рабочий процесс прослушивает и обрабатывает события из ядра
События могут иметь таймауты, уведомления о готовых для чтения или записи сокетах или о произошедшей ошибке. NGINX получает пакет событий и поочередно обрабатывает их, выполняя необходимые действия. Таким образом, вся обработка выполняется в простой петле над очередью в одном потоке. NGINX удаляет событие из очереди, а затем реагирует на него, например, записывая или считывая сокет. В большинстве случаев это очень быстро (возможно, просто требуется несколько циклов процессора для копирования некоторых данных в память), а NGINX проходит через все события в очереди в одно мгновение.
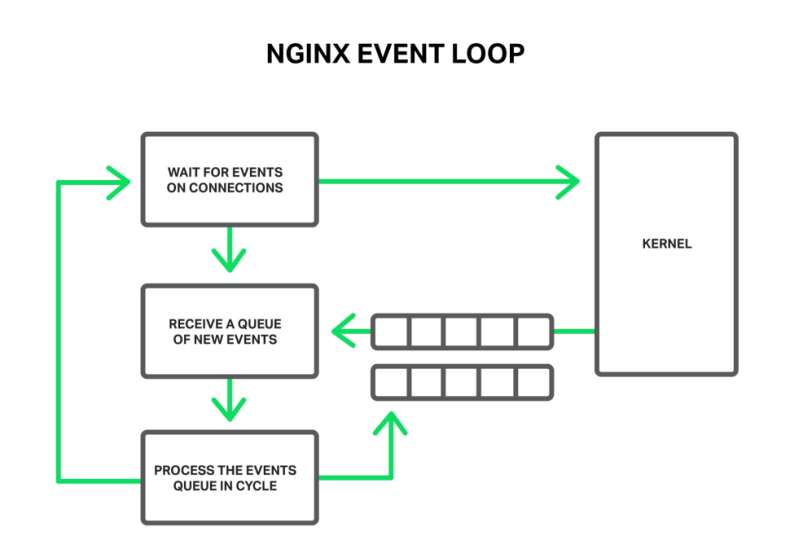
Вся обработка выполняется в простой петле одним потоком
Но что произойдет, если запустится какая-то длительная и тяжелая операция? Весь цикл обработки событий застрянет в ожидании завершения этой операции.
Итак, говоря «блокировка операции», мы подразумеваем любую операцию, которая останавливает цикл обработки событий в течение значительного периода времени. Операции могут блокироваться по разным причинам. Например, NGINX может быть занят длительной обработкой процесса, потребляющего значительные ресурсы процессора. Или может потребоваться доступ к ресурсу (например, жесткий диск или вызов функции мьютекса или библиотеки, который синхронно получает ответы от базы данных, и т.д.). Ключевым моментом является то, что при обработке таких операций рабочий процесс заторможен: невозможно обрабатывать другие события, даже если доступно больше системных ресурсов и некоторые события в очереди могут использовать эти ресурсы.
Представьте продавца в магазине с длинной очередью на обслуживание. Первый в очереди парень просит что-то, чего нет в магазине, но находится на складе. Продавец отправляется на склад для доставки товара. Теперь вся очередь должна ждать несколько часов, и все недовольны. Можете ли вы представить реакцию людей? Время ожидания каждого человека в очереди увеличивается на часы, но предметы, которые они намерены купить, могут находиться прямо в магазине.
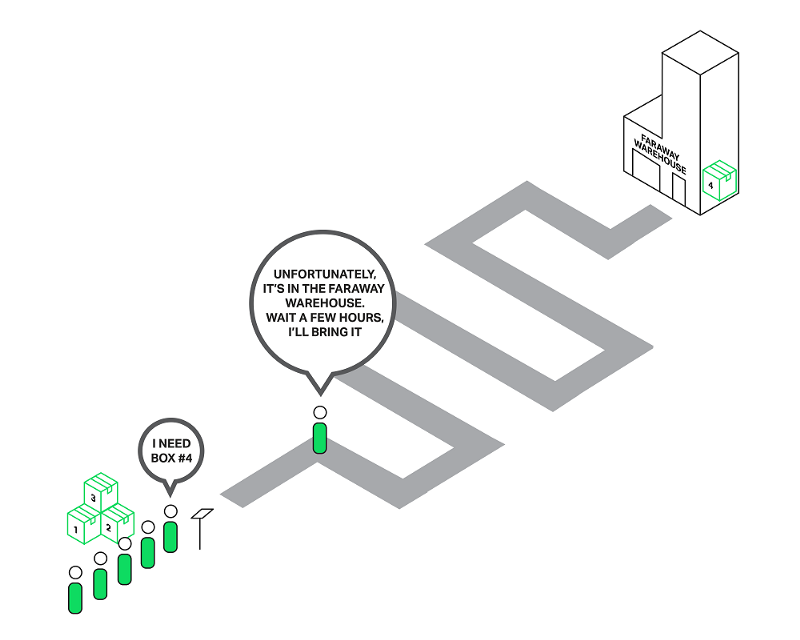
Каждый в очереди должен ждать, пока обслужат первого клиента
Почти такая же ситуация происходит с NGINX, когда он просит прочитать файл, который не кешируется в памяти, но должен быть прочитан с диска. Жесткие диски медленные (особенно вращающиеся). В то время как другим запросам из очереди может не понадобиться доступ к диску, они все равно вынуждены ждать. В результате задержки увеличиваются, а системные ресурсы не используются в полной мере.
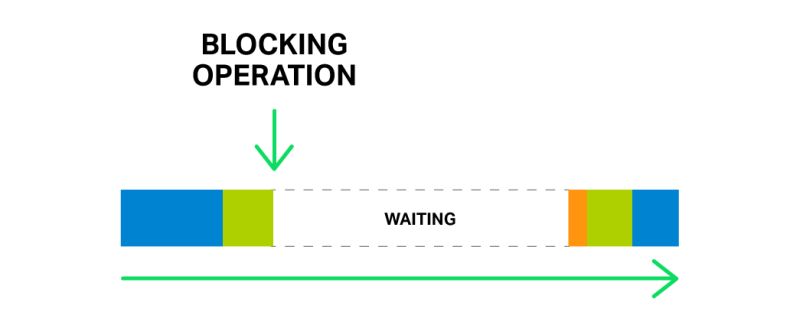
Одна операция блокировки может задержать все последующие операции в течение значительного времени
Некоторые операционные системы предоставляют асинхронный интерфейс для чтения и отправки файлов, и NGINX может использовать этот интерфейс (см. директиву aio). Хорошим примером здесь является FreeBSD. К сожалению, мы не можем сказать то же самое о Linux. Хотя Linux предоставляет своего рода асинхронный интерфейс для чтения файлов, он имеет несколько существенных недостатков. Один из них — требования к выравниванию для доступа к файлам и буферам, но NGINX хорошо справляется с этим. Вторая проблема хуже. Для асинхронного интерфейса в файловом дескрипторе должен быть установлен флаг O_DIRECT, что означает, что любой доступ к файлу будет обходить кеш в памяти и увеличивать нагрузку на жесткие диски. Это определенно не делает его оптимальным для многих случаев.
Для решения этой проблемы в NGINX 1.7.11 и NGINX Plus Release 7 были внедрены пулы потоков.
Теперь давайте рассмотрим, что такое «пулы потоков» и как они работают.
Пулы потоков
Вернемся к нашему бедному продавцу, который доставлял товары с далекого склада. Он стал умнее (может быть, после избиения толпой сердитых клиентов?) и нанял службу доставки. Теперь, когда кто-то просит что-то с далекого склада, продавец не идет на склад сам, а бросает заказ в службу доставки.Курьеры будут обрабатывать заказ, а продавец будет продолжать обслуживать других клиентов. Таким образом, только клиенты, чьи товары не находятся в магазине, ждут доставки, а другие могут быть немедленно обслужены.
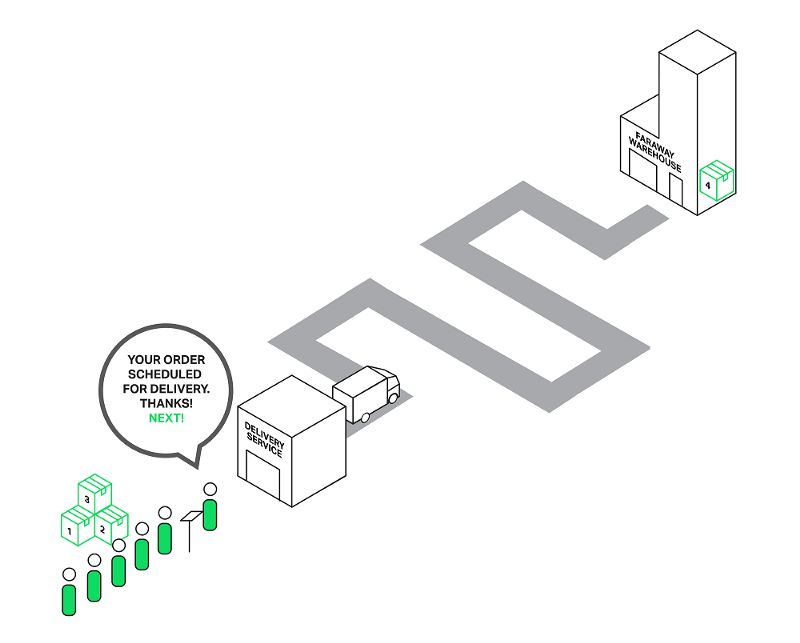
Передача заказа службе доставки разблокирует очередь
С точки зрения NGINX пул потоков выполняет функции службы доставки. Он состоит из очереди задач и нескольких потоков, которые обрабатывают очередь. Когда рабочий процесс должен выполнять потенциально длительную операцию, он ставит задачу в очередь пула, из которой она может быть взята и обработана любым свободным потоком.
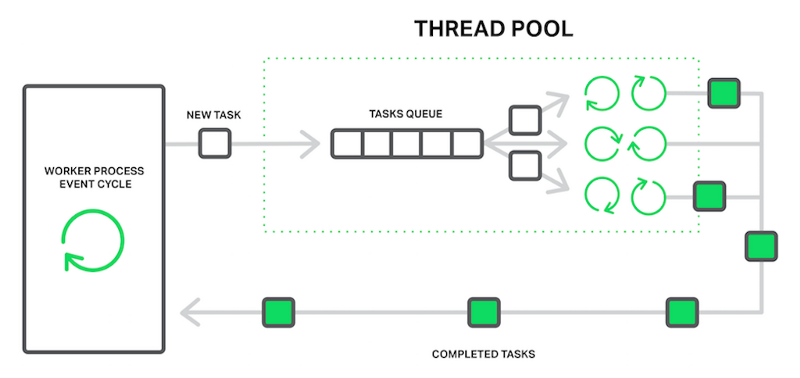
Рабочий процесс выгружает блокирующие операции в пул потоков
Выглядит так, как будто у нас есть еще одна очередь. Но в этом случае очередь ограничена конкретным ресурсом. Мы не можем читать с диска быстрее, чем диск способен создавать данные. Однако теперь диск не задерживает обработку других событий, и ждут только запросы, требующие доступа к файлам.
Операция «чтение с диска» часто используется как наиболее распространенный пример операции блокировки. Но фактически реализация пулов потоков в NGINX может использоваться для любых задач, которые не подходят для обработки в основном рабочем цикле.
На данный момент разгрузка на пулы потоков реализована только для трех основных операций: системные вызовы read() для большинства операционных систем, sendfile() в Linux и aio_write() для Linux, который используется при записи некоторых временных файлов, таких как кеш. Мы продолжим тестировать и оценивать реализацию и сможем разгрузить другие операции в пулы потоков в будущих выпусках, если будет явное преимущество.
Бенчмаркинг
Пришло время перейти от теории к практике. Чтобы продемонстрировать эффект использования пулов потоков, мы собираемся выполнить синтетический тест, который имитирует худшее сочетание блокирующих и неблокирующих операций.
Для этого требуется набор данных, который гарантированно не подходит для памяти. На компьютере с 48 ГБ ОЗУ мы создали 256 ГБ случайных данных в 4-мбайтных файлах, а затем настроили NGINX 1.9.0 для его обслуживания.
Конфигурация довольно проста:
worker_processes 16;events {
accept_mutex off;
}http {
include mime.types;
default_type application/octet-stream; access_log off;
sendfile on;
sendfile_max_chunk 512k; server {
listen 8000; location / {
root /storage;
}
}
}Как вы можете видеть, для достижения лучшей производительности была выполнена некоторая настройка: logging и accept_mutex были отключены, sendfile был включен и sendfile_max_chunkбыл установлен. Последняя директива может уменьшить максимальное время, затрачиваемое на блокировку вызовов sendfile(), поскольку NGINX не будет пытаться отправить весь файл сразу, но сделает это в блоках размером 512 КБ.
Машина оснащена двумя процессорами Intel Xeon E5645 (всего 12 ядер, 24 HT-потоками) и сетевым интерфейсом 10 Гбит/с. Дисковая подсистема представлена четырьмя жесткими дисками Western Digital WD1003FBYX, расположенными в массиве RAID10. Все это оборудование работает на Ubuntu Server 14.04.1 LTS.
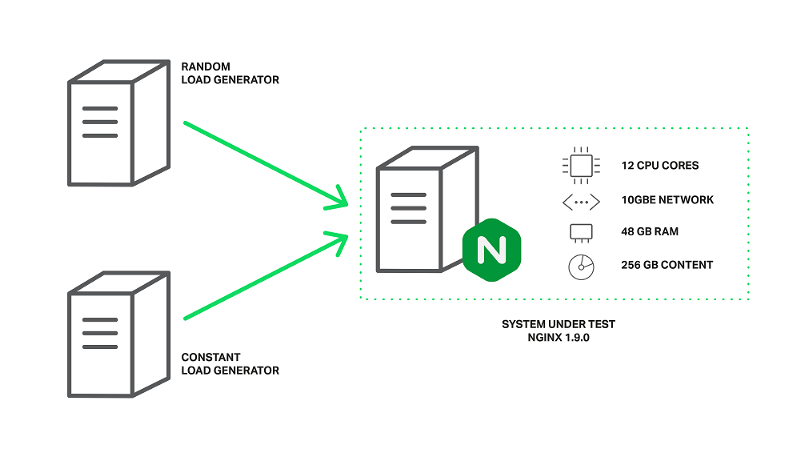
Конфигурация генераторов нагрузки и NGINX для бенчмаркинга
Клиенты представлены двумя машинами с одинаковыми характеристиками. На одной из машин wrk создает нагрузку с использованием сценария Lua. Сценарий запрашивает файлы с нашего сервера в произвольном порядке, используя 200 параллельных соединений, и каждый запрос может привести к промаху в кеше и блокировке, считываемой с диска. Назовем эту нагрузку случайной нагрузкой.
На второй клиентской машине мы запустим еще одну копию wrk, которая будет запрашивать один и тот же файл несколько раз, используя 50 параллельных соединений. Поскольку этот файл будет часто доступен, он будет оставаться в памяти все время. В нормальных условиях NGINX будет выполнять эти запросы очень быстро, но производительность упадет, если рабочие процессы будут заблокированы другими запросами. Назовем эту нагрузку постоянной нагрузкой.
Производительность будет измеряться путем мониторинга пропускной способности серверной машины с использованием ifstat и получения результатов от второго клиента.
Первый запуск без пулов потоков не дает нам интересных результатов:
% ifstat -bi eth2
eth2
Kbps in Kbps out
5531.24 1.03e+06
4855.23 812922.7
5994.66 1.07e+06
5476.27 981529.3
6353.62 1.12e+06
5166.17 892770.3
5522.81 978540.8
6208.10 985466.7
6370.79 1.12e+06
6123.33 1.07e+06Как вы можете видеть, с этой конфигурацией сервер способен производить около 1 Гбит/с трафика в целом. На выводе команды topвидно, что все рабочие процессы тратят большую часть времени на блокирование ввода-вывода (они находятся в состоянии D):
top - 10:40:47 up 11 days, 1:32, 1 user, load average: 49.61, 45.77 62.89
Tasks: 375 total, 2 running, 373 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.0 us, 0.3 sy, 0.0 ni, 67.7 id, 31.9 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem: 49453440 total, 49149308 used, 304132 free, 98780 buffers
KiB Swap: 10474236 total, 20124 used, 10454112 free, 46903412 cached Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
4639 vbart 20 0 47180 28152 496 D 0.7 0.1 0:00.17 nginx
4632 vbart 20 0 47180 28196 536 D 0.3 0.1 0:00.11 nginx
4633 vbart 20 0 47180 28324 540 D 0.3 0.1 0:00.11 nginx
4635 vbart 20 0 47180 28136 480 D 0.3 0.1 0:00.12 nginx
4636 vbart 20 0 47180 28208 536 D 0.3 0.1 0:00.14 nginx
4637 vbart 20 0 47180 28208 536 D 0.3 0.1 0:00.10 nginx
4638 vbart 20 0 47180 28204 536 D 0.3 0.1 0:00.12 nginx
4640 vbart 20 0 47180 28324 540 D 0.3 0.1 0:00.13 nginx
4641 vbart 20 0 47180 28324 540 D 0.3 0.1 0:00.13 nginx
4642 vbart 20 0 47180 28208 536 D 0.3 0.1 0:00.11 nginx
4643 vbart 20 0 47180 28276 536 D 0.3 0.1 0:00.29 nginx
4644 vbart 20 0 47180 28204 536 D 0.3 0.1 0:00.11 nginx
4645 vbart 20 0 47180 28204 536 D 0.3 0.1 0:00.17 nginx
4646 vbart 20 0 47180 28204 536 D 0.3 0.1 0:00.12 nginx
4647 vbart 20 0 47180 28208 532 D 0.3 0.1 0:00.17 nginx
4631 vbart 20 0 47180 756 252 S 0.0 0.1 0:00.00 nginx
4634 vbart 20 0 47180 28208 536 D 0.0 0.1 0:00.11 nginx<
4648 vbart 20 0 25232 1956 1160 R 0.0 0.0 0:00.08 top
25921 vbart 20 0 121956 2232 1056 S 0.0 0.0 0:01.97 sshd
25923 vbart 20 0 40304 4160 2208 S 0.0 0.0 0:00.53 zshВ этом случае пропускная способность ограничена дисковой подсистемой, в то время как центральный процессор занимает большую часть времени. Результаты wrk также очень низкие:
Running 1m test @ http://192.0.2.1:8000/1/1/1
12 threads and 50 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 7.42s 5.31s 24.41s 74.73%
Req/Sec 0.15 0.36 1.00 84.62%
488 requests in 1.01m, 2.01GB read
Requests/sec: 8.08
Transfer/sec: 34.07MBИ помните, это для файла, который должен быть подан из памяти! Чрезмерно большие задержки связаны с тем, что все рабочие процессы заняты чтением файлов с дисков для обслуживания случайной нагрузки, созданной 200 соединениями от первого клиента, и не могут своевременно обрабатывать наши запросы.
Пора ввести в игру пулы потоков. Для этого мы просто добавляем директиву aio threads в блок местоположения:
location / {
root /storage;
aio threads;
}и просим NGINX перезагрузить его конфигурацию.
После этого мы повторяем тест:
% ifstat -bi eth2
eth2
Kbps in Kbps out
60915.19 9.51e+06
59978.89 9.51e+06
60122.38 9.51e+06
61179.06 9.51e+06
61798.40 9.51e+06
57072.97 9.50e+06
56072.61 9.51e+06
61279.63 9.51e+06
61243.54 9.51e+06
59632.50 9.50e+06Теперь наш сервер выдает 9,5 Гбит/с, по сравнению с ~ 1 Гбит/с без пулов потоков!
Вероятно, это может привести к еще большей производительности, но она уже достигла практически максимальной емкости сети, поэтому в этом тесте NGINX ограничен сетевым интерфейсом. Рабочие процессы проводят большую часть времени в состоянии sleep и ждут новых событий (они находятся в состоянии S в выводе top):
top - 10:43:17 up 11 days, 1:35, 1 user, load average: 172.71, 93.84, 77.90
Tasks: 376 total, 1 running, 375 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.2 us, 1.2 sy, 0.0 ni, 34.8 id, 61.5 wa, 0.0 hi, 2.3 si, 0.0 st
KiB Mem: 49453440 total, 49096836 used, 356604 free, 97236 buffers
KiB Swap: 10474236 total, 22860 used, 10451376 free, 46836580 cached Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
4654 vbart 20 0 309708 28844 596 S 9.0 0.1 0:08.65 nginx
4660 vbart 20 0 309748 28920 596 S 6.6 0.1 0:14.82 nginx
4658 vbart 20 0 309452 28424 520 S 4.3 0.1 0:01.40 nginx
4663 vbart 20 0 309452 28476 572 S 4.3 0.1 0:01.32 nginx
4667 vbart 20 0 309584 28712 588 S 3.7 0.1 0:05.19 nginx
4656 vbart 20 0 309452 28476 572 S 3.3 0.1 0:01.84 nginx
4664 vbart 20 0 309452 28428 524 S 3.3 0.1 0:01.29 nginx
4652 vbart 20 0 309452 28476 572 S 3.0 0.1 0:01.46 nginx
4662 vbart 20 0 309552 28700 596 S 2.7 0.1 0:05.92 nginx
4661 vbart 20 0 309464 28636 596 S 2.3 0.1 0:01.59 nginx
4653 vbart 20 0 309452 28476 572 S 1.7 0.1 0:01.70 nginx
4666 vbart 20 0 309452 28428 524 S 1.3 0.1 0:01.63 nginx
4657 vbart 20 0 309584 28696 592 S 1.0 0.1 0:00.64 nginx
4655 vbart 20 0 30958 28476 572 S 0.7 0.1 0:02.81 nginx
4659 vbart 20 0 309452 28468 564 S 0.3 0.1 0:01.20 nginx
4665 vbart 20 0 309452 28476 572 S 0.3 0.1 0:00.71 nginx
5180 vbart 20 0 25232 1952 1156 R 0.0 0.0 0:00.45 top
4651 vbart 20 0 20032 752 252 S 0.0 0.0 0:00.00 nginx
25921 vbart 20 0 121956 2176 1000 S 0.0 0.0 0:01.98 sshd
25923 vbart 20 0 40304 3840 2208 S 0.0 0.0 0:00.54 zshПо-прежнему большое потребление ресурсов ЦП.
Результаты работы:
Running 1m test @ http://192.0.2.1:8000/1/1/1
12 threads and 50 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 226.32ms 392.76ms 1.72s 93.48%
Req/Sec 20.02 10.84 59.00 65.91%
15045 requests in 1.00m, 58.86GB read
Requests/sec: 250.57
Transfer/sec: 0.98GBСреднее время на обслуживание 4-мегабайтного файла сократилось с 7.42 секунд до 226.32 миллисекунды (в 33 раза меньше), а количество запросов в секунду увеличилось в 31 раз (250 против 8)!
Объяснение состоит в том, что наши запросы больше не ждут в очереди событий для обработки, пока рабочие процессы блокируются при чтении, но обрабатываются свободными потоками. Пока дисковая подсистема выполняет свою работу как можно лучше, она может обслуживать нашу случайную нагрузку с первого клиентского компьютера, NGINX использует остальные ресурсы процессора и емкость сети для обслуживания запросов второго клиента из памяти.
Всё ещё не серебряная пуля
После всех наших опасений по поводу блокировки операций и некоторых захватывающих результатов, вероятно, большинство из вас уже собираются настраивать пулы потоков на ваших серверах. Не торопитесь.
Правда в том, что, к счастью, большинство операций чтения и отправки файлов не занимаются медленными жесткими дисками. Если у вас достаточно ОЗУ для хранения набора данных, то операционная система будет достаточно умна, чтобы кешировать часто используемые файлы в так называемом «кеше страницы».
Кеш страниц работает очень хорошо и позволяет NGINX демонстрировать отличную производительность практически во всех случаях общего использования. Чтение из кеша страниц довольно быстрое, и никто не может вызвать операции «блокировки». С другой стороны, разгрузка на пул потоков имеет некоторые накладные расходы.
Поэтому, если у вас имеется достаточное количество оперативной памяти, а ваш рабочий набор данных не очень большой, то NGINX уже работает наиболее оптимальным образом без использования пулов потоков.
Выгрузка операций чтения в пул потоков — это метод, применимый к очень конкретным задачам. Он наиболее полезен, когда объем часто запрашиваемого контента не вписывается в кеш VMоперационной системы. Это может иметь место, например, с сильно загруженным потоковым медиасервером на основе NGINX. Это та ситуация, которую мы моделировали в нашем тесте.
Было бы здорово, если бы мы могли улучшить разгрузку операций чтения в пулы потоков. Все, что нам необходимоо, — это эффективный способ узнать, нужны ли данные в памяти или нет, и только в последнем случае операция чтения будет выгружена в отдельный поток.
Возвращаясь к нашей аналогии с продажами: в настоящее время продавец не может знать, находится ли запрошенный товар в магазине, и должен либо всегда передавать все заказы в службу доставки, либо всегда обращаться за ними самостоятельно.
Причиной является то, что в операционных системах функция неблокирующего вызова отсутствует. Первые попытки добавить ее в Linux как fincore() были в 2010 году, но этого не произошло. Позже было предпринято несколько попыток реализовать его как новый системный вызов preadv2() с флагом RWF_NONBLOCK (подробности см. в разделе «Неблокирующие операции буферизованного чтения файлов» и операции асинхронной буферизации на LWN.net). Судьба всех этих патчей до сих пор не ясна. По-видимому, главная причина, по которой эти патчи еще не были приняты в ядро, – непрерывный bikeshedding.
С другой стороны, пользователям FreeBSD вообще не нужно беспокоиться. FreeBSD уже имеет достаточно хороший асинхронный интерфейс для чтения файлов, который вы должны использовать вместо пулов потоков.
Настройка пулов потоков
Если вы уверены, что можете воспользоваться преимуществами использования пулов потоков в вашем случае, то пришло время глубоко погрузиться в конфигурацию.
Конфигурация довольно простая и гибкая. Первое, что вам нужно, — это NGINX версии 1.7.11 или новее, скомпилированный с аргументом --with-threads командой configure. Пользователям NGINX Plus требуется выпуск 7 или более поздней версии. В простейшем случае конфигурация выглядит тривиально. Достаточно включить директиву aio threads в соответствующий контекст:
# in the 'http', 'server', or 'location' context
aio threads;Это минимально возможная конфигурация пулов потоков. Фактически это короткая версия следующей конфигурации:
# in the 'main' context
thread_pool default threads=32 max_queue=65536;# in the 'http', 'server', or 'location' context
aio threads=default;Он определяет пул потоков по умолчанию с 32 рабочими потоками и максимальную длину для очереди 65536 задач. Если очередь задач перегружена, NGINX отклоняет запрос и регистрирует эту ошибку:
thread pool "NAME" queue overflow: N tasks waitingОшибка означает, что потоки не могут обрабатывать работу так быстро, как она добавляется в очередь. Вы можете попытаться увеличить максимальный размер очереди, но если это не поможет. Значит, ваша система не способна обслуживать столько запросов.
Как вы уже заметили, с директивой thread_pool можно настроить количество потоков, максимальную длину очереди и имя конкретного пула потоков. Последнее подразумевает, что можно настроить несколько независимых пулов потоков и использовать их в разных местах конфигурационного файла для разных целей:
# in the 'main' context
thread_pool one threads=128 max_queue=0;
thread_pool two threads=32;http {
server {
location /one {
aio threads=one;
} location /two {
aio threads=two;
} }
# ...
}Если параметр max_queue не указан, по умолчанию используется значение 65536. Как показано, можно установить max_queue в ноль. В этом случае пул потоков будет способен обрабатывать столько задач, сколько есть настроенных потоков; никакие задачи не будут ждать в очереди.
Теперь давайте представим, что у вас есть сервер с тремя жесткими дисками, и вы хотите, чтобы этот сервер работал как «кеширующий прокси», который кеширует все ответы от ваших серверов. Ожидаемое количество кешированных данных намного превышает доступную оперативную память. На самом деле это кеширующий узел для вашего личного CDN. Конечно, в этом случае самое главное — добиться максимальной производительности с дисков.
Один из ваших вариантов — настроить RAID-массив. Этот подход имеет свои плюсы и минусы. Теперь с NGINX вы можете взять еще один:
# We assume that each of the hard drives is mounted on one of these directories:
# /mnt/disk1, /mnt/disk2, or /mnt/disk3# in the 'main' context
thread_pool pool_1 threads=16;