Spotify начал использовать Docker с несколькими прототипами сервисов в 2014 году. С тех пор Docker много раз обновлялся, и каждый раз возникали проблемы, которые трудно обнаружить, а затем исправить. Пока количество бэкенд-сервисов, работающих на Docker, было низким, то и последствия этих проблем были незначительными. По мере того как осваивался Docker, его влияние росло, пока не достигло неприемлемого уровня. В октябре 2016 были развернуты изменения конфигурации, которые существенно повлияли на работу пользователя.
Возвращаясь на исходные позиции, мы понимали, что нужно новое решение, которое развертывается постепенно и с большим контролем. Эта статья о том, как Docker в Spotify вдохновил нас на создание сервиса, который дал больше контроля над развертыванием изменений инфраструктуры на тысячах серверов.
1. Каждое обновление Docker имело изъяны
Каждый раз при обновлении Docker мы сталкивались с регрессиями или несовместимостью между изменениями Docker и программным обеспечением, которое мы запускали поверх Docker. Более того, устранять неполадки стало труднее.
Две ошибки, с которыми мы столкнулись при обновлении Docker с 1.0.0 до 1.3.1, были исправлены. Docker изменил способ установки имен хостов контейнера и способ обработки настроек CMD и ENTRYPOINT. В течение нескольких дней мы развернули обходные решения для регрессий. Случился небольшой инцидент. Были разрушены несколько конвейерных обработок. В очередной раз нам не повезло.
Летом 2015 было закончено обновление с 1.3.1 до 1.6.2. Казалось, что все идет гладко. Через некоторое время мы обнаружили, что обновление между этими двумя версиями Docker может создавать потерянные контейнеры — контейнеры, не управляемые демоном Docker. Эти контейнеры привязывались к своим первоначальным портам, что заставляло инструмент Docker оркестровки Heliosперенаправлять трафик в неправильный контейнер. Мы воспроизвели проблему, постоянно поднимая и понижая докеры.
Основной причиной было то, что Docker не прекращал работу, в результате чего оставлял потерянные процессы. Мы начали мониторить процессы потерянных контейнеров и отправили патч в апстрим с целью дать Docker больше времени на завершение работы. Эта ошибка была серьезнее остальных.
Обновление с 1.6.2 до 1.12.1 было завершено в ноябре прошлого года. Через неделю, 3 ноября, была обнаружена ошибка в обновлении 1.12.1, которая создавала потерянные процессы docker-proxy. Это предотвратило запуск контейнеров, поскольку порты не выпускались. Мы быстро разблокировали команды, которые не смогли развернуть сервисы.
Мы помогли этим командам обновить копии до 1.12.3. Эта ошибка обновления, как и предыдущая, была труднонаходимой и трудноисправимой.
2. Важность поддержки Docker для Spotify выросла вместе с проблемами и риском
В 2014 только несколько сервисов запускались на сотнях Docker- копий. Мы чувствовали себя достаточно уверенно, чтобы обновить всю тестовую среду, подождать неделю, а затем обновить всю продукцию. Мы столкнулись с парой незначительных ошибок.
Рассмотрим обновление с 1.6.2 до 1.12.1 октября 2016. В то время у нас было несколько тысяч копий Docker, где выполнялись критически важные сервисы, которые регистрировали пользователей, доставляли события и позволяли клиентам разговаривать с бэкендом. Обновление копии Docker перезапускает все запущенные контейнеры. Нужно обновлять программу постепенно, чтобы предотвратить перезагрузку множества сервисов одновременно. Перезапуск таких важных сервисов, как точка доступа и авторизация пользователей, может вызывать недовольство пользователей и приводить к падению низлежащих сервисов.
В феврале 2017 80% бэкенд-сервисов в производстве запускались как контейнеры. В результате Docker перешел от эксперимента к тому, чтобы стать важной частью бэкенд-инфраструктуры Spotify. Наша команда отвечает за запуск и поддержание демонов Docker через множество хостов. Поэтому нужно обновлять Docker постепенно.
3. Мы научились создавать поэтапное решение для развертывания инфраструктуры
Docker был модернизирован до 1.12.1 уже на 30%. Затем, в пятницу, 14 октября, пытаясь исправить состояние гонки при конфигурировании новых Docker-копий, мы развернули плохое изменение. Этот инцидент показал, насколько рискованными стали развертывания Docker и широкомасштабные изменения в целом. Тогда мы создали сервис, который позволил нам постепенно внедрять изменения в инфраструктуру с большим контролем.
Цунами
Цунами позволяет создавать автоматические изменения в компонентах конфигурации и инфраструктуры. Мы можем сказать Цунами «обновить Docker от версии А до Б в течение двух недель». Цунами — линейная интерполяция как сервис. Увеличение продолжительности развертывания повышает надежность. Мы можем обнаружить проблемы, пока они затронули только небольшую часть.
Проблемы, решаемые Цунами
- Масштабирование и обязанности инфраструктуры Docker требуют постепенного обновления.
- Постепенное обновление ограничивает влияние ошибок и дает инженерам время для обнаружения проблем и сообщения о них.
- Текущая установка не позволяет обнаружить все проблемы при обновлении Docker на сервисах или проверке копий других сервисов. Нужно модернизировать производительность сервисов, что требует медленного перехода.
«Переменность» — первичная концепция Цунами. Каждая переменная имеет имя и конфигурацию, контролирующую, какие значения может иметь переменная и как она переходит между значениями с течением времени. Docker отправляет запрос в Цунами, чтобы узнать, какую версию Docker нужно запустить. Цунами возвращает только объект JSON, который указывает желаемое состояние.
В результате получается развертывание:
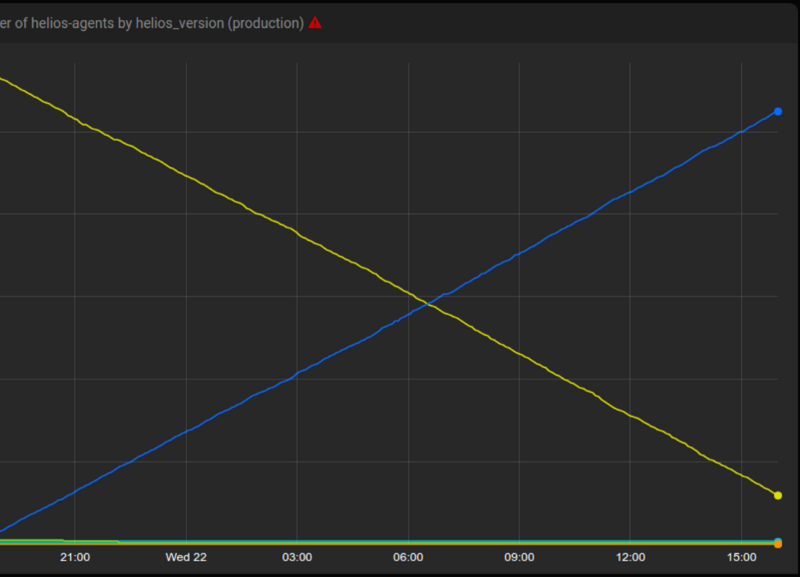
Цунами запускает новую версию Helios тысячам хостов в течение 24 часов.
Желтый — старая версия, синий — новая.
Наличие централизованного сервиса, контролирующего развертывание, позволяет нам создавать функции, бесплатные для клиентов. К ним относятся:
- журнал аудита, который показывает, когда хосту было сказано запустить заданную версию системной службы и по какой причине;
- гранулярная логика, которая показывает, на какой процент хостов в данной роли влияет изменение инфраструктуры, с нижним и верхним уровнем (например, 30% хостов на роль, но как минимум один хост);
- мониторинг целей уровня обслуживания на машинах и автоматическое завершение развертывания, если цели нарушены.
Цунами используется для обновления Helios, Docker и Puppet. Также Цунами помогает создавать изменения конфигурации, которые вызывают перезапуск служб. Мы надеемся, что в ближайшее время появится Цунами с открытым кодом.