RethinkDB — документно-ориентированная база данных, с открытым исходным кодом, с богатыми возможностями администрирования и простой моделью горизонтального масштабирования.
Одна особенность, которая выделяет RethinkDB среди других NoSQL баз данных — проста в использовании с различными языками программирования. Эта СУБД поддерживает множество драйверов, таких как: php, python, ruby и т.д, что позволяет разработчикам взаимодействовать с базой данных, используя наиболее знакомый язык программирования.
В этом руководстве, мы установим и настроим RethinkDB на Ubuntu. Мы будем взаимодействовать с этой СУБД с помощью драйвера на Python, чтобы продемонстрировать, насколько близки сам язык запросов RethinkDB и синтаксис языка Python.
Установка
Есть два компонента, которые должны быть установлены, чтобы получить полную отдачу от архитектуры RethinkDB. Первый — это сама СУБД. Второй — драйвер клиента, который предоставляет поддержку доступа к серверу БД с помощью выбранного языка программирования.
Установка RethinkDB
Программное обеспечение RethinkDB не находится в стандартном репозитории Ubuntu. К счастью, проект даёт возможность для установки используя свой собственный PPA (личный архив пакетов).
Чтобы добавить PPA Ubuntu, мы должны сначала установить python пакет python-software-properties, который включает в себя команды, которые нам необходимы для установки базы.
Обновим индекс пакетов и затем установим PPA:
sudo apt-get update
sudo apt-get install python-software-propertiesСейчас у нас есть установленный пакет python-software-properties, теперь мы можем добавить PPA проекта RethinkDB. Введите следующую команду, чтобы добавить этот репозиторий в вашей системе:
sudo add-apt-repository ppa:rethinkdb/ppaТеперь, мы должны обновить индекс пакетов в системе, для сбора информации о новых пакетах. После этого, мы можем установить RethinkDB:
sudo apt-get update
sudo apt-get install rethinkdbТеперь нужно настроить один экземпляр базы (инстанс) и перезапустить ёё.
sudo cp /etc/rethinkdb/default.conf.sample /etc/rethinkdb/instances.d/instance1.conf
sudo /etc/init.d/rethinkdb restartУстановка драйвера клиента
После выполнения вышеописанных действий, мы должны установить драйвер клиента. Клиентские драйвера есть почти для каждого языка программирования. Официально поддерживаемые языки JavaScript, Ruby и Python. Сообщество также добавило поддержку многих других языков, включая C, Clojure, Lisp, Erlang, Go, Haskell, Java, Perl, PHP, Scala и другие.
В данном руководстве мы будем использовать Python-клиент, потому что Python уже установлен в систему.
Установим драйвер клиента с помощью pip. Чтобы соответствовать рекомендациям при работе с программным обеспечением в Python мы будем использовать virtualenv, чтобы изолировать нашу среду Python. При установке virtualenv, pip будет установлен автоматически.
sudo apt-get install python-virtualenvИтак, мы имеем установленный virtualenv и pip, теперь мы можем создать каталог в нашей домашней директории для установки виртуального окружения:
cd ~
mkdir rethinkПерейдите в этот каталог и затем используйте команду virtualenv для создания новой виртуальной среды:
cd rethink
virtualenv venvМы можем активировать среду, введя команду:
source venv/bin/activateЭто позволит нам устанавливать компоненты в изолированной среде. Если нам нужно покинуть виртуальную среду (но не делайте этого сейчас), введите:
deactivateИтак, сейчас мы имеем включённую виртуальную среду, теперь мы можем установить пакет RethinkDB, для этого введите:
pip install rethinkdbНаш Python клиент установлен и готов к использованию.
Запускаем RethinkDB и исследуем веб-интерфейс
На самом деле мы уже запустили один экземпляр сервера, выполнив команду restart. Если мы посетим IP адрес нашего сервера http://localhost:8080, на порту: 8080, то увидим веб-интерфейс RethinkDB:
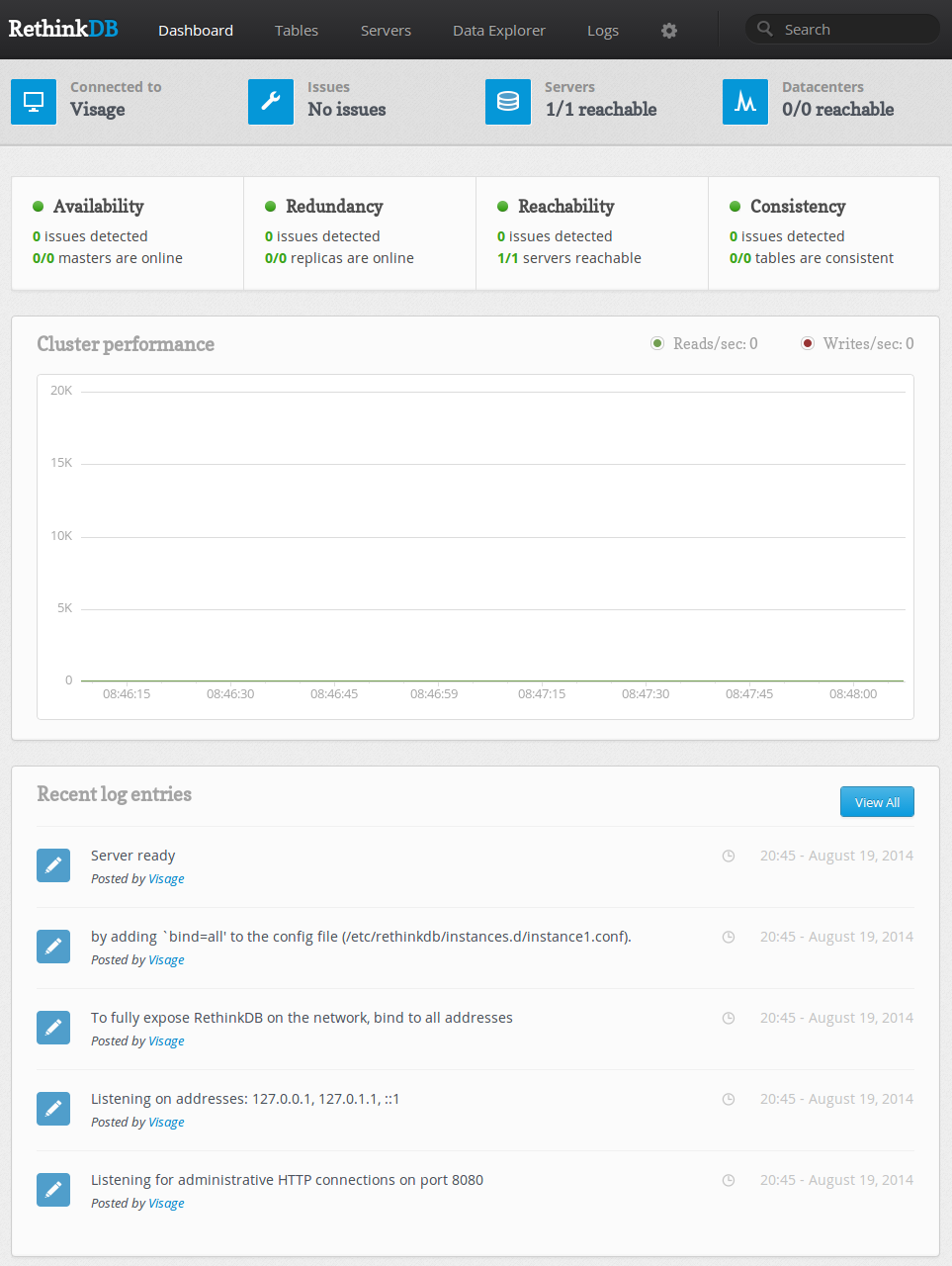
Как вы можете видеть, мы имеем достаточно функциональный интерфейс для сервера нашей базы данных. На главной странице, мы можем увидеть некоторые стандартные проверки работоспособности и метрики производительности кластера. Ниже показана недавняя активность сервера.
Также мы видим некоторую статистику о нашей базе данных. Возле синих иконок есть информация о названии базы данных и информация о текущих найденных неполадках (issues).
Кроме того, вы можете видеть, что RethinkDB имеет собственное управление серверами и центрами обработки данных. Ещё одна особенность этой базы — лёгкое масштабирование.
Если мы нажмем на «Tables», расположенную в верхней части страницы, то увидим, какие базы и таблицы были созданы на данный момент:
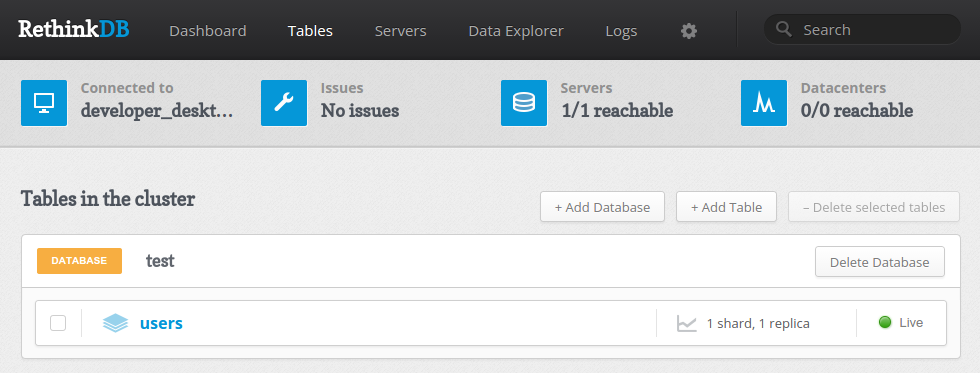
Здесь мы можем видеть все базы данных, которые есть на нашем сервере. Для каждой базы можно просмотреть список таблиц. В обзоре, также говорится нам о шардинге и репликации, которые были настроены для каждого компонента. Мы можем добавлять базы данных и таблицы прямо с этой страницы.
Если мы нажмем на одну таблицу, то сможем увидеть обзор нагрузки, распределения и количества документов:
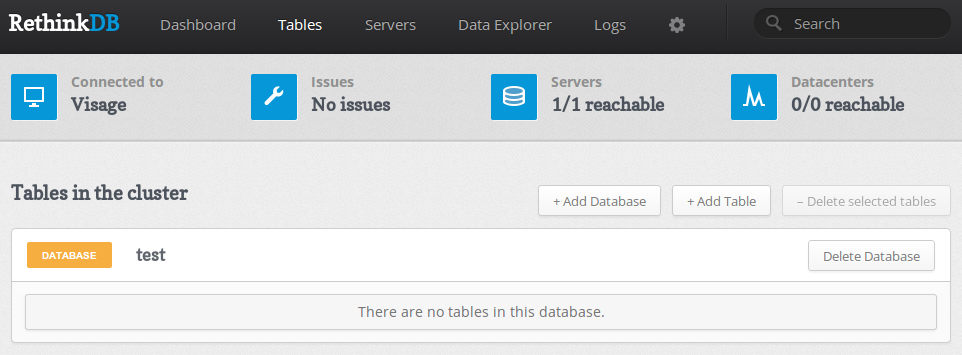
Здесь отображается детальная информация о нагрузке и конфигурации каждой таблицы. Прямо отсюда можно редактировать шардинг и настройки репликации, добавить индексы для более эффективных запросов.
Теперь перейдём на вкладку Servers, тут мы увидим список серверов нашей СУБД.
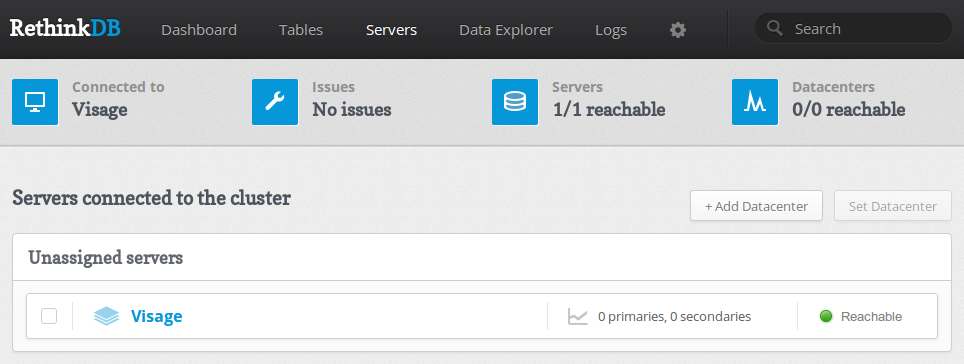
Еще раз, вы можете нажать на отдельном сервере, чтобы получить краткий обзор его свойств:
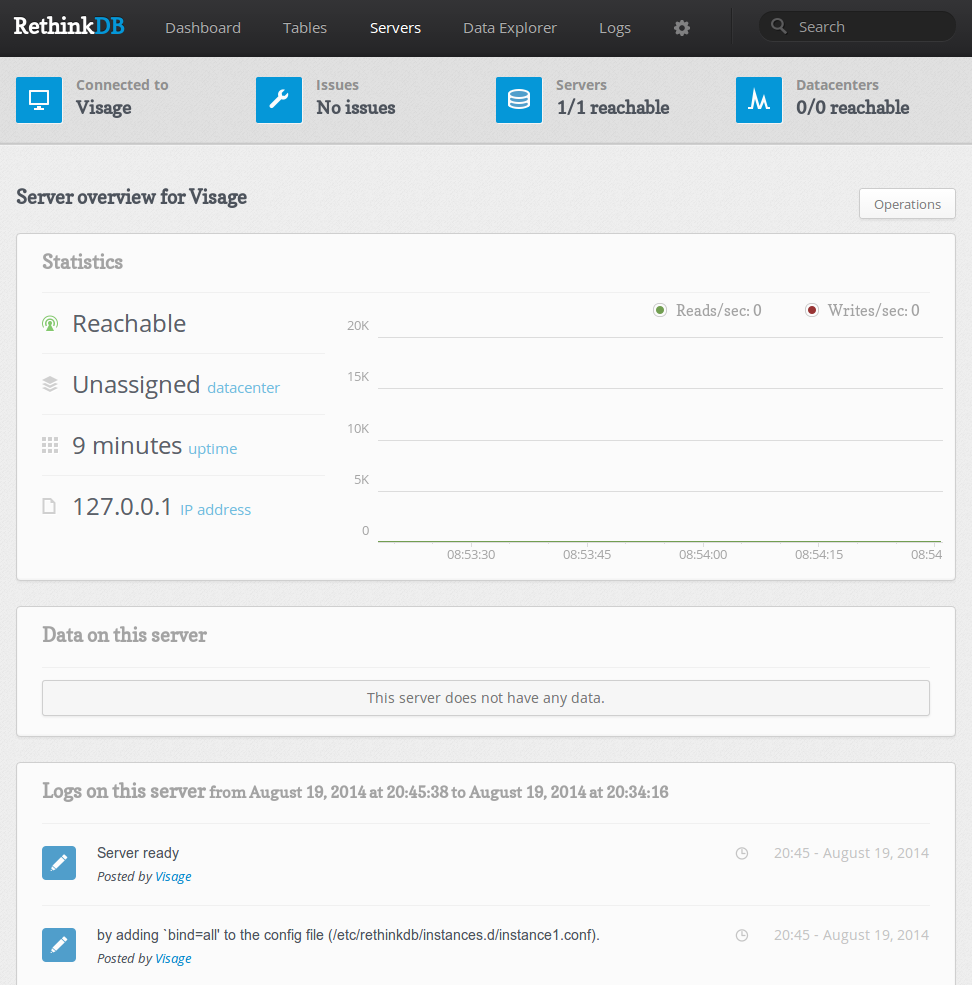
Переходим к следующей ссылке, под названием «Data Explorer», видим интерфейс для взаимодействия с сервером с помощью языка запросов:
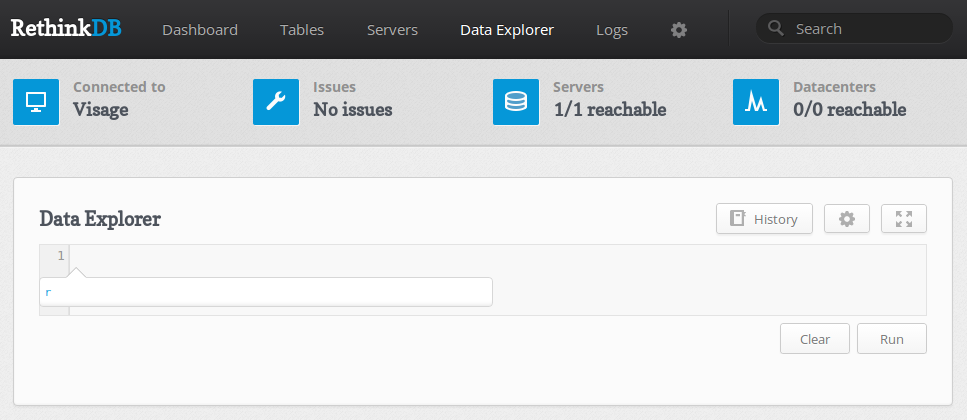
Мы можем создавать, удалять и изменять таблицы и данные в пределах этого интерфейса.
Если вы введёте запрос или команду, то сможете увидеть результаты ниже. Мы можем просматривать информацию в различных форматах, а также сделать профилирование запроса:
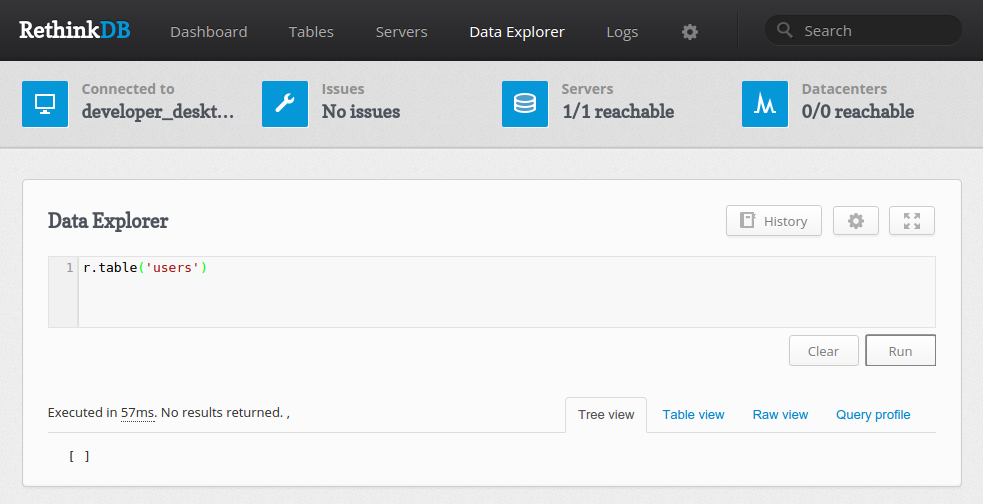
Сто процентов вы уже убедились, что RethinkDB это отличный инструмент с высоким уровнем управления базами данных и кластерами.
Взаимодействие с RethinkDB в Python
Хотя веб-интерфейс является простым и понятным в использовании, в большинстве случаев вы будете взаимодействовать с базой данных через программный код.
Исследуем RethinkDB с помощью Python
Запустите интерпретатор Python, так мы сможем начать взаимодействовать с базой данных:
pythonОтсюда, нам просто необходимо импортировать драйвер клиента в окружающую среду:
import rethinkdb as rТеперь мы можем соединиться с локальной базой данных с помощью команды connect:
r.connect("localhost", 28015).repl().repl() — позволяет нам выполнять команды в текущем подключении, а вообще текущее подключение нужно указывать в команде run (пример ниже). Но в данном случае repl() используется для удобства тестирования. Теперь у нас есть связь с нашим сервером, и мы можем сразу же начать работать с базой данных.
Давайте создадим базу, выполнив команду:
r.db_create("food").run()Теперь мы имеем базу данных под названием "food". Команда .run() находится в конце — это очень важно. RethinkDB команды выглядят как обычный код, но на самом деле они трансформируются клиентским драйвером RethinkDB в машинный код базы данных и выполняются удаленно на сервере.
Команда run отправляет все это на сервер. Если бы мы не указали repl при соединении с сервером, то текущее соединение необходимо указать в команде run:
conn = r.connect("localhost", 28015)
r.db_create("food").run(conn)Эти первые несколько команд дают нам общее представление о том, как выполняются цепочки команд в RethinkDB. Сложные команды могут быть объединены в цепочки для того, чтобы выполнить несколько операций одновременно.
Теперь, когда у нас есть база данных, давайте создадим таблицу:
r.db("food").table_create("favorites").run()Затем мы можем добавить некоторые данные в таблицу. RethinkDB использует гибкую структуру для документов, так что вы можете добавить любые виды пары ключ/значение.
Мы добавим некоторых людей и их любимые продукты:
r.db("food").table("favorites").insert([
{ "person": "Randy", "Age": 26,
"fav_food": [
"banana",
"cereal",
"spaghetti"
]
},
{ "person": "Thomas", "Age": 8,
"fav_food": [
"cookies",
"apples",
"cake",
"sandwiches"
]
},
{ "person": "Martha", "Age": 52,
"fav_food": [
"grapes",
"pie",
"avocado"
]
}
]).run()Это позволит создать три JSON документа в нашей таблице «favorites» . Каждый объект определяет человека, возраст, и его любимую еду.
Мы можем распечатать документы с помощью запроса. Например, мы можем вывести все значения, введя:
c = r.db("food").table("favorites")
for x in c:
print x
#{u'person': u'Martha', u'Age': 52, u'fav_food': [u'grapes', u'pie', u'avocado'], u'id': u'b888ec64-f2c9-4f85-9db6-f8b8a66626c6'}
#{u'person': u'Thomas', u'Age': 8, u'fav_food': [u'cookies', u'apples', u'cake', u'sandwiches'], u'id': u'3aa7ae68-85b0-48b6-9726-76e810ea4c55'}
#{u'person': u'Randy', u'Age': 26, u'fav_food': [u'banana', u'cereal', u'spaghetti'], u'id': u'f027a270-d5ac-4c33-ad91-53a7541ace82'}RethinkDB возвращает данные в пакетном режиме (выбирает порциями), это означает, что он выбирает не все данные, а только некоторую часть из всего набора. Как только в цикле закончится выбранная порция данных RethinkDB сделает ещё один запрос на получение новой порции, но для программиста это происходит прозрачно, для него всё выполняется в одном цикле.
Вы, возможно, заметили, что каждая из тех записей, которую мы добавили в таблице "favorites" был присвоен идентификационный номер. Это делается автоматически и используется для индексации содержимого каждой таблицы.
Мы можем фильтровать результаты, просто добавив еще одно звено в цепочке команд:
c = r.db("food").table("favorites").filter(r.row["fav_food"].count() > 3).run()
for x in c:
print x
# {u'person': u'Thomas', u'Age': 8, u'fav_food': [u'cookies', u'apples', u'cake', u'sandwiches'], u'id': u'3aa7ae68-85b0-48b6-9726-76e810ea4c55'}Чтобы отфильтровать данные, мы просто добавили команду .filter(). Мы использовали r.row для ссылки на ключ fav_food, а потом посчитали количество записей для каждой строки. Мы сделали простое сравнение, чтобы отфильтровать тех людей, у которых было 3 или меньше любимых блюд.
Заключение
Данное руководство охватывает лишь основы RethinkDB, на самом деле у неё есть ещё куча возможностей, например, таких как объединение для таблиц (join), map reduce, аггрегатные функции, шардинг, репликация и многое другое.