Property is a flexible mechanism to access private fields (set and get value) and implement computations. Now we have different ways for implementing properties — from classic with backing field and get-set keywords to modern lambda-style. Let’s find is there any difference between all these properties.
This article is based on StackOverflow question
We start from classic definition of property:
class Contact
{
private string _address;
public string Address
{
get { return _address; }
set { _address = value; }
}
}
Under the hood C# compiler replaces property with special methods, one for setter and one for getter. It’s easy to prove:
class Contact
{
private string _address;
public string Address
{
get { return _address; }
set { _address = value; }
}
public void set_Address(string value)
{
_address = value;
}
public string get_Address()
{
return _address;
}
}

We see a spectial error for this case Type 'type' already reserves a member called 'name' with the same parameter types.
What if we have only getter and set method?
class Contact
{
private string _address;
public string Address
{
get { return _address; }
}
public void set_Address(string value)
{
_address = value;
}
}
We still have an error:

If there is a property <Property>, then methods get_<Property> and set_<Property> are reserved, and we can’t use these names for methods even if class doesn’t contain property with corresponding getter or setter.
Obviously, if field _address is readonly property becomes read-only too:
class Contact
{
private readonly string _address = "readonly address";
public string Address
{
get { return _address; }
}
}
The next stage of properties evolution is auto-implemented properties.
class Contact
{
public string Address { get; set; }
}
This class is functionally equal to our first example, but looks cleaner. C# compiler generates private anonymous field that can be accessed the property’s getter and setter.
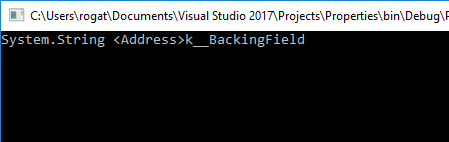
This field will have name like <Property_Name>k__BackingField, so it has illegal for C# variable names symbols <, > and you can’t create this field by hands:
class Program
{
static void Main(string[] args)
{
foreach (var item in typeof(Contact).GetMembers(
System.Reflection.BindingFlags.DeclaredOnly |
System.Reflection.BindingFlags.NonPublic |
System.Reflection.BindingFlags.Instance))
{
Console.WriteLine(item);
}
}
class Contact
{
public string Address { get; set; }
}
}
You can also have a property with getter or setter only:
class Contact
{
public string Address { get; }
}
What about read-only and inline-initialization?
Since C# 6 you can make auto-implemented properties read-only:
class Contact
{
public string Address { get; } = "readonly address";
}
class Program
{
static void Main(string[] args)
{
var contact = new Contact();
contact.Address = "aaa";
}
}
Adding setter will make this property non-read-only but initialized by default value:
class Contact
{
public string Address { get; set; } = "default address";
}
class Program
{
static void Main(string[] args)
{
var contact = new Contact();
Console.WriteLine(contact.Address); //"default address"
contact.Address = "aaa";
}
}
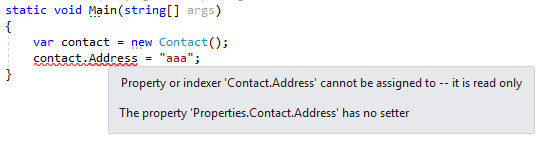
C# 6 allows to create read-only properties with lambda expression:
class Contact
{
public string Address => "lambda readonly address";
}
class Program
{
static void Main(string[] args)
{
var contact = new Contact();
contact.Address = "aaa"; //Error CS0200 Property or indexer 'Contact.Address' cannot be assigned to --it is read only
}
}
So, it looks like C# has 2 ways to define read-only properties:
class Contact
{
public string Property1 => "property1";
public string Property2 { get; } = "property2";
}
class Program
{
static void Main(string[] args)
{
var contact = new Contact();
Console.WriteLine(contact.Property1);
Console.WriteLine(contact.Property2);
}
}
But, the difference is high when you use these properties many times:
class Contact
{
public string Property1 => GetProperty1();
public string Property2 { get; } = GetProperty2();
private static string GetProperty1()
{
Console.WriteLine("init property 1");
return "property1";
}
private static string GetProperty2()
{
Console.WriteLine("init property 2");
return "property2";
}
}
class Program
{
static void Main(string[] args)
{
var contact = new Contact();
Console.WriteLine(contact.Property1);
Console.WriteLine(contact.Property1);
Console.WriteLine(contact.Property2);
Console.WriteLine(contact.Property2);
}
}
Let’s look at result:
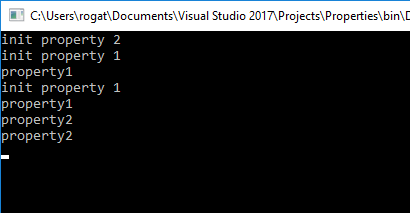
At the first row we see init property 2 in output. This is property inline-initialization: public string Property2 { get; } = GetProperty2(); It’s called before any class instance usage. The next 4 rows are about contact.Property1 call (init property and get value for every call). And the last 2 rows — is only printing contact.Property2 without initialization (that was made before).
So, lambda-style property is equal to:
public string Property1
{
get { return GetProperty1(); }
}
And property with getter and default value is equal to:
private readonly string _property2 = GetProperty2();
public string Property2
{
get { return _property2; }
}