In this post I will share the process we went through at PerimeterX while searching for ways to speed up our main application deployment, with no downtime.
Background
Our environment is based, in large part, on Docker containers. We have a dynamic number of front-end CoreOS machines; each includes an HAProxy container and a few instances of our main application. Every application instance is a Docker container as well. Just for easy reference in this blog, let’s call these containers pxApp1, pxApp2, etc. We are using HAProxy to balance the requests between our pxApp containers and to manage and offload SSL termination.
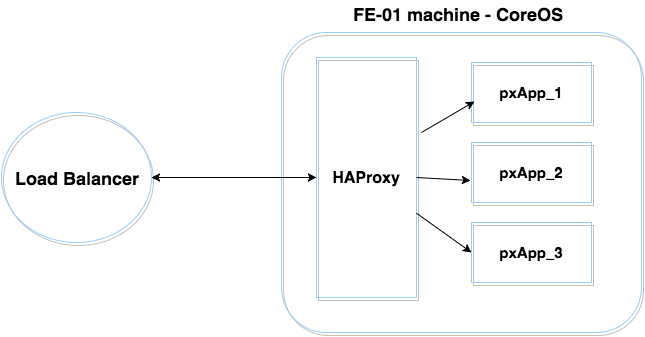
Our first deployment solution was simply an Ansible playbook which replaced the old pxApp services with a new version. That solution was written for a very small environment without strict SLA requirements.
The front-end playbook contains our basic roles: common, pxApp and HAproxy. The pxApp role deployed the requested image version that we built and pushed to GCR (Google Container Registry) using a Jenkins job that executed right before the Ansible deployment. HAProxy was configured by an Ansible Jinja2 template to match the deployed pxApps.
Ansible role — run/deploy pxApp container:
- name: Run prod pxApp
docker:
name: pxApp_{{ id }}
image: gcr.io/px_blog_example/pxapp:{{ pxapp_version }}
state: reloaded
ports:
- 8080
restart_policy: always
pull: always
with_sequence: start=1 end={{ pxapp_per_host }} format=%02xAnsible Jinja2 template of HAProxy backend example:
backend pxapp_cluster
balance roundrobin
option httpchk HEAD /api/my/status HTTP/1.1\r\nHost:pxapp
{% for id in range(1, app_per_host + 1) %}
server pxApp_{{ id }} pxApp_{{ id }}:8080 check
{% endfor %}But then…
As our service grew and scaled up, we had to improve this rollout method to be:
- much faster.
- appropriate on a much larger scale.
- easily deployed without any traffic loss.
So we started to search for a better solution that would fit our new requirements.
The explorer’s path to the best solution may not be a straight line
The first method we tried:
- We removed the FE machine from GLB (global load balancer) using gcloud API and waited for traffic to drain.
- Run the ansible-playbook to deploy pxApp{1..3} containers one by one, on the machine.
- Add that FE machine back to the GLB.
This entire process can run in parallel on some of the machines using predefined percentages.
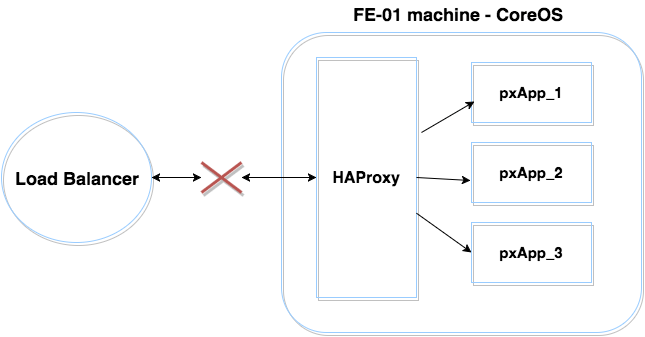
Relying on the gcloud API to remove and add machines back to the GLB turned out to be a slow process which also had a high degree of variability, taking anywhere from a few seconds to as long as minutes.
Our second approach:
Next, we tried the Blue-Green deployment method, creating three new pxApp containers to replace the existing three, and then carried out the switch from the former to the latter.
As a first step, we configured six backend servers in the HAProxy — three active and three inactive servers. We followed this sequence:
- Create and deploy pxApp_4 container.
- Disable pxApp1 and enable pxApp4 using HAProxy socket commands (disable server /).
- Remove pxApp_1 container.
Then we repeated that sequence with pxApp5 ↔ pxApp2 and pxApp6 ↔ pxApp3, and deployed the new version to each FE machine.
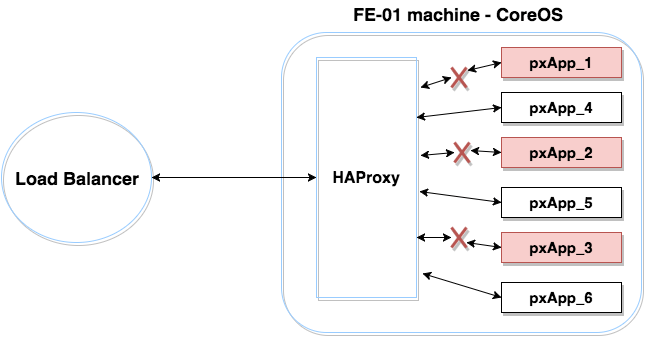
We encountered the following problems with this solution:
- Each deployment was time-consuming. Adding more pxApp containers dramatically slowed down the deployment process.
- This deployment method requires that unused machine resources be reserved for deployments. This translated into a waste of money and resources.
- With HAProxy configuration and Docker network links, this environment became complex.
The winning solution
We experimented with a few other methods, before finding the combination of HAProxy Unix Socket commands and Ansible Rolling update that was the most successful for us.
Thus, we arrived at the solution that we ultimately adopted:
Split the FE machines into three groups, using property “serial: 35%” — the ansible rolling update batch size. As a result, the ansible-playbook will run on three groups, one by one. Let’s call them Group A, Group B and Group C. For each group we created an Ansible batch consisting of three application containers (acting in parallel on all FE machines in the group). When deploying the first pxApp container on all machines in group A, the following steps are carried out in order:
- Change the weight of pxApp_x on the HAProxy (socket command) to 0
- Deploy pxApp_x container
- Change back the weight of pxApp_x to 1
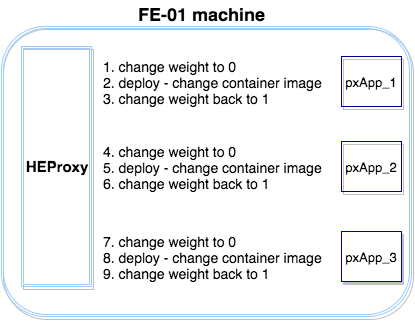
Once those three steps are completed for pxApp1 on all machines in group A, take pxApp2 through the same sequence, and then do the same with pxApp_3. That sequence takes care of the FE machines of group A. Note that during this process at each given time, at most 1/9 of the containers are down, allowing smooth operation of the service.
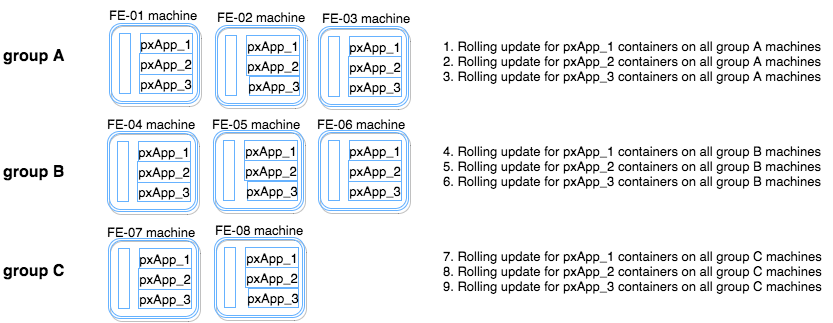
Having completed deployment of the FE machines in group A, we then deploy the second Ansible batch, which contains the FE machines of group B, and repeat the same process. We carry out the same steps detailed above for all pxApp_{1..3} containers, one by one. Finally, we repeat these three steps on the FE machines of group C, in the last of the three Ansible batches.
Thanks to Ansible parallelism and HAProxy fast socket API, we reduced the deployment time of our biggest app dramatically — by up to 70% in some cases — without increasing wasted resources. An additional important benefit: there is no traffic loss during the deployment.
Deploy FE machine playbook example:
- name: Configure and deploy frontend servers
hosts: all
serial: "35%"
sudo: true
roles:
- { role: other-role, tags: ['r_other_role'] }
- { role: pxapp, tags: ['r_pxapp'], id: 1 }
- { role: pxapp, tags: ['r_pxapp'], id: 2 }
- { role: pxapp, tags: ['r_pxapp'], id: 3 }
- { role: haproxy, tags: ['r_haproxy'] }pxApp role example:
- name: Change pxApp '{{ id }}' docker to weight 0
shell: docker exec -i -t haproxy-container bash -c "echo set weight pxapp_cluster/pxApp_'{{ id }}' 0 | socat stdio /var/run/haproxy.sock"
- pause: seconds=5
- name: Run pxApp-example
docker:
name: pxApp.{{ id }}
image: gcr.io/px_blog_example/pxapp:{{ pxapp_version }}
state: reloaded
ports:
- 8080
restart_policy: always
pull: always
- name: Change pxApp {{ id }} docker to weight 1
shell: docker exec -i -t haproxy-container bash -c "echo set weight pxapp_cluster/pxApp_{{ id }} 1 | socat stdio /var/run/haproxy.sock"Key points:
- Even if you use “serial: 0” in the playbook — deploying all FE machines in parallel will not cause downtime. You need to be aware, however, that one third of the service resources will be down during the deployment.
- Run the ansible-playbook deployment with only the necessary roles — using tags (“-t” flag). For example: ansible-playbook -i inventory/production frontend.yml -t r_pxapp. Your deployment will be faster and more efficient.
- We used — pause: seconds=5 to drain open connections, in order to avoid dropping any live connection. This can be tuned for different applications that require more/less time to drain connections. Another option: query HAProxy stats api for open connection, and proceed with the deployment only when the HAProxy backend has no open connections.
This method, which became our standard deployment in our Docker-based environment, avoids downtime and is also much faster and more efficient than the methods we used before. We already have plans for future improvements to further boost speed and scalability, using tools like packer and docker datacenter.