Когда-то, году эдак в 2005, я заболел идеей создания базы знаний, которая бы не имела четкой табличной структуры и работала бы на принципе именованных узлов и связей между ними. Основная идея была такая, что сам по себе узел не нес никакой информации, а вся информация бы задавалась его окружением и связями. Я тогда написал небольшой код хранилища этих узлов и связей, а также простейших операций над ними, но совсем не хранить информацию в узлах было слишком сложно и я привязывал к каждому узлу одно текстовое свойство (в Neo4j в узел можно записать много свойств различного типа и потом обращаться к ним по имени).
Этот движок изначально был написан на C#, затем несколько раз переписывался, но постепенно интерес к нему я потерял. Вспомнил ту свою разработку, когда недавно наткнулся на Neo4j, и узнав некоторые свои идеи захотел детальней с ней ознакомиться.
Neo4j я установил на виртуалку, оказалось что встроенный фронт-енд имеет веб-интерфейс и доступен по адресу http://localhost:7474
После перехода по адресу мне было предложено ввести имя пользователя и пароль, при этом давалась подсказка что есть дефолтное имя пользователя “node4j” и пароль такой же. Далее меня ждала страница приветствия, на которой были три основных кнопки — Start Learning, Write Code и Monitor:
Самое первое я перешел на страницу мониторинга и сразу над блоком с кнопками добавился еще один блок, в котором я увидел статистику по БД (на скрине я уже успел добавить одну ноду):
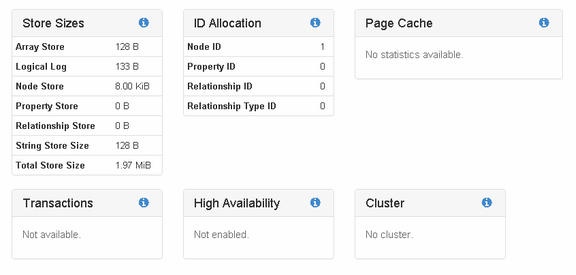
Оказалось что новая информация на экран добавляется такими блоками, которые можно удалить, закрепить, листать, а самые старые из них проваливаются вниз.
В самом верху оказалась командная строка для выполнения местного языка запросов, по аналогии с SQL только тут он называется “Cypher Query Language”. Мне сразу захотелось хоть что нибудь добавить в базу, но не такое сложное, как было предложено во встроенном примере “play movie graph” — там была целая страница команд, которая по видимому создавала целую кучку сущностей со свойствами и связями между ними. Вместо этого я перешел по ссылке на описание команды CREATE и по примеру выполнил CREATE (n), создав просто простейшую отдельную ноду.
Далее я все-таки решил найти где прописаны порты на которых сервер ждет соединения, чтобы подключаться к виртуалке со своего браузера а не локального браузера виртуалки. Оказалось нужно раскомментировать строку
#org.neo4j.server.webserver.address=0.0.0.0
в файле conf/neo4j-server.properties
Далее попробовал создать несколько нод:
CREATE (a:Country {name:'Украина'}),(b:Country {name:'Россия'}),(c:Country {name:'Беларусь'}),(d:Country {name:'Казахстан'})
я получил:
Added 3 labels, created 4 nodes, set 4 properties, statement executed in 664 ms.
Когда же я захотел связать страны соотношением ‘Border’, то есть указать какая с какой граничат, оказалось что в Neo4j отношение может быть только однонаправленным, но из базы можно делать выборки игнорируя направление. Пришлось смириться с этим и установить связи случайного направления:
MATCH (a:Country {name:'Украина'}),(b:Country {name:'Россия'}),(c:Country {name:'Казахстан'}),(d:Country {name:'Беларусь'}) CREATE (a)-[r:Border]->(b),(a)-[t:Border]->(d),(b)-[y:Border]->(c),(d)-[u:Border]->(b)
Здесь вначале в переменные a,b,c,d выбираются все нужные страны а затем между ними устанавливаются связи с меткой (Label) “Border”. Полюбоваться на получившуюся картину можно выбрав все связи “Border”
MATCH ()-[r:Border]-() RETURN r
либо все старны
MATCH (a:Country) RETURN a
После того как я упражняясь добавил еще несколько стран и связей между ними, уже можно было получить такую картинку:
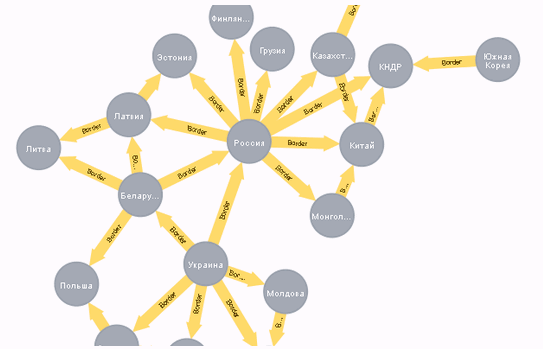
Стоит сказать что на графе связи хотя и притягивают связанные ноды, но все же часто размещаются не самым оптимальным способом, и если их подвигать вручную, то можно получить более удачное размещение, чем изначально.
Мне показалось, что встроенный визуализатор должен быть не единственным, и немного поискав я нашел еще несколько примеров визуализаций:
http://neo4j.com/developer/guide-data-visualization/#_presentation_svg_based_graph_interaction
Что интересно, связи тоже могут иметь свойства, как и ноды, но мне показалось не очень понятным ограничение на количество типов связей (по одному источнику 32768 а по другому 65536). В моей БД типы связей задавались самими нодами, что позволяло при надобности строить иерархии типов связей а также иметь гораздо больше их разновидностей.
Оболочка моей БД выглядела примерно так:
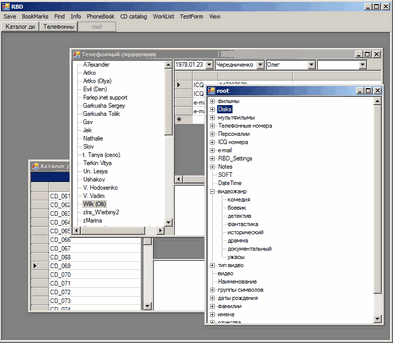
Там было общее дерево сущностей, а также отдельные формы для работы с некоторыми типами сущностей, как то персоналии (по сути телефонный справочник), каталог дисков. Все что угодно можно было посмотреть в виде списка либо дерева. Предполагалось что я в результате выработаю некую удобную форму хранения знаний, которые легко между собой переплетаются и не имеют четкой однородной структуры. Сейчас конечно я не думаю что обязательно было разрабатывать БД с нуля, а вполне можно было за основу взять Firebird, MySQL и реализовать механизм хранения/выборки нод и связей между ними в виде таблиц. Сейчас в одном из своих экспериментов я собственно так и делаю.